人脸检测——MTCNN
本次介绍一篇速度还不错的人脸检测文章:
《2016 Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks》.
源代码作者刚刚公布,效果相当不错(只有测试代码):
https://kpzhang93.github.io/MTCNN_face_detection_alignment/index.html?from=timeline&isappinstalled=1
另外一位同学实现的MTCNN基于MXNET的训练代码,工作比较完整,参考价值比较大: https://github.com/Seanlinx/mtcnn
———————————— Pipeline————————————
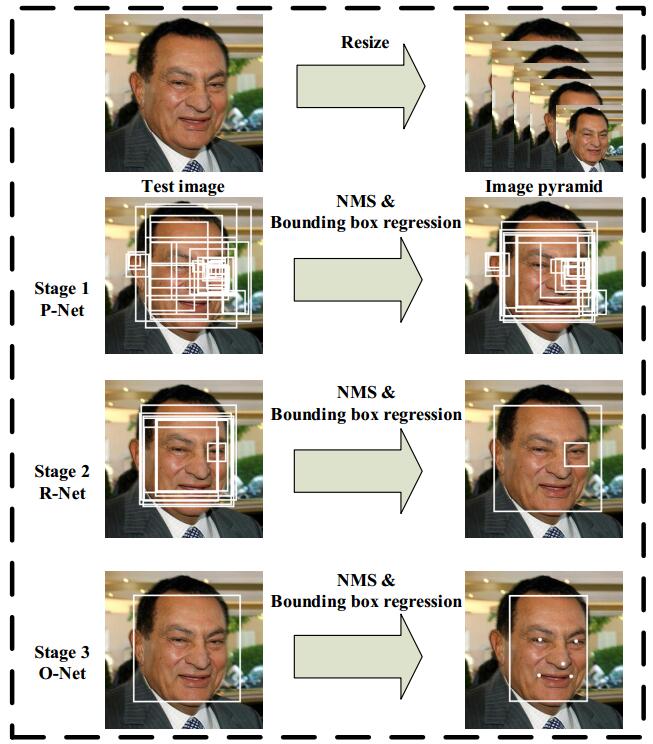
上面是该方法的流程图,可以看出也是三阶级联,和我之前的一篇博文CascadeCNN很像。
stage1: 在构建图像金字塔的基础上,利用fully convolutional network来进行检测,同时利用boundingbox regression 和 NMS来进行修正。(注意:这里的全卷积网络与R-CNN里面带反卷积的网络是不一样的,这里只是指只有卷积层,可以接受任意尺寸的输入,靠网络stride来自动完成滑窗)
stage2: 将通过stage1的所有窗口输入作进一步判断,同时也要做boundingbox regression 和 NMS。
stage3: 和stage2相似,只不过增加了更强的约束:5个人脸关键点。
———————————— Network ————————————
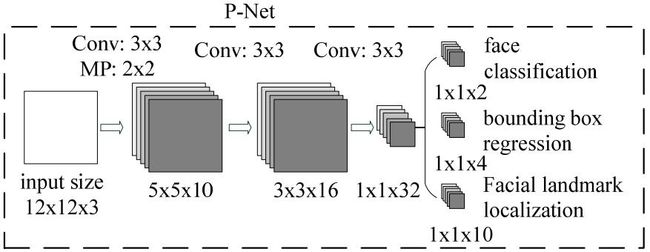
Stage1: Proposal Net
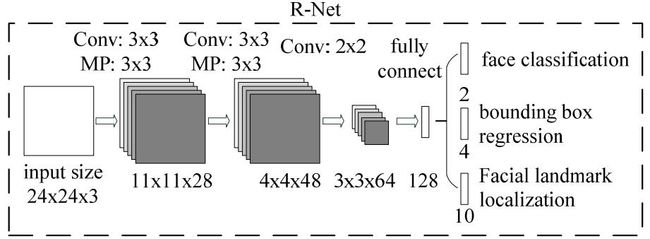
Stage2: Refine Net
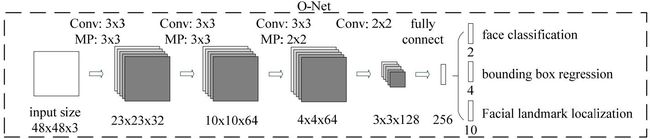
Stage3: Output Net
由上可以看出,其网络结构较CascadeCNN略深但每层参数较少,所以该方法性能较好同时速度和CascadeCNN也相差无几。
补充:
(1) 文中训练使用了Online Hard sample mining策略,即在一个batch中只选择loss占前70%的样本进行BP;
(2) 不同阶段,classifier、boundingbox regression 和 landmarks detection在计算Loss时的权重是不一样的;
(3) 训练数据共4类,比例3:1:1:2,分别是negative,IOU<0.3; positive,IOU>0.65; part face,0.4
———————————— Result ————————————
在FDDB上的表现:

