转载请注明出处:https://www.cnblogs.com/shining5/p/11142357.html
MongoDB监控及报警
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库,其使用go语言开发。基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应HTTP接口就可以接入监控。Prometheus服务端产生告警向Altermanager发送告警。
Grafana是一个开源的度量分析和可视化套件,常用于可视化基础设施和应用程序分析的时间序列数据。
监控
目标:可视化显示MongoDB的运行状态。
工具:Grafana,Prometheus
因为grafana本身数据源没有mongodb,所以中间加上Prometheus来对mongodb进行监控。
服务端组件:
Prometheus #服务端
Grafana #前端展示
客户端组件:
node_exporter
mongodb_exporter
步骤
安装go环境
$ yum install go
$ go version
go version go1.6.3 linux/amd64安装Prometheus
$ wget https://github.com/prometheus/prometheus/releases/download/v2.11.0-rc.0/prometheus-2.11.0-rc.0.linux-amd64.tar.gz
$ tar xvf prometheus-2.11.0-rc.0.linux-amd64.tar.gz -C /usr/local/
$ ln -sv /usr/local/prometheus-2.11.0.linux-amd64/ /usr/local/prometheus
$ cd /usr/local/prometheus
备注:下载2.0以上版本,否则读取规则的时候报错
修改配置文件
将监管的ip地址添加到prometheus.yml中
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'mongo1'
static_configs:
- targets: ['10.13.72.26:9001']
- job_name: 'node'
static_configs:
- targets: ['10.13.72.26:9100']
其中'10.13.72.26:9001'是mongodb_exporter监听端口,后面安装mongodb_exporter会提到
启动服务
nohup ./prometheus --web.enable-lifecycle &
备注:启动时添加–web.enable-lifecycle可以自动加载配置文件,可以通过 curl -X POST http://localhost:9090/-/reload 重新加载配置
prometheus内置列一个web界面,可以通过http://install_host:9090访问。在Status->Targets页面中,我们可以看到配置的mongo1,状态为Down,说明未检测到数据。如何解决呢?需要安装好node_exporter,mongodb_exporter状态才会变为Up

安装node_exporter
node_exporter服务端agent,用go语言编写,主要用于采集系统数据,如cup,内存,负载,磁盘,网络等信息。
启动后监听9100端口。
$ wget https://github.com/prometheus/node_exporter/releases/download/v0.14.0/node_exporter-0.14.0.linux-amd64.tar.gz
$ tar xvf node_exporter-0.14.0.linux-amd64.tar.gz -C /usr/local/
$ nohup /usr/local/node_exporter-0.14.0.linux-amd64/node_exporter &安装mongodb_exporter
wget https://github.com/dcu/mongodb_exporter/releases/mongodb_exporter-linux-amd64
nohup ./mongodb_exporter-linux-amd64启动后占用9001端口
安装grafana
wget https://dl.grafana.com/oss/release/grafana-6.2.5-1.x86_64.rpm
sudo yum localinstall grafana-6.2.5-1.x86_64.rpm 启动后默认占用3000端口
sudo service grafana-server start
grafana显示mongodb数据
步骤1: 打开grafana前端页面http://install_host:3000
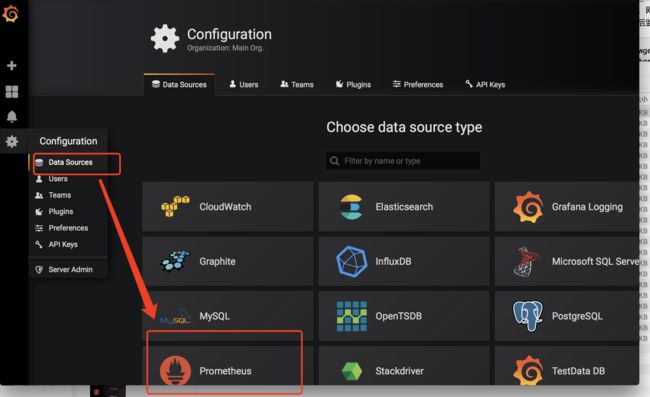
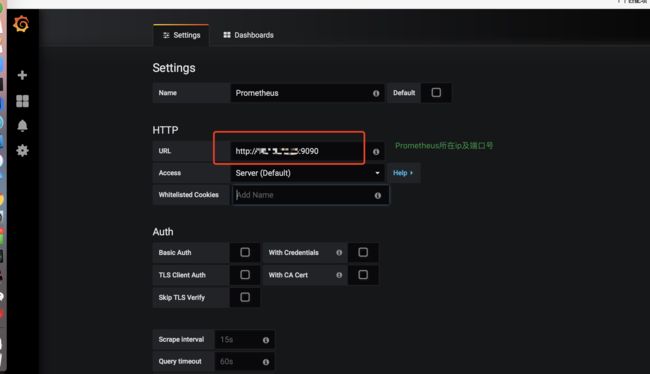
步骤2:在Data Sources添加数据源
步骤3: Create dashboard
import一个已经做好的表盘
https://grafana.com/dashboards/2583
DownloadJSON
improt此表盘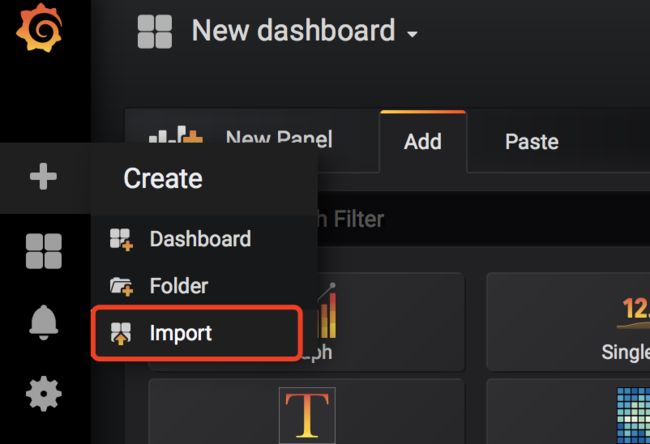


