数据分析面试题整理(自用)
数据提取问题
1.Hadoop、Hive、Spark之间的关系
- Hadoop:
管理横跨成百上千台机器的大量数据。(底层) - MapReduce(通用、强壮、保守)/Tez/Spark:
如何分配工作,机器之间如何通信交换数据以完成复杂的计算。(中间)
Map阶段:几百台机器同时读取文件的各个部分,分别把读到的部分分别统计出词频,类似(hello,12100次)
Reduce阶段:将统计结果再次进行汇总,类似(hello,12100)+(hello,12311)+(hello,345881)= (hello,370292次) - Hive:
把脚本和SQL语言翻译成MapReduce程序(上层)
2.数据量大了,无法在线分析
构建Hadoop集群,把文件导入到集群上面去。
3.分析结果数据量太大,无法在线请求
一般几十万的数据,mysql无任何压力。数据量千万或亿万级别,同时有复杂的sql。需要构建缩影(用空间换时间)或用分布式的内存服务器来完成查询(用更快的存储来抗请求)
4.离线分析有时间差,实时的话怎么搞
在数据库的机器上安装一个类似JMS的程序,监听binlog的变更,收到日志信息,转化为具体的数据,然后以消息的形式发送出来。要一个storm集群接收他,然后按照指定的规则进行逻辑合并等计算,将计算结果保存在数据库中
5.数据库的选择
传统的关系型数据库Mysql和Oracle,如果数据离散分布较强,且根据特定的Key查询,可选择HBase
6.提到如何处理数据多源问题?
可以重构模式以完成模式集成,也可以标识类似的记录,并将他们合并到包含所有相关属性的单个记录中,避免冗余。
数据存储问题
1.数据产生的结果如何搞到线上提供服务的数据库中
使用开源的datax,实现异构数据的导入和导出,采用插件的形式设计,能够支持未来的数据源。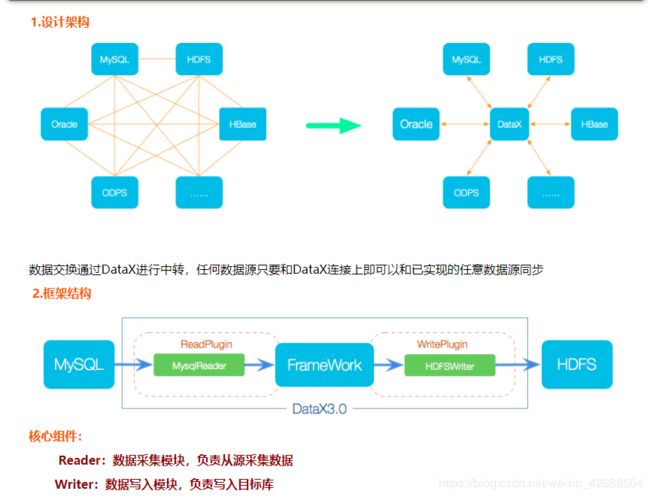
数据处理问题
1.缺失值处理,哪种插补方法更有利?
个案剔除法:把有缺失值对应的个案从分析中剔除。
均值替换法:若缺失值是数值型的用所有值的平均值来填充该缺失的变量值,非数值型的取众数
热卡填充法:使用相关系数矩阵确定哪个变量(Y)与缺失值(X)最相关,然后将Y进行排序,缺失的X用排在Y前面的一个X代替。
回归替换法:用期望来填充缺失的变量值
多重替代法:估计出待插补的值,然后再加上不同的噪声形成多组可选插补值,根据某种选择依据,选取最合适的插补值。
2.如何处理缺失数据
首先判断缺失数据是否有意义
如果没有意义或者超过80%,直接去掉
如果数据有规律,找规律。
数据符合正态分布,缺失值用期望值代替
数据是类型变量,默认类型值代替缺失值
3.描述通常观察到的值缺失的模式是什么?
通常是被忽略的模式是完全随机缺失、随机缺失、取决于缺失值的值本身、取决于未观察到的输入变量
4.如何处理可疑或缺失数据?
1.准备一份提供所有可疑数据信息的验证报告。它应该提供,失败的验证标准以及发生的日期和时间信息
2.有经验的人员应检查可疑数据以确定其可接受性
3.应该分配无效数据,并用验证代码替换
4.对于缺失的数据,可以采用最好的分析策略,如删除法,单一归位法,基于模型的方法等
5.什么是异常值?