速度表现,CPU约15FPS

该MTCNN算法出自深圳先进技术研究院,乔宇老师组,是今年2016的ECCV。(至少我知道的今年已经一篇cvpr,一篇eccv了)。
进入正题
理论基础:

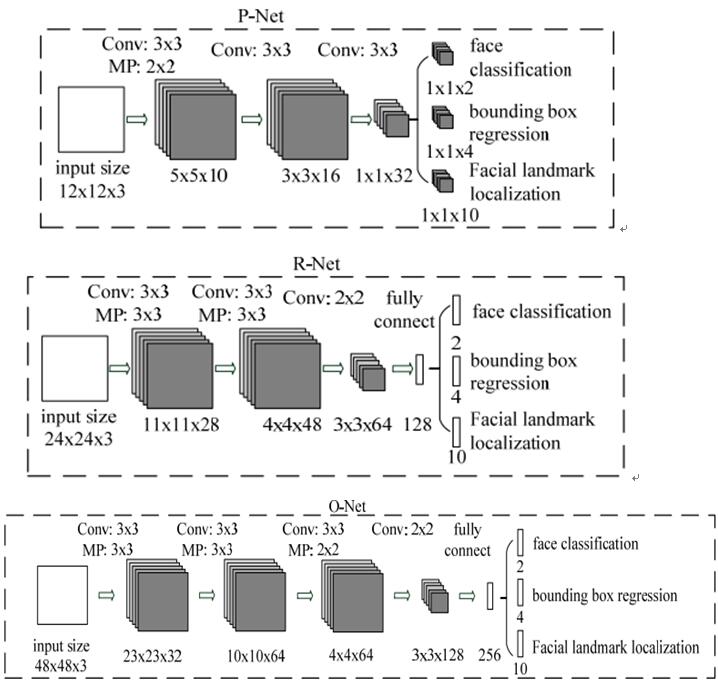
正如上图所示,该MTCNN由3个网络结构组成(P-Net,R-Net,O-Net)。
Proposal Network (P-Net):该网络结构主要获得了人脸区域的候选窗口和边界框的回归向量。并用该边界框做回归,对候选窗口进行校准,然后通过非极大值抑制(NMS)来合并高度重叠的候选框。
Refine Network (R-Net):该网络结构还是通过边界框回归和NMS来去掉那些false-positive区域。
只是由于该网络结构和P-Net网络结构有差异,多了一个全连接层,所以会取得更好的抑制false-positive的作用。
Output Network (O-Net):该层比R-Net层又多了一层卷基层,所以处理的结果会更加精细。作用和R-Net层作用一样。但是该层对人脸区域进行了更多的监督,同时还会输出5个地标(landmark)。
详细的网络结构如下图所示:
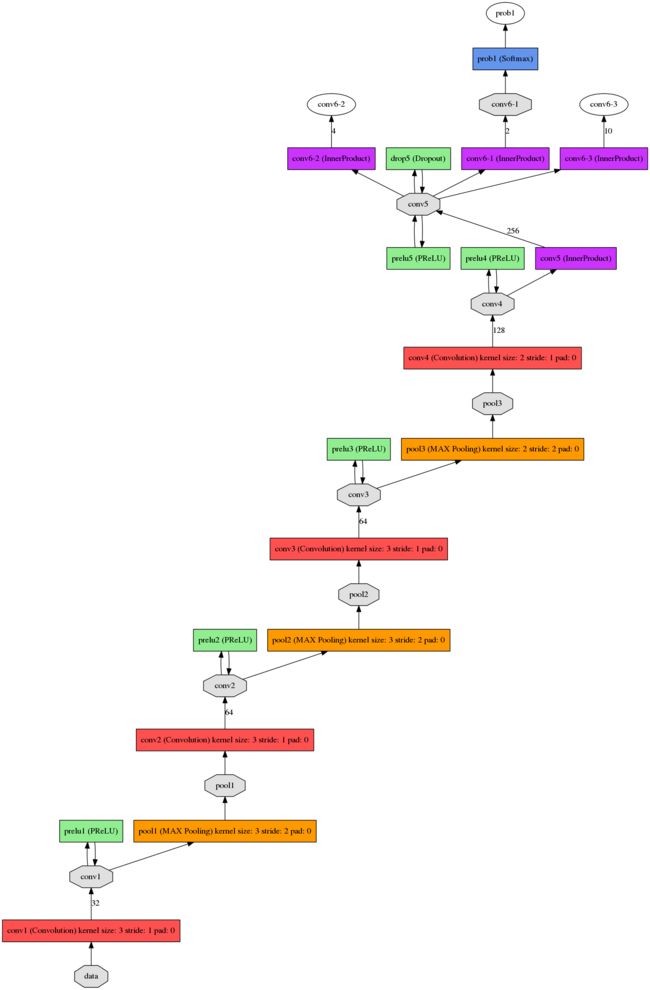
prototxt的更加详细的网络结构如下:分别为det1,det2,det3。
det1.prototxt结构:

