【深度学习图像识别课程】tensorflow迁移学习系列:VGG16花朵分类
一、VGGNet
1、VGGNet介绍
通常,我们不会自己训练大型的神经网络,ImageNet(http://www.image-net.org/)上已经有很多训练数周的模型。这里,我们使用预训练模型VGGNet进行花朵图像(图像库来自Tensorflow Inception tutorial)分类。
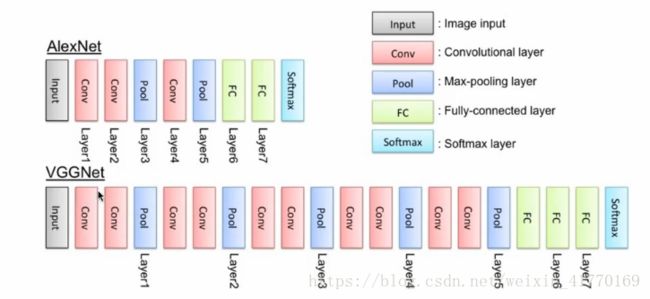
VGG论文:
http://www.robots.ox.ac.uk/~vgg/research/very_deep/
https://arxiv.org/pdf/1409.1556.pdf
2、程序包安装
写代码前,先打开Ananconda Prompt安装2个程序包tqdm和scikit-image:
pip install tqdm
conda install scikit-image
3、花朵数据库介绍
种类5种:daisy雏菊,dandelion蒲公英,rose玫瑰,sunflower向日葵,tulips郁金香
数量: 633, 898, 641, 699, 799
总数量:3670
二、实战:VGGNet实现花朵分类
1、读入VGG16模型
from urllib.request import urlretrieve
from os.path import isfile, isdir
from tqdm import tqdm
vgg_dir = 'tensorflow_vgg/'
# Make sure vgg exists
if not isdir(vgg_dir):
raise Exception("VGG directory doesn't exist!")
class DLProgress(tqdm):
last_block = 0
def hook(self, block_num=1, block_size=1, total_size=None):
self.total = total_size
self.update((block_num - self.last_block) * block_size)
self.last_block = block_num
if not isfile(vgg_dir + "vgg16.npy"):
with DLProgress(unit='B', unit_scale=True, miniters=1, desc='VGG16 Parameters') as pbar:
urlretrieve(
'https://s3.amazonaws.com/content.udacity-data.com/nd101/vgg16.npy',
vgg_dir + 'vgg16.npy',
pbar.hook)
else:
print("Parameter file already exists!")下载了如下标亮文件:vgg16.npy

2、读入图像库
import tarfile
dataset_folder_path = 'flower_photos'
class DLProgress(tqdm):
last_block = 0
def hook(self, block_num=1, block_size=1, total_size=None):
self.total = total_size
self.update((block_num - self.last_block) * block_size)
self.last_block = block_num
if not isfile('flower_photos.tar.gz'):
with DLProgress(unit='B', unit_scale=True, miniters=1, desc='Flowers Dataset') as pbar:
urlretrieve(
'http://download.tensorflow.org/example_images/flower_photos.tgz',
'flower_photos.tar.gz',
pbar.hook)
if not isdir(dataset_folder_path):
with tarfile.open('flower_photos.tar.gz') as tar:
tar.extractall()
tar.close()
![]()
下载如下高亮文件:flower_photos.tar.gz
3、卷积代码
参考的源码:
self.conv1_1 = self.conv_layer(bgr, "conv1_1")
self.conv1_2 = self.conv_layer(self.conv1_1, "conv1_2")
self.pool1 = self.max_pool(self.conv1_2, 'pool1')
self.conv2_1 = self.conv_layer(self.pool1, "conv2_1")
self.conv2_2 = self.conv_layer(self.conv2_1, "conv2_2")
self.pool2 = self.max_pool(self.conv2_2, 'pool2')
self.conv3_1 = self.conv_layer(self.pool2, "conv3_1")
self.conv3_2 = self.conv_layer(self.conv3_1, "conv3_2")
self.conv3_3 = self.conv_layer(self.conv3_2, "conv3_3")
self.pool3 = self.max_pool(self.conv3_3, 'pool3')
self.conv4_1 = self.conv_layer(self.pool3, "conv4_1")
self.conv4_2 = self.conv_layer(self.conv4_1, "conv4_2")
self.conv4_3 = self.conv_layer(self.conv4_2, "conv4_3")
self.pool4 = self.max_pool(self.conv4_3, 'pool4')
self.conv5_1 = self.conv_layer(self.pool4, "conv5_1")
self.conv5_2 = self.conv_layer(self.conv5_1, "conv5_2")
self.conv5_3 = self.conv_layer(self.conv5_2, "conv5_3")
self.pool5 = self.max_pool(self.conv5_3, 'pool5')
self.fc6 = self.fc_layer(self.pool5, "fc6")
self.relu6 = tf.nn.relu(self.fc6)