出现在样本中且偏离总体模式的值。有两种类型的异常值:单变量异常值和多元变量异常值。
6.异常值
先计算样本之间的距离。每次将距离最近的点合并到同一个类。然后,再计算类与类之间的距离,将距离最近的类合并为一个大类。不停的合并,直到合成了一个类。
聚集法是先将所有研究对象都各自算作一类,将最“靠近”的首先进行聚类,再将这个类和其他类中最“靠近”的结合,这样继续合并直至所有对象都综合成一类或满足一个闽值条件为止
分割法正好相反,先将所有对象看成一大类,然后割成两类,使一类中的对象尽可能地“远离”另一类的对象;再将每一类继续这样分割下去,直至每个对象都自成一类或满足一个阂值条件为止。
7.数据清理的最佳实践
1.完整性:数据是否存在空值、统计字段是否完善
2.全面性:用常识判断该列是否有问题
3.唯一性:是否存在重复数据
8.你平时都是怎么做数据清洗的?
- 去除/补全有缺失的数据
- 去除/修改格式和内容错误的数据
格式不一致或存在非法字符或者内容与字段不一致 - 去除/修改逻辑错误的数据
去重或不合理值或矛盾内容 - 去除不需要的数据
9.数据清洗的技巧
- 1.根据不同的属性对数据排列
- 2.对于大型数据集,可以逐步对其进行清理,改进数据质量,直到符合期望
- 3.为了提高迭代速度,将大数据集分解成小数据
- 4.对于常见的清洗任务,创建函数/脚本
- 5.如果清洁度有问题,按估计的频率排列,并解决最常见的问题
- 6.从统计指标入手,分析每个列的汇总统计信息,标准差、均值、缺失值等。
- 7.跟踪每个日期清理操作,以便在需要时更改或删除操作
数据分析问题
1.空间的数据如何分析
空间数据如经纬度使用geohash算法,将经纬度转换成一个可比较、可排序的字符串的算法,然后在空间距离方面进行分析
2.如何避免过拟合
1.正则化2.增大数据集
3.数据分析师使用的数据验证的方法
数据筛选和数据验证。
4.如何利用Scikit包训练一个简单的线性回归模型
regr = linear_model.LinearRegression()
regr.fit(data_X_train,data_y_train)
5.例举几个常用的python分析数据包及其作用
数据处理和分析:numpy , scipy , pandas
机器学习:Scikit
可视化:Matplotlib,seaborn
6.如何利用Numpy对数列的前n项进行排序
x[x[:n-1].argsort()]
7.如何检验一个数据集或者时间序列是随机分布的
画 lag plot 如果图上的点呈散乱分布则说明随机
8.在python中如何创建包含不同类型数据的dateframe
df = pd.DataFrame({‘x’: pd.Series([‘1.0’, ‘2.0’, ‘3.0’], dtype=float), ‘y’: pd.Series([‘1’, ‘2’, ‘3’], dtype=int)})
9.描述numpy array比python list的优势
numpy array 比python list更紧凑,存储空间小,读写速度快。
10.如何检验numpy的array为空?
a.size
11.如何检验pandas的dataframe为空?
empty方法
12.如何在python中复制对象
copy:浅复制,在原数据块上打标签,原数据变化跟着变化
deepcopy:深复制,被复制的对象作为独立的新个体,原数据变化不变
13.PEP8是什么
python语言的编程规范,提高代码可读性
14.init.py是什么
在文件夹中包含一个__init__.py,python就会把文件夹当作一个package,里面的py文件就可以在外面被import了。
15.如何对list中的item进行随机重排
import random
random.shuffle(list)
16.python中用于发现bug的工具
pylint:可以检验模块是否满足所有的编程标准
pychecker:静态分析工具
17.装饰器的作用
装饰函数或类。可以包裹函数或类,使之执行之前或之后调用装饰器函数,从而达到 抽出大量函数中与函数功能本身无关的雷同代码 并继续重用的目的。