det2.prototxt结构:

det3.prototxt结构:
训练:
MTCNN特征描述子主要包含3个部分,人脸/非人脸分类器,边界框回归,地标定位。
人脸分类:
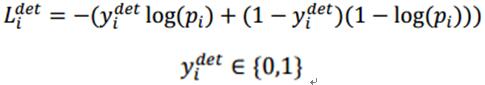
上式为人脸分类的交叉熵损失函数,其中,pi为是人脸的概率,yidet为背景的真实标签。
边界框回归:

上式为通过欧氏距离计算的回归损失。其中,带尖的y为通过网络预测得到,不带尖的y为实际的真实的背景坐标。其中,y为一个(左上角x,左上角y,长,宽)组成的四元组。
地标定位:

和边界回归一样,还是计算网络预测的地标位置和实际真实地标的欧式距离,并最小化该距离。其中,,带尖的y为通过网络预测得到,不带尖的y为实际的真实的地标坐标。由于一共5个点,每个点2个坐标,所以,y属于十元组。
多个输入源的训练:
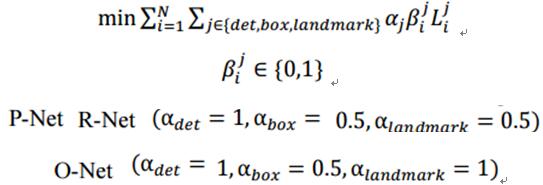
整个的训练学习过程就是最小化上面的这个函数,其中,N为训练样本数量,aj表示任务的重要性,bj为样本标签,Lj为上面的损失函数。
在训练过程中,为了取得更好的效果,作者每次只后向传播前70%样本的梯度,这样来保证传递的都是有效的数字。有点类似latent SVM,只是作者在实现上更加体现了深度学习的端到端。
在训练过程中,y尖和y的交并集IoU(Intersection-over-Union)比例:
0-0.3:非人脸
0.65-1.00:人脸
0.4-0.65:Part人脸
0.3-0.4:地标
训练样本的比例,负样本:正样本:part样本:地标=3:1:1:2
安装步骤:
caffe-windows的安装:
http://blog.csdn.net/qq_14845119/article/details/52415090
Pdollartoolbox的安装:
Pdollartoolbox 由 UCSD 的 Piotr Dollar 编写,侧重物体识别( Object Recognition )检测相关的特征提取和分类算法。这个工具箱属于专而精的类型,主要就是 Dollar 的几篇物体检测的论文的相关算法,如果做物体识别相关的研究,应该是很好用的。同时它的图像操作或矩阵操作函数也可以作为 Matlab 图像处理工具箱的补充,功能主要包括几个模块:
* channels模块 ,图像特征提取,包括 HOG 等, Dollar 的研究工作提出了一种 Channel Feature 的特征 [2] ,因此这个 channels 主要包括了提取这一特征需要的一些基本算法梯度、卷及等基本算法
* classify模块,一些快速的分类相关算法,包括random ferns, RBF functions, PCA等
* detector模块,与Channel Feature特征对应的检测算法1