效果图

报警
Prometheus的报警分为两部分,通过在Prometheus服务端设置告警规则,Prometheus服务端产生报警向Alertmanager发送报警。Alertmanager管理这些报警,通过电子邮件,PagerDuty和HipChat等方法发送通知。
设置报警及通知的步骤:
* 配置Alertmanager
* 配置Prometheus对Alertmanager访问
* 配置ruler报警规则
我们的需求是能将报警信息发送到企业微信中。
* 注册企业微信账号(不需要企业认证)
* 创建第三方应用如Prometheus,填写应用信息(此应用的配置信息用于altermanager.yml配置及接收报警信息)
下载Alertmanager
wget https://github.com/prometheus/alertmanager/releases/download/v0.18.0-rc.0/alertmanager-0.18.0-rc.0.linux-amd64.tar.gz
tar -xzvf alertmanager-0.18.0-rc.0.linux-amd64.tar.gz
创建或修改alertmanager.yml
global:
resolve_timeout: 2m
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
route:
group_by: ['alertname_wechat']
group_wait: 10s
group_interval: 10s
receiver: 'wechat'
repeat_interval: 1h
receivers:
- name: 'wechat'
wechat_configs:
- send_resolved: true
to_party: '1'
agent_id: '1000002'
corp_id: 'w***'
api_secret: 'W***'参数说明:
- corp_id: 企业微信账号唯一 ID, 可以在我的企业中查看。
- to_party: 需要发送的组。
- agent_id: 第三方企业应用的 ID(上面步骤创建的应用),可以在自己创建的第三方企业应用详情页面查看。
- api_secret: 第三方企业应用的密钥,可以在自己创建的第三方企业应用详情页面查看
启动altermanager
nohup ./altermanager &
修改prometheus配置文件
增加如下配置
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
rule_files:
- "rules.yml"创建rules.yml文件
groups:
- name: node
rules:
- alert: server_status
expr: up{job="node"} == 0
for: 15s
annotations:
summary: "机器挂了"停止node_explorer,企业微信就会收到消息
备注:起初困扰我的是如何设置rules,后来发现Prometheus的前端页面可以直接执行query,将规则设置好后,可以在页面中执行,如图:

规则配置
磁盘占用规则:node_filesystem_avail{device="/dev/sde1",fstype="ext3",instance="hostip:9100",job="node",mountpoint="/data4"} < 1073741824 (1G)
磁盘使用率:(1- (node_filesystem_free{fstype=~"ext3|ext4|xfs",mountpoint="/data4"} / node_filesystem_size{fstype=~"ext3|ext4|xfs",mountpoint="/data4"}) ) * 100
数据同步:
进程存在
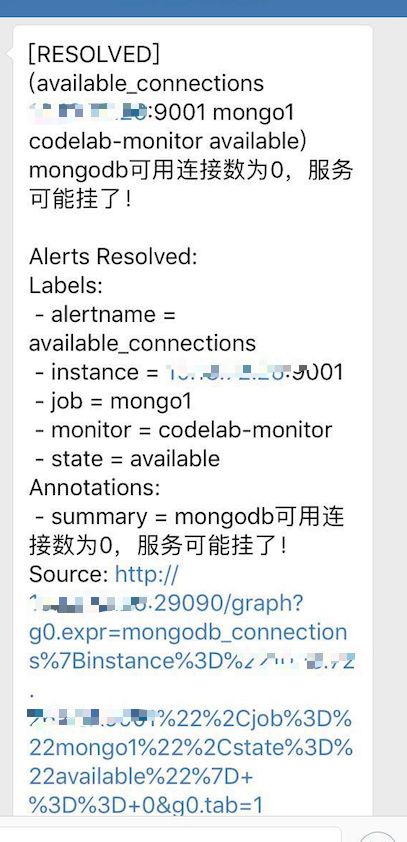
mongodb_connections{instance="hostip:9001",job="mongo1",state="available"}==0
内存使用率:
((node_memory_MemTotal - (node_memory_MemFree+node_memory_Buffers+node_memory_Cached))/node_memory_MemTotal) * 100
cpu使用率
(100 - (avg by (instance)(irate(node_cpu{mode="idle"}[5m])) * 100))
使用promtool验证规则是否准确
./promtool check rules alert_rule_test.yml
报警信息
如图