18.以下代码的输出
def multipliers():
return [lambda x: i * x for i in range(4)]
print [m(2) for m in multipliers()]
输出[6,6,6,6],无论哪个返回的函数被调用,for循环都完成了,i的值为3,每个返回的函数multiplies的值都是3。
19.以下代码是否报错
list= [‘a’,’e’,’i’,’o’,’u’]
print list [8:]
输出空列表,不会报错
20.以下代码的输出
def foo (i= []):
i.append (1)
return i
foo ()
foo ()
输出为[1],[1,1]
算法问题
1.介绍一下Logistic regression算法
2.描述K-Means Clustering算法
3.介绍一下K-means算法
- 原理:1.随机抽取k个中心点2.然后计算各个数据对象到各类聚类中心的距离,把数据对象归到离他最近的那个聚类中心所在的类。3.调整后新类计算新的聚类中心4.如果相邻两次的聚类中心没有任何变化,说明数据对象调整结束,聚类准则函数f已经收敛。
- 改进:1.kmeans++:初始随机点选择尽可能远,避免陷入局部解。
2.mini batch kmeans:每次只用一个子集做重入类并找到类心
3.ISODATA:对于难以确定K的时候,使用。当类下的样本小时,剔除。类下样本数量多时,拆分。
4.kernel kmeans:kmeans用欧氏距离计算相似度,也可以使用kernel映射到高维空间再聚类 - 遇到异常值:1.局部异常因子LOF:若点P的密度明显小于其邻域点的密度,点P可能为异常值。2.多元高斯分布异常点检测3.使用PCA或自动编码机进行异常点检测:使用降维后的维度作为新的特征空间。4.isolation
forest:基本思路是建立树模型,一个节点所在的树越低,说明其从样本空间划分出去越容易,越可能是异常值。5.winsorize:对于简单的,可以对单一维度做上下截取 - 评估聚类算法的指标:1.外部法(有标注):Jaccard系数、纯度2.内部法(无标注):内平方和WSS和外平方和BSS3.时间复杂度、空间复杂度、聚类稳定性。
4.解释层次聚类算法
5.描述对于聚类的理解,聚类算法有哪些特性?
6.介绍一下朴素贝叶斯算法
7.逻辑回归与聚类的区别
1.聚类是无监督学习的结果,回归是有监督学习
2.聚类的结果将产生一组集合,回归的结果是连续的,得到的是一条回归曲线。
8.解释KNN插补法
通过使用与其缺失值的属性最相似的属性来推断缺少的属性值。通过使用距离函数确定两个属性的相似度
9.协同过滤
基于用户的协同过滤:根据所有用户对物品或者信息的偏好,为当前用户进行推荐
基于物品的协同过滤:根据它使用所有用户对物品或者信息的偏好,发现物品和物品之间的相似度,根据用户的历史偏好信息,把类似的物品推荐给用户
基于模型的协同过滤:此时我们要用已有的部分稀疏数据来预测那些空白的物品和数据之间的评分关系,找到最高评分的物品推荐给用户。
10.解释时间序列
在时间序列分析中,可以通过指数平滑,对数线性回归等各种方法分析数据,来预测特定过程输出。
11.解释空间自相关分析
空间自相关分析的目的是确定某一变量是否在空间上相关,其相关程度如何
12.解释聚类,聚类算法的属性
聚类分析是无监督学习,就是把相似的东西聚到一起。
聚类算法的优劣判断。
13.解释N-gram
N-gram是一种语言模型。它的第一特点是某个词的出现依赖于其他若干词,第二个特点是我们获得的信息越多,预测越准。
14.随机森林原理?有哪些随机方法?
原理:通过构造多个决策树,做bagging以提高泛化能力
随机方法:subsample(有放回抽样)、subfeature、低维空间投影
15.PCA
定义:是一种降维的方法,思想是将样本从原来的特征空间转化到新的特征空间,并且样本在新特征空间坐标轴上的投影方差尽可能大,这样就能覆盖样本最主要的信息。可看成激活函数为线性函数的自动编码机。
方法:1.特征归一化 2.求样本特征的协方差矩阵A 3.求A的特征值和特征向量 4.将特征值从小到大排列,选择TopK,对应的特征向量就是新的坐标轴