* filters模块,一些常规的图像滤波器
* images模块,一些常规的图像、视频操作,有一些很实用的函数
* matlab模块,一些常规的Matlab函数,包括矩阵计算、显示、变量操作等,很实用
* videos模块,一些常规的视频操作函数等
下载链接:https://github.com/pdollar/toolbox
下载到Toolbox后,将其解压到任意目录下,如E:\MATLAB\MATLAB Production Server\toolbox
在Matlab命令行中输入
addpath(genpath(‘toolbox-masterROOT’));savepath;
将解压目录加入Matlab路径。其中toolbox-masterROOT为解压目录路径,如解压到E:\ MATLAB\MATLAB Production Server\toolbox时,则命令为
addpath(genpath(‘E:\ MATLAB\MATLAB ProductionServer\toolbox’)); savepath;
这样Piotr’s Image & VideoMatlab Toolbox就安装好了。
path里面加入caffe的库目录,例如本人的path加入如下的路径
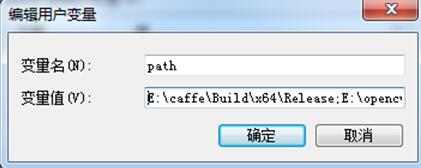
打开demo.m,修改其中的caffe_path,pdollar_toolbox_path,caffe_model_path
。同时由于本人电脑没有GPU,因此对其做如下修改。 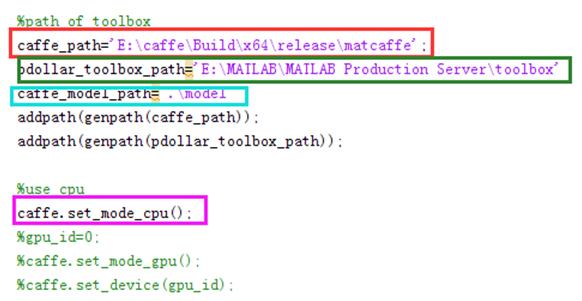
实验结果:
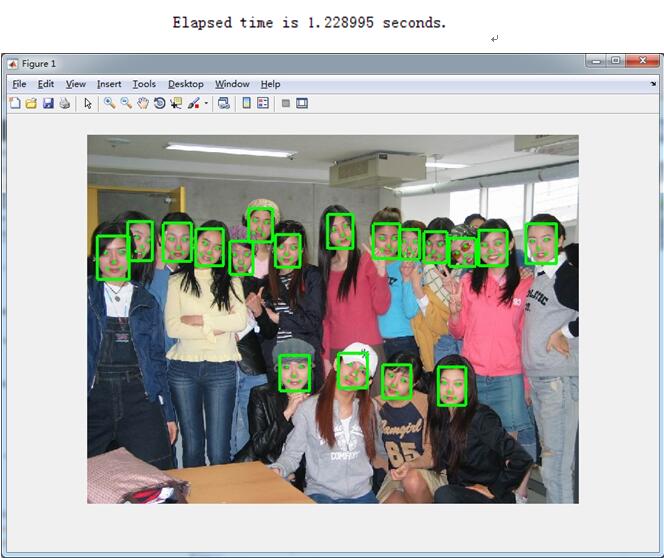
运行时间1.2S,按照检测出18个脸算,平均一个66MS,运行版本为release版本。从实验结果来看,不管是检测还是对齐都是空前的好。以我的经验来看,face++的对齐是最好的,剩下的开源的里面这篇MTCNN算是最好的了,然后才是SDM。
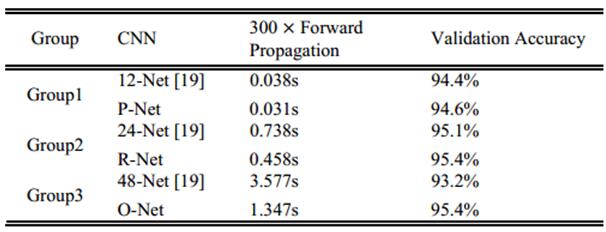
从下面的作者在FDDB+WIDERFACE+AFLW上验证的正确性来看,基本95%的准确度。可见该MTCNN的性能和效率都是很给力的。
从实验结果可以看出,上图的第二行的第二个对齐的出了问题,因此,本人对其程序进行了微小改动,实际运行效果如下图,时间和效果上都有了提升。
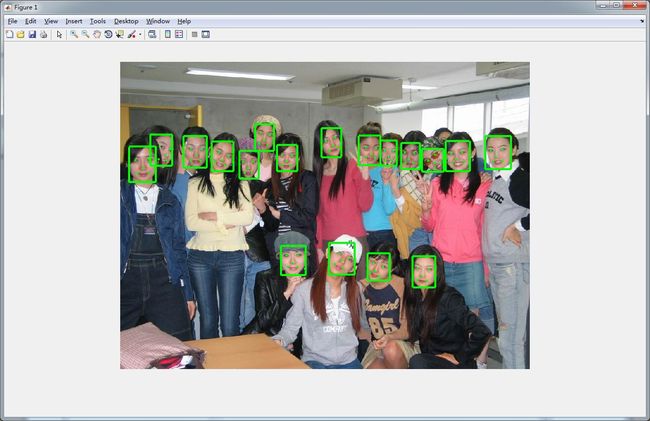
下载链接:http://download.csdn.net/detail/qq_14845119/9653138
组后感谢公司大牛的帮忙,C语言版本终于改出来了。老实说,真心不容易,走了好多坑。贴个效果图,纪念那些苦了笑了的时光。

