脉冲神经网络2: SNN的仿真介绍
SNN仿真器说明
仿真器使用STDP算法学习了网络的最佳权重,用于图片分类。仿真器使用“赢家通吃”策略来抑制非发放神经元产生分类结果。分类模式时涉及的步骤是:
- 对于每个输入,神经元膜电位在其感受野(5×5窗口)中计算
- 对于每个输入神经元生成脉冲序列,产生脉冲频率与膜电位成比例
- 对于每个图像,在每个时间步长,根据输入脉冲和相关权重更新神经元的电位
- 第一个发放输出神经元对其余的输出神经元进行横向抑制
- 仿真器检查输出脉冲
1.1 感受野
感受野是刺激导致特定感觉神经元反应的区域。在SNN的情况下,其中输入是图像,感知神经元的感受野是图像的增加其膜电位的部分。这里使用了中心(on center)感受野。
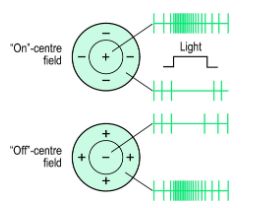
为了实现中心感受野,使用滑动窗口,其窗格根据窗口中心的[曼哈顿距离](https://xlinux.nist.gov/dads/HTML/manhattanDistance.html)进行加权。不同神经元的场是重叠的。
2. 产生脉冲序列
输入神经元层必须通过其感受野引起的刺激。从滑动窗口计算出的刺激是一个模拟值,必须转换成脉冲序列,以便神经元能够理解它。该编码器用作数字数据(来自物理世界,数字模拟等)和SNN之间的接口。它使信息转换为人工神经元脉冲。这里采用的编码类型是速率编码。它表明信息是由神经元的发放速率。因此,产生的脉冲序列具有与相应的膜电位成比例的频率。
视网膜神经节神经元的平均发放速率在1-200Hz之间,因此需要以一定的比例缩放。以下是不同发放速率的一些例子

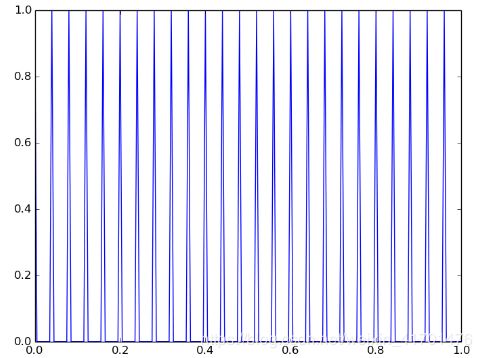
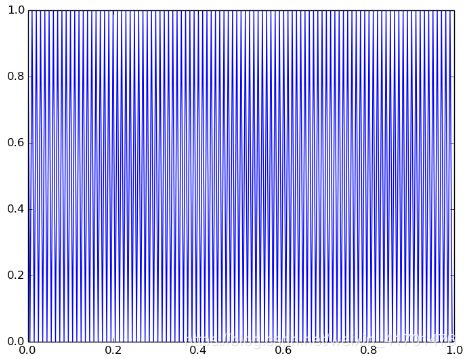
输入的图像是手写整数的[semeion数据集](https://archive.ics.uci.edu/ml/machine-learning-databases/semeion/)中的图像
3.实例演示
3.1 二分类数据
仿真器在二元分类中进行测试。它可以扩展到任意数量的类。两个类的图像是:

每个类在1000个时间单位的发送给网络。记录神经元的活动。以下是输出神经元与时间单位的电位图
首先1000个时间单位对应于class1,接下来1000时间单位对应class2。红线表示阈值电位。
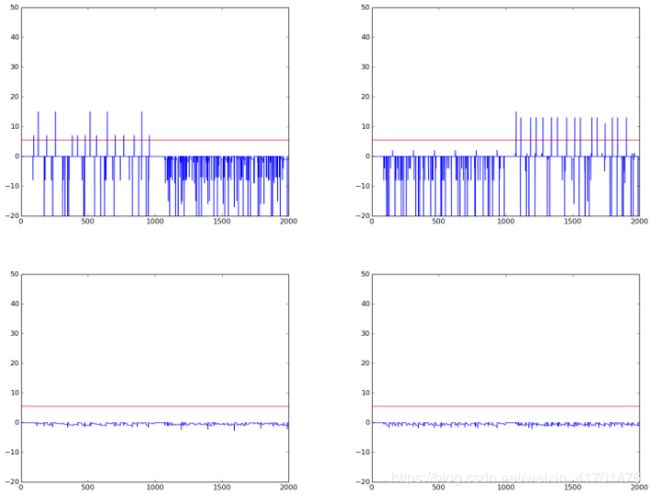
第1个输出神经元对class1有效,2nd对class2有效,第3和第4对这两个类都不发放。因此,通过记录输出神经元中的总脉冲值,我们可以确定模式所属的类。
3.2 多分类数据
此外,为了证明多类分类的结果,在以下6个图像(MNIST数据集)上测试仿真器。

