姿态估计0-02:DenseFusion(6D姿态估计)-源码训练测试,报错解决
以下链接是个人关于DenseFusion(6D姿态估计) 所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:a944284742相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。
姿态估计0-00:DenseFusion(6D姿态估计)-目录-史上最新无死角讲解https://blog.csdn.net/weixin_43013761/article/details/103053585
在讲解之前,请大家按照前面的博客,下载好代码,然后我们从README.md文件开始。
注 意 , 下 面 的 讲 解 和 报 错 首 先 是 W i n d s 环 境 下 , 然 后 本 人 直 接 炸 锅 , \color{red}{注意,下面的讲解和报错首先是Winds环境下,然后本人直接炸锅,} 注意,下面的讲解和报错首先是Winds环境下,然后本人直接炸锅,
调 试 失 败 后 续 不 得 不 转 移 战 略 , 在 L i n u x 下 面 进 行 调 试 , 调 试 完 成 \color{red}{调试失败后续不得不转移战略,在Linux下面进行调试,调试完成} 调试失败后续不得不转移战略,在Linux下面进行调试,调试完成
还有就是,本人编写该博客的时间点为2019/11/13,也就是说,你此时的从官方下载的代码,可能和我调试时的不一样(如果官方更新过)。
数据下载
其实没得太多的技巧,我们依旧从README.md开始,我现在不想看什么乱七八糟的东西,只是想把代码快点跑起来,读过论文的朋友应该都知道,该模型主要在两个数据集上进行了验证,这个数据集分别为YCB_Video Dataset,以及LineMOD。在README.md找到如下内容:

从上面可以知道,可以执行./download.sh脚本直接下载,本人尝试过之后,下载失败,不知道是不是没有使用VPN的原因,没有办法,我只能用鼠标去点击下载。首先是下载YCB_Video Dataset,进去之后点击红色位置下载即可:
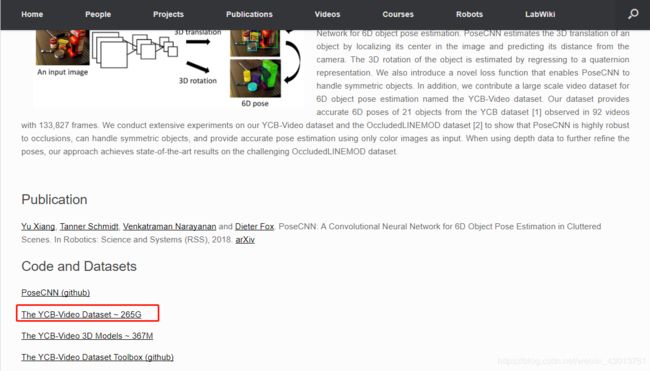
很遗憾,本人没有下载成功,但是preprocessed LineMOD dataset中的内容,如下:
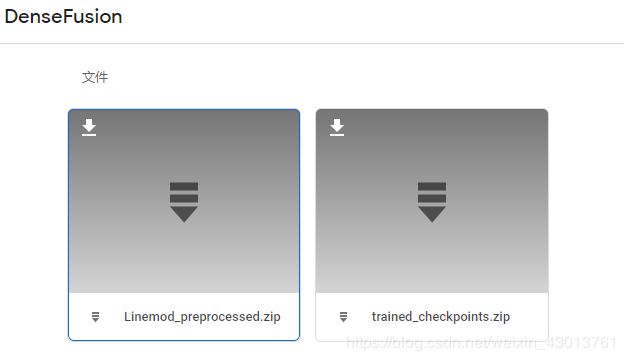
本人下载成功,根据本本人习惯,创建一个一个文件夹,专门用来存放数据,和工程目录并列如下:

并且下载好之后的Linemod_preprocessed.zip存放如下:
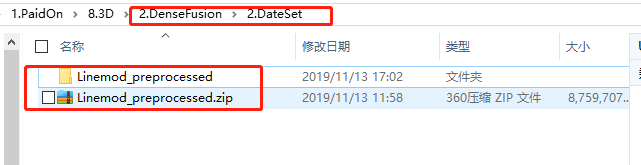
然后还有下载好的模型trained_models.zp,本人解压之后放置如下:
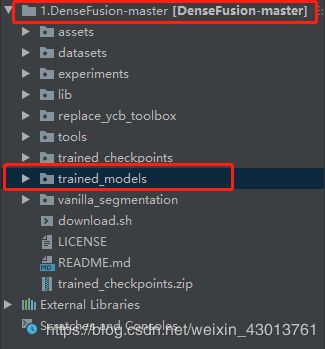
这样放置后,我们就开始训练了,这里注意一下,因为没有下载到YCB_Video Dataset,所以暂时先使用LineMOD训练,如果以后我能下载到该数据集,再带大家训练YCB_Video数据集。
LineMOD数据
数据训练
主要还是根据README.md进行操作:
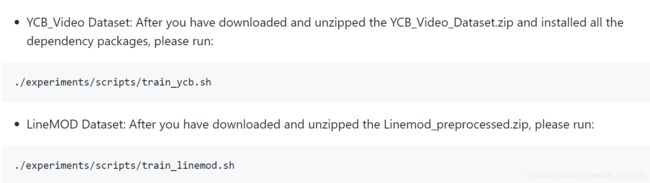
可以看到,训练LineMOD数据集,执行为:
./experiments/scripts/train_linemod.sh
查看该脚本内容如下:
#!/bin/bash
set -x
set -e
export PYTHONUNBUFFERED="True"
export CUDA_VISIBLE_DEVICES=0
python3 ./tools/train.py --dataset linemod --dataset_root ./datasets/linemod/Linemod_preprocessed
所以先在pycharm设置环境变量,以及命令行参数,首先点击如下(需要先选中tools/train.py程序):
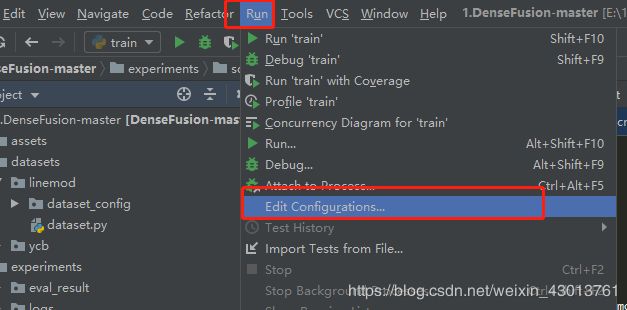
然后配置环境变量
export PYTHONUNBUFFERED="True"
export CUDA_VISIBLE_DEVICES=0
操作如下
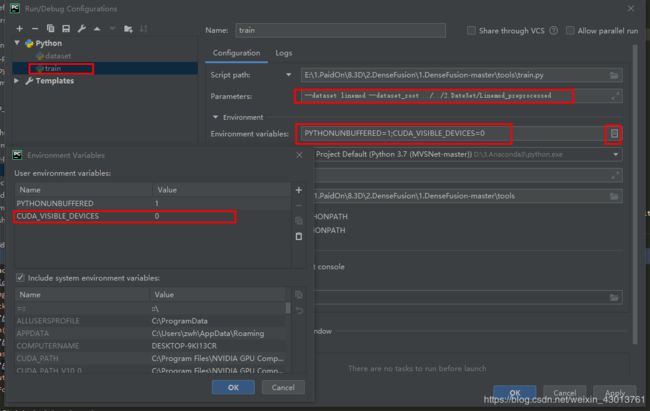
主要要替换路径(本人操作如下):
--dataset linemod --dataset_root ../../2.DateSet/Linemod_preprocessed
配置完成之后,运行tools/train.py
报错一(可以直接跳过改错误,本人已经直接炸锅,更换作战方案)
File "E:\1.PaidOn\8.3D\2.DenseFusion\1.DenseFusion-master\lib\knn\knn_pytorch\__init__.py", line 2, in
from torch.utils.ffi import _wrap_function
File "D:\3.Anaconda3\lib\site-packages\torch\utils\ffi\__init__.py", line 1, in
raise ImportError("torch.utils.ffi is deprecated. Please use cpp extensions instead.")
ImportError: torch.utils.ffi is deprecated. Please use cpp extensions instead.