References:
[1] https://kpzhang93.github.io/MTCNN_face_detection_alignment/index.html
[2] https://github.com/kpzhang93/MTCNN_face_detection_alignment/tree/master/code/codes
[3] ZhangK, Zhang Z, Li Z, et al. Joint Face Detection and Alignment using Multi-taskCascaded Convolutional Networks[J]. arXiv preprint arXiv:1604.02878, 2016.
实验
本文主要使用三个数据集进行训练:FDDB,Wider Face,AFLW。
A、训练数据
本文将数据分成4种:
Negative:非人脸
Positive:人脸
Part faces:部分人脸
Landmark face:标记好特征点的人脸
分别用于训练三种不同的任务。Negative和Positive用于人脸分类,positive和part faces用于bounding box regression,landmark face用于特征点定位。
B、效果
本文的人脸检测和人脸特征点定位的效果都非常好。关键是这个算法速度很快,在2.6GHZ的CPU上达到16fps,在Nvidia Titan达到99fps。
总结
本文使用一种级联的结构进行人脸检测和特征点检测,该方法速度快效果好,可以考虑在移动设备上使用。这种方法也是一种由粗到细的方法,和Viola-Jones的级联AdaBoost思路相似。
类似于Viola-Jones:1、如何选择待检测区域:图像金字塔+P-Net;2、如何提取目标特征:CNN;3、如何判断是不是指定目标:级联判断。
附录
在目标检测论文中,常出现的一些方法有Bounding box regression,IoU,NMS。这里具体介绍一下。
Bounding box regression
这边有个很好的答案了:
http://www.caffecn.cn/?/question/160
简单而言就是将预测的框移动到实际的框,输入特征是候选区域提取的特征,目标是两个框的变化值。
IoU
重叠度(IOU):
物体检测需要定位出物体的bounding box,就像下面的图片一样,我们不仅要定位出车辆的bounding box 我们还要识别出bounding box 里面的物体就是车辆。

对于bounding box的定位精度,有一个很重要的概念: 因为我们算法不可能百分百跟人工标注的数据完全匹配,因此就存在一个定位精度评价公式:IOU。 它定义了两个bounding box的重叠度,如下图所示
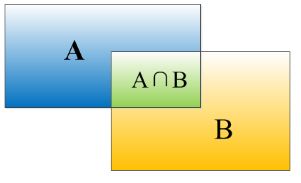
就是矩形框A、B的重叠面积占A、B并集的面积比例。
非极大值抑制(NMS):
RCNN会从一张图片中找出n个可能是物体的矩形框,然后为每个矩形框为做类别分类概率:

就像上面的图片一样,定位一个车辆,最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。非极大值抑制的方法是:先假设有6个矩形框,根据分类器的类别分类概率做排序,假设从小到大属于车辆的概率 分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
非极大值抑制(NMS)顾名思义就是抑制不是极大值的元素,搜索局部的极大值。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小。这里不讨论通用的NMS算法,而是用于在目标检测中用于提取分数最高的窗口的。例如在行人检测中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分数。但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况。这时就需要用到NMS来选取那些邻域里分数最高(是行人的概率最大),并且抑制那些分数低的窗口。