欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~
作者:段石石
导语: 本文讨论了CTR预估模型,包括工业界使用比较广的比较经典模型和学术界最新的结合DeepLearning的一些工作。
前言
谈到CTR,都多多少少有些了解,尤其在互联网广告这块,简而言之,就是给某个网络服务使用者推送一个广告,该广告被点击的概率,这个问题难度简单到街边算命随口告诉你今天适不适合娶亲、适不适合搬迁一样,也可以复杂到拿到各种诸如龟壳、铜钱等等家伙事,在沐浴更衣、净手煴香后,最后一通预测,发现完全扯淡,被人暴打一顿,更有甚者,在以前关系国家危亡、异或争国本这种情况时,也通常会算上一卦,国家的兴衰、。其实CTR和这个一样,以前经常和小伙伴吐槽,其实做机器学习、无论是推荐还是计算广告,都和以前的算命先生没什么差别,做的好的官至国师,不好的吃不了饱饭也是有的。要想把你CTR模型做的好好的,必须要先了解那些前辈们都是怎么玩的。
CTR架构
一个典型的CTR流程如下图所示:
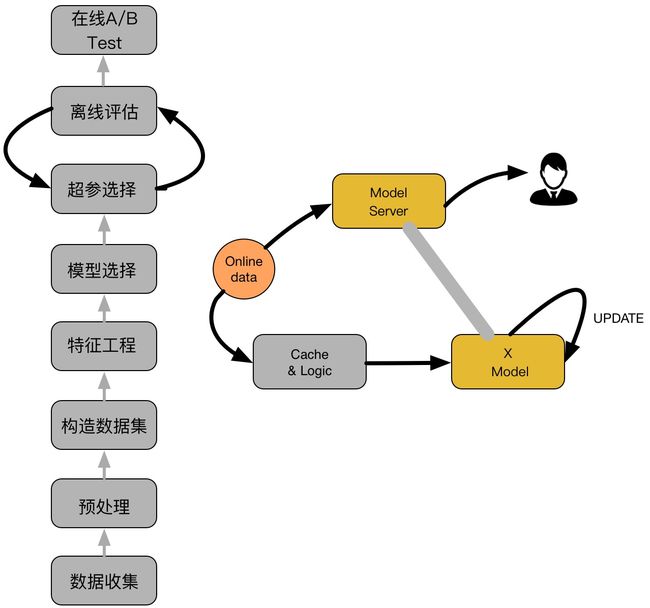
如上图,主要包括两大部分:离线部分、在线部分,其中离线部分目标主要是训练出可用模型,而在线部分则考虑模型上线后,性能可能随时间而出现下降,弱出现这种情况,可选择使用Online-Learning来在线更新模型:
离线部分:
- · 数据收集:主要收集和业务相关的数据,通常会有专门的同事在app位置进行埋点,拿到业务数据;
- · 预处理:对埋点拿到的业务数据进行去脏去重;
- · 构造数据集:经过预处理的业务数据,构造数据集,在切分训练、测试、验证集时应该合理根据业务逻辑来进行切分;
- · 特征工程:对原始数据进行基本的特征处理,包括去除相关性大的特征,离散变量one-hot,连续特征离散化等等;
- · 模型选择:选择合理的机器学习模型来完成相应工作,原则是先从简入深,先找到baseline,然后逐步优化;
- · 超参选择:利用gridsearch、randomsearch或者hyperopt来进行超参选择,选择在离线数据集中性能最好的超参组合;
- · 在线A/B Test:选择优化过后的模型和原先模型(如baseline)进行A/B Test,若性能有提升则替换原先模型;
在线部分
- · Cache & Logic:设定简单过滤规则,过滤异常数据;
- · 模型更新:当Cache & Logic收集到合适大小数据时,对模型进行pretrain+finetuning,若在测试集上比原始模型性能高,则更新model server的模型参数;
- · Model Server:接受数据请求,返回预测结果;
Logistic Regression
最简单的模型也应该是工业界应用最广的方法,Logistic Regression算法简单易于调参,属于线性模型,原理如下图:

将CTR模型建模为一个分类问题,利用LR预测用户点击的概率;通常我们只需要离线收集好数据样本构造数据集,选择好合适的特征空间,离线训练好模型,测试在离线数据集上的性能之后,即可上线,也可以适应数据分布随时间突变严重的情况,采用online-learning的策略来对模型进行相对频繁的更新,模型的简单能够保证这部分的需求能够得到保障。
PLOY2
LR优点是简单高效,缺点也很明显,它太简单,视特征空间内特征之间彼此独立,没有任何交叉或者组合关系,这与实际不符合,比如在预测是否会点击某件t恤是否会点击,如果在夏天可能大部分地区的用户都会点击,但是综合季节比如在秋天,北方城市可能完全不需要,所以这是从数据特征维度不同特征之间才能体现出来的。因此,必须复杂到能够建模非线性关系才能够比较准确地建模复杂的内在关系,而PLOY2就是通过特征的二项式组合来建模这类特征的复杂的内在关系,二项式部分如下图公式:
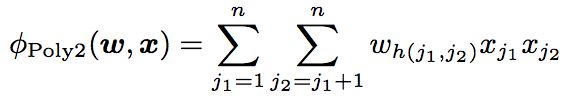
然而理想是美好的,现实却是残酷的,PLOY2有一个明显的问题,就是在实际场景中,大部分特征都是稀疏的,即大部分特征值为0,对这些稀疏的特征做二项式组合,会发现最后大部分特征值都是0,而在梯度更新时,当大部分feature为0时,其实梯度并不更新,所以PLOY2的方法在实际场景中并不能比较好地解决这类特征组合来建模更复杂线性关系的问题。
Factorization Machine
上面PLOY2虽然理论上能够建模二项式关系,但是在实际场景下稀疏数据时,无法使用,而FM就是为了解决这里PLOY2的短板的,FM的基本原理是将这些二项式矩阵做矩阵分解,将高维稀疏的特征向量映射到低维连续向量空间,然后根据内积表示二项式特征关系:
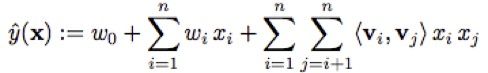
复杂度为$O(kn^2)$,作者提出了一种简化的算法:
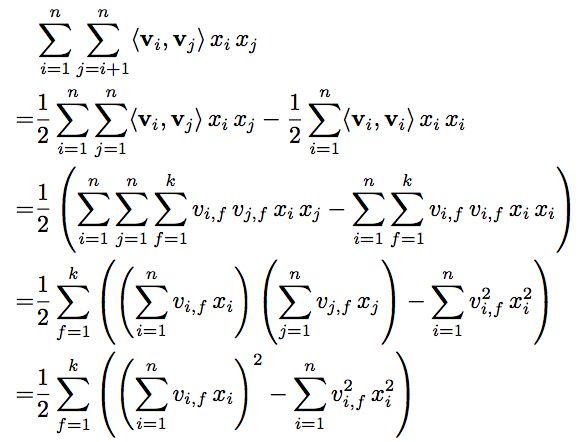
将复杂度简化为$O(kn)$ 然后就是SGD来更新模型参数,使模型收敛(这里还有很多其他替代SGD的方法,在FFM中有提到):
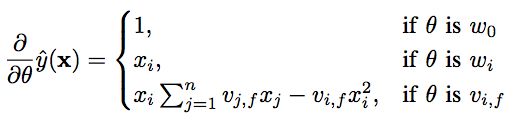
训练时间复杂度也是$O(kn)$,也就是线性时间,FM通过对二项式稀疏进行低维连续空间的转换,能够有效地解决PLOY2中存在的二次项系数在大规模系数数据下不更新的问题,另外由于训练预测复杂度均为线性,PLOY2+SVM这样逻辑下由于要计算多项式核,复杂度是n^2,由于FM的这几个特征,在实际场景中,FM也大规模的应用在CTR中,尤其是在数据极其系数的场景下,FM效果相对于其他算法有很明星的改善。
Field-aware FM
FMM全程是 Field-aware FactorizationMachine,相对于FM增加了Field信息,每个特征属于一个field,举个例子:

而相对于FM,只有Feature_index相同个数的低维连续表示,而FFM则不同,每一个feature对不同的field有不同的表示,所以有#Field_index*#Feature_index个不同的表示:
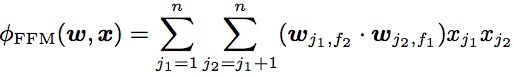
通常由于每个低维隐变量表示只学习特定field的表示,所以FFM的隐变量长度相对于FM的隐变量维度要小的多。FFM的优化问题相对其比较简单,可以看看FFM这篇paper,里面比较详细地描述优化过程,还有相关的伪代码
https://www.andrew.cmu.edu/user/yongzhua/conferences/ffm.pdf。
FNN
从12年在ImageNet上深度学习超过经典模型之后,在计算机视觉、语音、NLP都有很多相关的工作,而在CTR上,深度学习的建模能力也有一些应用,FNN和SNN就是其中的一些尝试,来源于Deep Learning over Multi-field Categorical Data – A Case Study on User Response Prediction,这里稍微描述下相关的做法:

网络底层由FM来进行参数初始化,W的元素由FM中的低维连续空间向量表示来做初始化:
![]()
而构成W的低维连续空间向量表示预先由FM在数据集上生成,模型在训练过程中,会通过BP来更新FM层参数,其他步骤和常见的MLP没有什么区别,这里重点就是底层如何介入FM层参数的问题;
CCPM
CCPM利用卷积网络来做点击率预测,看了文章,没有太明白其中的所以然,贴下网络结构的图吧:
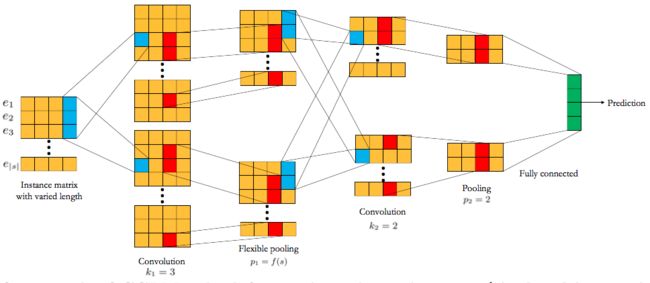
有弄清楚这篇文章的小伙伴可以讨论下。
PNN
PNN主要是在深度学习网络中增加了一个inner/outer product layer,用来建模特征之前的关系,如下图,Product layer部分Z是weightfeature,P部分weightI(feature_i,feature_j)用来建模二项式关系:

PNN按product层的功能分为inner product layer和outer product layer,区别如下:
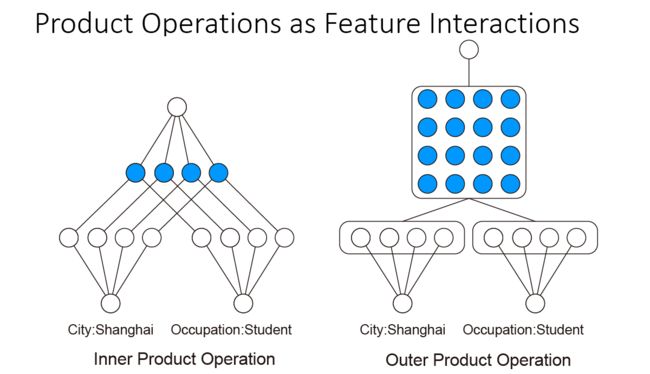
和FM类似,构造好网络之后,对输入数据做embedding处理之后得到低维的连续向量表示,经过任意两个feature的进行inner product or outer product(1也为feature的一部分,所以可以建模线性关系),这里很容易发现,这部分特征大小会变大很多(二次项数量级),尤其是稀疏空间,和PLOY2遇到的问题类似,变得很难训练,受FM启发,可以把这个大矩阵转换矩阵分解为小矩阵和它的转置相乘,表征到低维度连续向量空间,来减少模型复杂度:
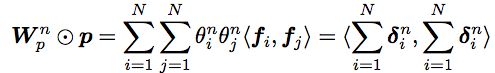