16.XGBOOST
17.NVL函数
oracle的一个函数,NVL(string1,replace_with),如果string1为NULL,则NVL函数返回replace_with的值,否则返回原来的值。
18.LR
19.分类算法性能的主要评价指标
1.查准率、查全率、F1 2.AUC 3.LOSS 4.Gain和Lift 5.WOE和IV
20.roc图
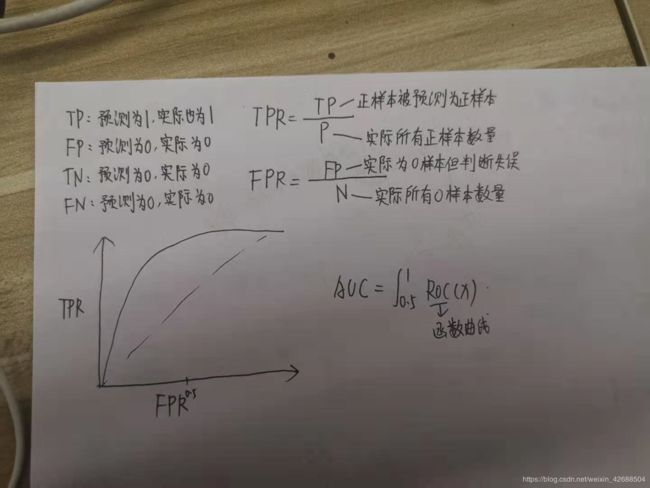
21.查准率查全率
查准率:TP/(TP+FP)
查全率:TP/(TP+FN)
22.欧氏距离
表示m维空间中两个点的真实距离。
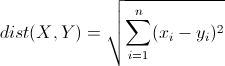
23.GBDT原理
24.推荐系统、协同过滤
25.P值的意义
决定假设检验的结果是否显著
26.监督学习和非监督学习,机器学习算法
监督学习:有特征,有标签。给定数据,预测标签。
无监督学习:只有特征,没有标签。给定数据,找出隐藏结构
机器学习:
分类算法:C4.5,朴素贝叶斯,SVM,KNN,Adaboost,CART
聚类算法:K-Means,EM
关联分析:Apriori
连接分析:PageRank
27.特征值和特征向量
特征向量:用于确定之后的线性转换的方向
特征值:特征向量方向转化或者压缩的强度
28.如何评价一个逻辑斯蒂模型
用分类矩阵查看真阴性和假阳性
一致性:查看logistic模型区分事件是否发生的能力
与随机选择模型进行对比
29.什么是时间序列分析?
时间序列分析可分为频域分析和时域分析。在时间序列中,利用指数平滑法、对数线性回归法等多种方法通过对已有数据的分析,可以对特定过程的输出进行预测。
30.什么是相关图分析?
是地理学中常见的空间分析形式。由一系列为不同空间关系计算的估计自相关系数组成。当原始数据表示为距离而不是单个点的值时,可以用它来构造基于距离的数据相关图。
理论问题
1.分析项目的各个步骤
- 明确问题:
明确问题类型(分类/聚类/回归)
分类:C4.5,朴素贝叶斯,SVN, KNN, Adaboost, CART
聚类:K-Means EM
关联:Apriori
回归:PageRank - 获取数据:
1.可获取什么样的数据
2.需要获取什么样的数据 - 特征预处理与特征选择:
1.归一化、离散化、因子化、缺失值处理(删、插)、去除共线性等数据处理手段
2.如相关系数、卡方检验、平均互信息、条件熵、后验概率、逻辑回归权重等特征选择方法。 - 模型建立:
选择和应用各种数据挖掘模型,并进行优化,以便得到更好的分类结果。 - 模型评估:
1.过拟合、欠拟合判断。
2.误差分析
常见的方法如交叉验证,绘制学习曲线等
过拟合的基本调优思路是增加数据量,降低模型复杂度。
欠拟合的基本调优思路是提高特征数量和质量,增加模型复杂度。 - 模型融合
- 上线运行
2.对数据分析师有用的统计方法
- 贝叶斯方法
- 马尔科夫过程
- 空间和集群进程 ·
- 统计数据,百分位数,异常值检测
- 计算技巧等 ·
- 简单的算法 ·
- 数学优化
3.数据挖掘和数据分析之间的区别?
数据分析:针对个别属性的实例分析。
数据挖掘:重点关注聚类分析,异常记录检测,依赖关系,序列发现,多个属性之间的关系控制等。
4.数据分析师与数据工程师的区别在哪里?
数据分析师:一般用数据工程师提供的现成的接口来抽取新的数据,然后取发现数据中的趋势。同时也要分析异常情况。
数据工程师:数据工程师主要工作在后端。持续的提升数据管道来保证数据的精确和可获取。
5.海量日志数据,提取某日访问百度次数最多的IP
1.Hash:Hash(IP)%1024,相同IP肯定会放到一个文件中,不同IP也可能放到同一个文件中。
2.对于每一个小文件,构建一个IP为key,出现次数为value的Hash Map,同时记录value最大的那个IP地址。
3.可以得到1024个小文件中出现次数最多的IP,再依据常规的排序算法得出总体上出现次数最多的IP.
6.如何从10亿数据中找到前1000大的数?