主要原因是在torch1.2.0中,其已经弃用了torch.utils.ffi这个模块,建议使用torch.utils.cpp_extension 代替,然后报错如下:
File "E:\1.PaidOn\8.3D\2.DenseFusion\1.DenseFusion-master\lib\knn\knn_pytorch\__init__.py", line 2, in
from torch.utils.cpp_extension import _wrap_function
ImportError: cannot import name '_wrap_function' from 'torch.utils.cpp_extension' (D:\3.Anaconda3\lib\site-packages\torch\utils\cpp_extension.py)
百度无果,重新搭建合适该项目的环境,搭建来,搭建去各种报错,后续无奈,根据上面的提示进入1.DenseFusion-master\lib\knn\knn_pytorch\_init_.py文件,修改内容如下:
# import sys
#
#
# from torch.utils.ffi import _wrap_function
# from ._knn_pytorch import lib as _lib, ffi as _ffi
#
# __all__ = []
# def _import_symbols(locals):
# for symbol in dir(_lib):
# fn = getattr(_lib, symbol)
# if callable(fn):
# locals[symbol] = _wrap_function(fn, _ffi)
# else:
# locals[symbol] = fn
# __all__.append(symbol)
#
# _import_symbols(locals())
是的,本人直接暴力的全部注释掉,暂时就先这样,继续往下运行,重新执行train.py
运行显示如下:
报错二 重 点 , 新 的 开 始 \color{red}{重点,新的开始} 重点,新的开始
File "D:\3.Anaconda3\envs\zwh_[python=3.6,pytorch=1.0.0,torchvision==0.2.1,cuda100]\lib\site-packages\torch\cuda\__init__.py", line 75, in _check_driver
raise AssertionError("Torch not compiled with CUDA enabled")
AssertionError: Torch not compiled with CUDA enabled
你说嗨皮不嗨皮,好了,我投降,表示没脾气了,重新组织下语言,继续百度,依旧没有找到答案。最后到谷歌找到了答案,主要的原因在于,作者源码中的lib/knn是需要编译,不同德环境,编译生成的knn_pytorch/_knn_pytorch.so都不一样(主要根操作系统以及pytorch版本有关系),修改之后的源码链接如下:
https://github.com/hoangcuongbk80/Object-RPE/tree/master/DenseFusion
下载完成之后,因为是在linux运行的,我先按照作者的习惯,把数据集Linemod_preprocessed移动到如下位置:
从第一作者源码的/experiments/scripts目录下,拷贝train_linemod.sh以及eval_linemod.sh到新作者的对应目录中(不知道为什么新作者没有则两个文件)。拷贝完成之后我们就要搭建环境了,根据新作者的note.txt,本人执行了如下命令
pip --no-cache-dir install numpy scipy pyyaml cffi pyyaml matplotlib Cython Pillow
pip install https://download.pytorch.org/whl/cu100/torch-1.0.1.post2-cp35-cp35m-linux_x86_64.whl
pip install torchvision == 0.2.2.post
其环境要求是如下:
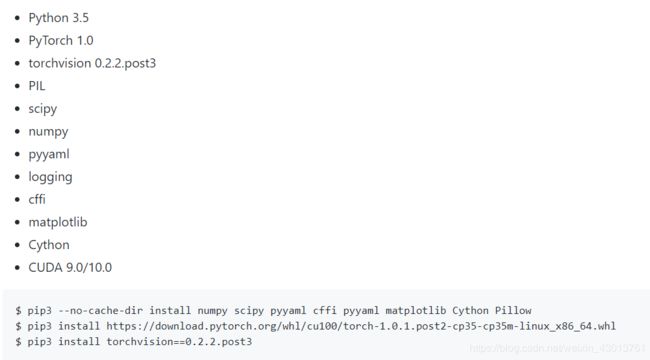
因为服务器的CUDA10.0早就安装完成,所以搭建起来十分的方便。
搭建完成之后,执行命令如下(在工程的根目录):
./experiments/scripts/train_linemod.sh
打印类似如下:
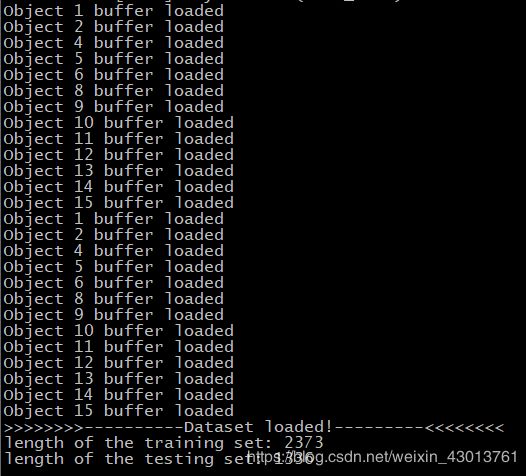
报错三
UserWarning: size_average and reduce args will be deprecated, please use reduction='mean' instead.