with tf.Session() as sess:
vgg = vgg16.Vgg16()
input_ = tf.placeholder(tf.float32, [None, 224, 224, 3])
with tf.name_scope("content_vgg"):
vgg.build(input_)
feed_dict = {input_: images}
codes = sess.run(vgg.relu6, feed_dict=feed_dict)tensorflow中vgg_16采用的上述结构。本项目代码如下:
import os
import numpy as np
import tensorflow as tf
from tensorflow_vgg import vgg16
from tensorflow_vgg import utilsdata_dir = 'flower_photos/'
contents = os.listdir(data_dir)
classes = [each for each in contents if os.path.isdir(data_dir + each)]将图像批量batches通过VGG模型,将输出作为新的输入:
# Set the batch size higher if you can fit in in your GPU memory
batch_size = 10
codes_list = []
labels = []
batch = []
codes = None
with tf.Session() as sess:
vgg = vgg16.Vgg16()
input_ = tf.placeholder(tf.float32, [None, 224, 224, 3])
with tf.name_scope("content_vgg"):
vgg.build(input_)
for each in classes:
print("Starting {} images".format(each))
class_path = data_dir + each
files = os.listdir(class_path)
for ii, file in enumerate(files, 1):
# Add images to the current batch
# utils.load_image crops the input images for us, from the center
img = utils.load_image(os.path.join(class_path, file))
batch.append(img.reshape((1, 224, 224, 3)))
labels.append(each)
# Running the batch through the network to get the codes
if ii % batch_size == 0 or ii == len(files):
images = np.concatenate(batch)
feed_dict = {input_: images}
codes_batch = sess.run(vgg.relu6, feed_dict=feed_dict)
# Here I'm building an array of the codes
if codes is None:
codes = codes_batch
else:
codes = np.concatenate((codes, codes_batch))
# Reset to start building the next batch
batch = []
print('{} images processed'.format(ii))
4、模型建立和测试
图像处理代码和标签:
# read codes and labels from file
import csv
with open('labels') as f:
reader = csv.reader(f, delimiter='\n')
labels = np.array([each for each in reader if len(each) > 0]).squeeze()
with open('codes') as f:
codes = np.fromfile(f, dtype=np.float32)
codes = codes.reshape((len(labels), -1))4.1 图像预处理
from sklearn.preprocessing import LabelBinarizer
lb = LabelBinarizer()
lb.fit(labels)
labels_vecs = lb.transform(labels)对标签进行one-hot编码:daisy雏菊 dandelion蒲公英 rose玫瑰 sunflower向日葵 tulips郁金香
daisy雏菊 1 0 0 0 0
dandelion蒲公英 0 1 0 0 0
rose玫瑰 0 0 1 0 0
sunflower向日葵 0 0 0 1 0
tulips郁金香 0 0 0 0 1
随机拆分数据集(之前那种直接把集中的部分图像拿出来验证/测试不管用,这里的数据集是每个种类集中放的,如果直接拿出其中的一部分,会导致验证集或者测试集是同一种花)。scikit-learn中的函数StratifiedShuffleSplit可以做到。我们这里,随机拿出20%的图像用来验证和测试,然后验证集和测试集再各占一半。
from sklearn.model_selection import StratifiedShuffleSplit
ss = StratifiedShuffleSplit(n_splits=1, test_size=0.2)
train_idx, val_idx = next(ss.split(codes, labels))
half_val_len = int(len(val_idx)/2)
val_idx, test_idx = val_idx[:half_val_len], val_idx[half_val_len:]
train_x, train_y = codes[train_idx], labels_vecs[train_idx]
val_x, val_y = codes[val_idx], labels_vecs[val_idx]
test_x, test_y = codes[test_idx], labels_vecs[test_idx]print("Train shapes (x, y):", train_x.shape, train_y.shape)
print("Validation shapes (x, y):", val_x.shape, val_y.shape)