每个图像代表一个类,每个类都与一个神经元相对应。为2个神经元随机分配权重。以下是每个神经元对所有类别的反应。X轴是类号,Y轴是每次模拟时的脉冲数。红色条代表它发放最多的数目。

4.训练SNN
在上一节中,我们假设我们的网络是经过训练的,即使用STDP学习权重,并可用于对模式进行分类。在这里,我们将看到STDP如何工作以及在实施此训练算法时需要注意的事项
4.1 Spike Time Dependent Plasticity
STDP实际上是大脑用来修改它的神经连接(突触)的生物过程。由于几十年来大脑的无与伦比的学习效率得到了认可,因此该规则被纳入人工神经网络以训练神经网络。权重的塑造基于以下两条规则 -
- 任何有助于发生突触后神经元发放的突触都应该增强,即它的权重增加
- 应该减少对突触后神经元发放没有贡献的突触,即它的权重应该降低
以下是该算法如何工作的解释:请考虑此图中描述的场景

四个神经元通过突触连接到单个神经元。每个突触前神经元以其自身的速率发射脉冲,并且脉冲由相应的突触向前发送。转化为突触后神经元的膜电位,取决于连接突触的强度。现在,由于输入脉冲,突触后神经元的膜电位增加,并在超过阈值后发出脉冲。在突触后神经元突然出现时脉冲,我们将监测所有突触前神经元。这可以通过观察哪些突触前神经元,在突触后神经元发放之前发出脉冲。这样他们通过增加膜电位帮助突触后脉冲,因此相应的突触得到加强。突触的重量增加的因子与该图给出的突触后突触和突触前脉冲之间的时间差成反比。

4.2 SNN的生成属性
脉冲神经网络的这一特性在分析训练过程中非常有用。连接到输出层神经元的所有突触,如果缩放到适当的值并以图像的形式重新排列,则描绘神经元已经学习到的模式以及它可以如何分类图片。例如,在训练具有MNIST数据集的网络之后,如果我们缩放连接到特定输出神经元(数量为784)的所有突触的权重,并形成具有那些按比例放大的权重的28x28图像,我们将获神经元学习到的灰度模式。稍后将在演示结果时使用此属性。此文件包含从权重重建图像的功能。
4.3 侧向抑制
在神经生物学中,侧向抑制是受激神经元降低其邻近神经元的活动力。侧向抑制使得在横向方向上激发的神经元向邻近神经元的动作电位的传播失效。这在刺激中产生对比度,允许增加感官知觉。这个性质也被称为Winner-Takes-All(WTA)。被激发的神经元首先抑制同一层中其他神经元的(降低膜电位)。
5. 训练3类数据集
以下是使用具有5个输出神经元的3类(0-2)的MNIST数据集训练SNN之后的结果。我们将利用SNN的生成属性,并使用连接到每个输出神经元的训练权重来重建图像,以查看网络学习每个模式的程度。此外,我们还可以看到每个输出神经元的膜电位与时间的关系曲线,以了解训练过程是如何执行的,并使神经元仅对特定模式敏感。


在这里我们可以清楚地看到神经元1已经学习模式'1',神经元2已经学习'0',神经元3是学习了噪声,神经元4已经学习'2'。考虑神经元1的情节。在开始时,权重是随机分配的,它是针对所有模式进行的。随着训练的进行,它仅对模式“1”具体化,其余部分处于抑制状态。观察神经元3我们可以认为它对所有模式都有反应并且可以被认为是噪声。因此,建议输出神经元数量比类别数多20%。
“2”和“0”略有重叠,这是竞争性学习中的常见问题。这可以消除适当的参数微调。
6. Improper training
如果我们不使用变量阈值进行归一化,我们将观察一些模式而不是影响其他模式。这是一个例子:

这里,两个模式使用相同的阈值电压,因此导致重叠。通过选择每个图像具有或多或少相同激活次数的数据集或者标准化激活次数,可以避免这种情况。
7.Parameters
- Learning Rate
- Threshold Potential
- Weight Initialization
- Number of Spikes Per Sample
- Range of Weights