1.对数据预处理,用hash表(时间复杂度为O(N))
2.利用最小堆找出Top(K)(进行一次排序之后最小的肯定在最上面,再把它归位,拉下来)
7.有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
1.遍历文件,hash(x)%2000,然后再把文件分别存放,如果某个文件超过1MB,用同样的方法继续分解下去。
2.统计每个文件中出现频率最高的词,用字典,如果有+1.如果没有把这个词存入字典中,key为这个词,值为1
3.遍历第一个文件,把第一个文件中的top10构成最小堆,继续遍历,用新词替换旧词。
8.在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数。
用位图。一个字节占8个bit,int是4个字节,32个bit。一个原占32bit的数据现在只占1bit.
9.给定a,b两个文件,各存放50亿个url,每个url各占64个字节,内存限制为4G,找出a,b文件共同的url
(645010^8)/1000000000=32G
先在A中hash分成1000个文件,再在B中hash分成1000个文件(虽然一个文件中可能有多个url,但是url相同的都被分到了同一个文件中)然后把a存起来,再从b中找,是否有这个值,如果有就是共同的url.
10.给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在40亿个数当中
把40个亿分成两类,最高位为0,最高位为1.
又分为两类,时间复杂度O(logn)
11.A/B测试
定义:可以为同一个优化目标制定两个方案,一部分用户用A方案,一部分用B方案,统计对比不同的转化率、点击量、留存率等指标以判断不同方案的优劣并进行决策,从而提升转化率。
使用场景:影响大、选择难
最佳的实践流程:1.确立优化目标2.分析数据3.提出想法4.重要性排序5.实施A/B测试并分析实验结果6.迭代整个流程
12.KPI,实验设计和80/20规则
KPI:关键绩效指标,是关于业务流程的报告或图标
实验设计:用于分解数据,采样和建立数据以进行统计分析的初始过程
80/20规则:80%的产出源自20%的投入;80%的结论源自20%的起因;80%的收获源自20%的努力。
13.什么是hash表?什么是hash冲突?如何避免
定义:把任意长度的输入通过散列算法变换成固定长度的输出。
hash冲突:两个不同对象的hashcode相同
避免:
开放定址法(线性探测再散列:顺序查看下一个单元;二次探测再散列:表的左右进行跳跃式探测;伪随机探测再散列:建立一个伪随机数发生器,并给一个随机数作为起点)容易序列化
再哈希法(构造多个hash函数,产生冲突时计算另一个hash函数的值)
链地址法(将hash地址相同的都链接在同一个链表中,插入查找和删除主要在同义词链中进行)
建立公共溢出区(凡是和基本表发生冲突的元素一律填入溢出表。)
14.Linux基本命令
- 1)目录操作:ls、cd、mkdir、find、locate、whereis等
- 2)文件操作:mv、cp、rm、touch、cat、more、less
- 3)权限操作:chmod+rwx421
- 4)账号操作:su、whoami、last、who、w、id、groups等
- 5)查看系统:history、top
- 6)关机重启:shutdown、reboot
- 7)vim操作:i、w、w!、q、q!、wq等
15.SQL中null和’ '的区别?
null表示空,没有分配地址,找不到的,用is null判断;’ ‘表示空字符串,用=’ '判断
16.数据库与数据仓库的区别?
1.数据仓库是由多个数据库以一种方式组织起来的
2.数据库强调范式,尽可能减少冗余;数据仓库强调查询分析的速度,优化读取操作,快速做大量数据的查询
3.数据库会覆盖;数据仓库定期写入数据,不覆盖,给数据加上时间戳标签
4.数据库行存储;数据仓库列存储
5.数据库面向事务,存储在线交易数据;数据仓库面向主题、集成、相对稳定、反应历史变化存储历史数据
6.数据仓库的两个基本元素为维表(看待问题的角度)和事实表(要查询的数据)
17.sql的数据类型
- 1)字符串:char、varchar、text
- 2)二进制串:binary、varbinary
- 3)布尔类型:boolean
- 4)数值类型:integer、smallint、bigint、decimal、numeric、float、real、double
- 5)时间类型:date、time、timestamp、interval
18.C的数据类型
- 基本类型:整数类型:char、unsigned char、signed char、int、unsigned
int、short、unsigned short、long、unsigned long - 浮点类型:float、double、long double
- void类型
- 指针类型
- 构造类型:数组、结构体struct、共用体union、枚举类型enum
19.内连接与外连接的区别
1.内连接:左右表取匹配行2.外连接:左连接、右连接、全连接
20.如何证明根号2是无理数
假设√2是有理数,那么可以写成m/n的形式,且m和n互质,√2=m/n,因此m=√2n,m²=2n²,所以m必须为偶数,可以设m=2k,从而4k²=2n²,n=2k²,所以n也为偶数,因此m和n不互质,假设不成立。
21.数据分析中常用的统计方法?