print("Test shapes (x, y):", test_x.shape, test_y.shape)
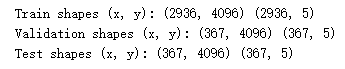
总数量:3670,则训练图像:3670*0.8=2936,验证图像:3670*0.2*0.5=367,测试图像:3670*0.2*0.5=367。
4.2 层
在上述vgg的基础上,增加一个256个元素的全连接层,最后加上一个softmax层,计算交叉熵进行最后的分类。
inputs_ = tf.placeholder(tf.float32, shape=[None, codes.shape[1]])
labels_ = tf.placeholder(tf.int64, shape=[None, labels_vecs.shape[1]])
fc = tf.contrib.layers.fully_connected(inputs_, 256)
logits = tf.contrib.layers.fully_connected(fc, labels_vecs.shape[1], activation_fn=None)
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=labels_, logits=logits)
cost = tf.reduce_mean(cross_entropy)
optimizer = tf.train.AdamOptimizer().minimize(cost)
predicted = tf.nn.softmax(logits)
correct_pred = tf.equal(tf.argmax(predicted, 1), tf.argmax(labels_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
4.3 训练:batches和epoches
def get_batches(x, y, n_batches=10):
""" Return a generator that yields batches from arrays x and y. """
batch_size = len(x)//n_batches
for ii in range(0, n_batches*batch_size, batch_size):
# If we're not on the last batch, grab data with size batch_size
if ii != (n_batches-1)*batch_size:
X, Y = x[ii: ii+batch_size], y[ii: ii+batch_size]
# On the last batch, grab the rest of the data
else:
X, Y = x[ii:], y[ii:]
# I love generators
yield X, Yepochs = 10
iteration = 0
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for e in range(epochs):
for x, y in get_batches(train_x, train_y):
feed = {inputs_: x,
labels_: y}
loss, _ = sess.run([cost, optimizer], feed_dict=feed)
print("Epoch: {}/{}".format(e+1, epochs),
"Iteration: {}".format(iteration),
"Training loss: {:.5f}".format(loss))
iteration += 1
if iteration % 5 == 0:
feed = {inputs_: val_x,
labels_: val_y}
val_acc = sess.run(accuracy, feed_dict=feed)
print("Epoch: {}/{}".format(e, epochs),
"Iteration: {}".format(iteration),
"Validation Acc: {:.4f}".format(val_acc))
saver.save(sess, "checkpoints/flowers.ckpt")
![]()
验证集的正确率达到90%,很高了已经。
4.4 测试
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint('checkpoints'))
feed = {inputs_: test_x,
labels_: test_y}
test_acc = sess.run(accuracy, feed_dict=feed)
print("Test accuracy: {:.4f}".format(test_acc))![]()
%matplotlib inline
import matplotlib.pyplot as plt
from scipy.ndimage import imreadtest_img_path = 'flower_photos/roses/10894627425_ec76bbc757_n.jpg'
test_img = imread(test_img_path)
plt.imshow(test_img)
with tf.Session() as sess:
input_ = tf.placeholder(tf.float32, [None, 224, 224, 3])
vgg = vgg16.Vgg16()
vgg.build(input_)
with tf.Session() as sess:
img = utils.load_image(test_img_path)
img = img.reshape((1, 224, 224, 3))
feed_dict = {input_: img}
code = sess.run(vgg.relu6, feed_dict=feed_dict)
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint('checkpoints'))
feed = {inputs_: code}
prediction = sess.run(predicted, feed_dict=feed).squeeze()plt.imshow(test_img)
plt.barh(np.arange(5), prediction)
_ = plt.yticks(np.arange(5), lb.classes_)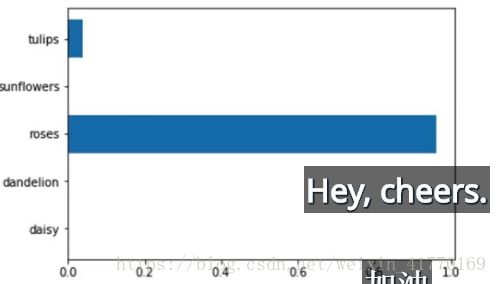
上图的花最有可能是Rose,有小概率是Tulips。