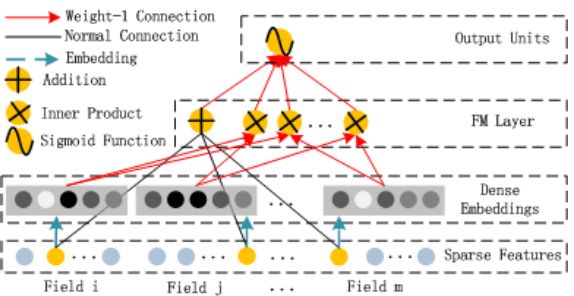
DeepFM
DeepFM更有意思的地方是WDL和FM结合了,其实就是把PNN和WDL结合了,PNN即将FM用神经网络的方式构造了一遍,作为wide的补充,原始的Wide and Deep,Wide的部分只是LR,构造线性关系,Deep部分建模更高阶的关系,所以在Wide and Deep中还需要做一些特征的东西,如Cross Column的工作,而我们知道FM是可以建模二阶关系达到Cross column的效果,DeepFM就是把FM和NN结合,无需再对特征做诸如Cross Column的工作了,这个是我感觉最吸引人的地方,其实FM的部分感觉就是PNN的一次描述,这里只描述下结构图,PNN的部分前面都描述, FM部分:
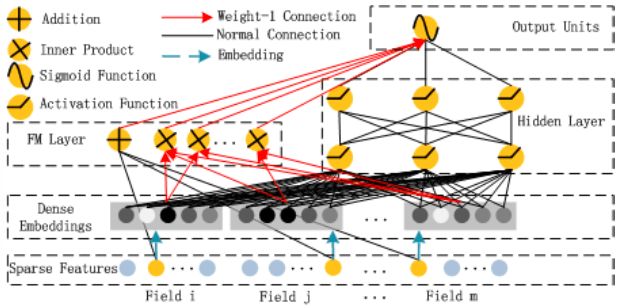
Deep部分:

DeepFM相对于FNN、PNN,能够利用其Deep部分建模更高阶信息(二阶以上),而相对于Wide and Deep能够减少特征工程的部分工作,wide部分类似FM建模一、二阶特征间关系,算是NN和FM的一个更完美的结合方向,另外不同的是如下图,DeepFM的wide和deep部分共享embedding向量空间,wide和deep均可以更新embedding部分,虽说wide部分纯是PNN的工作,但感觉还是蛮有意思的。
其他的一些方法
-
GBDT+LR:Facebook提出利用GBDT探索海量特征空间的特征组合,减少特征工程工作量,性能很好;
-
MLR:阿里妈妈前端时间提出的一种增强LR模型,将region的划分考虑进去来建模非线性关系,感觉类似于深度学习的Attention机制,据说在阿里妈妈相关业务提升很多;
总结
前面讨论了一些CTR常见的方法,重点介绍了Factorization Machine及其变种Field-Aware Factorization Machine,还有和深度学习的结合,个人感觉PNN的逻辑比较有意思,完全使用神经网络的思维模型重塑了FM,为后面DeepFM扩展wide and deep的工作打下基础,减少了wide and deep中需要的一些基本的特征工程工作(wide部分二次项工作),上面只是涉及到模型的算法部分,在实际中可以去探讨,并不能说明一定性能就好,另外由于架构的限制,综合考虑其他方面的因素,如请求时间、模型复杂度,也是最终是否采用相关算法的考虑因素,各位对此有兴趣讨论的小伙伴,欢迎回复讨论。
相关阅读
FEC 的介绍
机器学习优化算法:梯度下降(Gradient Descent)
机器学习优化算法:牛顿法 ( Newton Method )
此文已由作者授权腾讯云技术社区发布,转载请注明文章出处
原文链接:https://cloud.tencent.com/community/article/205108