贝叶斯方法、马尔可夫过程、空间和聚类过程、排序统计、百分位数、异常值检验、归责技术、单纯形法、数学优化。
22.什么是哈希表?
是键到值的映射,用于实现关联数组的数据结构,使用哈希函数将索引计算到槽数组中,从中可以获取所需的值。
23.什么是哈希表冲突?如何避免?
当两个不同的键哈希到相同的值时,就会发生哈希表冲突。数组中的两个数据不能存储再同一个槽中。解决方法是:独立的链接和开放寻址。
一个好的数据模型的标准是什么?
容易被消费;大型数据更改可伸缩;可预测性良好以适应需求的变化
开放性回答
1.数据分析都用哪些工具?
mysql(sql server )+tableau+python+Xmind
2.你认为数据分析师应该具备哪些能力?
理解数据库
掌握数据整理、可视化和报表制作
懂设计
专业技能(统计学+社会学+财务管理知识+心理学概况)
提升个人能力
随时贴近数据文化
3.你对自己的职业定位是怎样的?
公司层面:本身技术过硬,还要具备管理能力,将工作产品化 。
行业层面:成为这个行业的推动者,帮助企业做数据治理,辅助并指导企业的数字化转型,提供知识体系搭建的过程。
4.你的优点和缺点是什么?
5.请举例说明自己参与的一个数据分析项目(star法则)
S:某大型印刷公司,人力资源记录分散,很多由手工记录,容易出错,且人员流失率比较高,招聘成本较高
T:1.确定人员组成和分布情况2.将数据集中到一起3.列出造成员工离职的影响因素
A:与业务部分讨论了解公司的组织架构和人员分布情况,请ETL的同事做数据集成,进行数据清洗并用tableau进行数据可视化,初步分析员工分布和离职某个因素的关系。用正态化进行特征处理和计算条件熵进行特征选择。分别采用逻辑回归和决策树模型进行预测,再用交叉验证进行误差分析,模型融合,然后得出分析报告。
R:93%的拟合程度
6.在这个项目中你的贡献是什么?
1.数据清洗2.制作报表进行数据可视化3.数据清洗+特征处理和特征选择4.选择模型进行预测5.误差分析,模型融合6.得出分析报告
7.项目里使用的算法与策略的原理是什么?
8.遇到过的比较有挑战性的工作或难题以及你是怎样克服的?
9.给出一个实例,讲讲如何进行特征选择?
10.怎么做恶意刷单检测
1.商家特征:商家历史销量、信用、产品类别、发货快递等
2.用户行为特征:用户信用、下单量、转化率、下单路径、浏览店铺、支付账号
3.环境特征(机器刷单):地区、ip、手机型号
4.异常检测:ip地址经常变动、经常清空cookie信息、账号近期交易成功率上升等
5.文本检测:计算与已标注文本的相似度作为特征
6.图片:刷单可能重复利用图片进行评论
11.普通统计分析方法与机器学习的差别?
许多统计模型可以做出预测,但是预测效果没有那么好。机器学习通常会牺牲可解释性以获得强大的预测能力。
12.一个网站销售额变低,你从哪几个方面去考量
1.定位到现象真正发生的位置:用户 and 产品 and 访问时段
2.关注哪个指标造成的:销售额 or 入站流量 or 下单率 or 客单价
3.确定源头后,对问题进行分析:内部:网站改版/产品更新/广告投放 外部:用户偏好变化/媒体新闻/经济环境/竞品行为
13.怎么向小孩子解释正态分布
拿出成绩表或身高表画图。正态分布像一只倒扣的钟。两头低,中间高,左右对称。大部分数据集中在平均值,小部分在两端。正态分布,normal distribution,也叫做常态分布,就是说绝大部分都在中间的位置,极少数在两头。
14.统计中国有多少树
区分地类后,八大地类,对不同的地类进行小班调查,采用随机抽样的方法
简单随机抽样:抽签法,随机数字
系统抽样:从第一部分取n号作为样本数据,依次用相等间距,从各部分抽取一个个体组成样本。
整群抽样:随机抽取几个群组成样本
分层抽样:将总体分为若干个类别,再从每一层内随机抽取一个合起来组成样本。
15.数据分析师面临的常见问题。
拼写错误、重复的条目、缺失值、非法值、不同的值表示、重叠数据的识别