warnings.warn(warning.format(ret))
Traceback (most recent call last):
File "./tools/train.py", line 252, in
main()
File "./tools/train.py", line 125, in main
for log in os.listdir(opt.log_dir):
FileNotFoundError: [Errno 2] No such file or directory: 'experiments/logs/linemod'
(zwh_[python=3.5,pytorch=1.0.1,torchvision==0.2.2,cuda100]) root@ubuntu:/data/zwh/2.3D/2.DenseFusion/1.DenseFusion#
直接创建/logs/linemod文件夹即可,如下
打印如下:
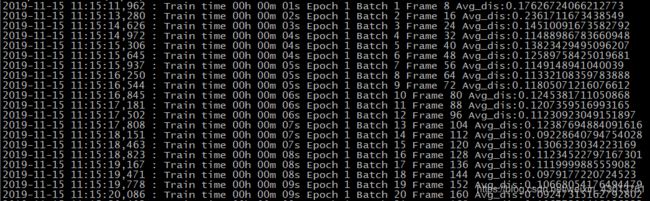
一句MMP送出,为了跑起来,真的已经怀疑人生了,论文看完了,代码跑不起来,真的难受。不过现在看来是初步成功过了。
报错四
在跑的过程还会遇到如下错误
File "/root/anaconda3/envs/zwh_[python=3.5,pytorch=1.0.1,torchvision==0.2.2,cuda100]/lib/python3.5/site-packages/torch/serialization.py", line 142, in _with_file_like
f = open(f, mode)
FileNotFoundError: [Errno 2] No such file or directory: 'trained_models/linemod/pose_model_current.pth'
创建linemod目录如下即可:
下面我们要做的就是模型测试了。
模型测试
首先我们把下载好的trained_checkpoints.zip解压之后,放置如下(放在根目录):

然后执行
./experiments/scripts/eval_linemod.sh
报错一
pts/eval_linemod.sh
+ set -e
+ export PYTHONUNBUFFERED=True
+ PYTHONUNBUFFERED=True
+ export CUDA_VISIBLE_DEVICES=1
+ CUDA_VISIBLE_DEVICES=1
+ python3 ./tools/eval_linemod.py --dataset_root ./datasets/linemod/Linemod_preprocessed --model trained_checkpoints/linemod/pose_model_9_0.01310166542980859.pth --refine_model trained_checkpoints/linemod/pose_refine_model_493_0.006761023565178073.pth
python3: can't open file './tools/eval_linemod.py': [Errno 2] No such file or directory
从第一作者的源码拷贝tools/eval_linemod.py拷贝到新作者对应的目录下。
报错三
Traceback (most recent call last):
File "./tools/eval_linemod.py", line 66, in
fw = open('{0}/eval_result_logs.txt'.format(output_result_dir), 'w')
FileNotFoundError: [Errno 2] No such file or directory: 'experiments/eval_result/linemod/eval_result_logs.txt'
创建目录如下linemod:
报错四
File "/root/anaconda3/envs/zwh_[python=3.5,pytorch=1.0.1,torchvision==0.2.2,cuda100]/lib/python3.5/site-packages/torch/utils/data/dataloader.py", line 138, in
samples = collate_fn([dataset[i] for i in batch_indices])
File "/data/zwh/2.3D/2.DenseFusion/1.DenseFusion/datasets/linemod/dataset.py", line 122, in __getitem__
rmin, rmax, cmin, cmax = get_bbox(mask_to_bbox(mask_label))
File "/data/zwh/2.3D/2.DenseFusion/1.DenseFusion/datasets/linemod/dataset.py", line 218, in mask_to_bbox
_, contours, _ = cv2.findContours(mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
ValueError: not enough values to unpack (expected 3, got 2)
(zwh_[python=3.5,pytorch=1.0.1,torchvision==0.2.2,cuda100]) root@ubuntu:/data/zwh/2.3D/2.DenseFusion/1.DenseFusion#
主要是版本更替,函数返回结果数目于一致,修改datasets/linemod/dataset.py 218行如下:
#_, contours, _ = cv2.findContours(mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
contours, _ = cv2.findContours(mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
打印类似如下:
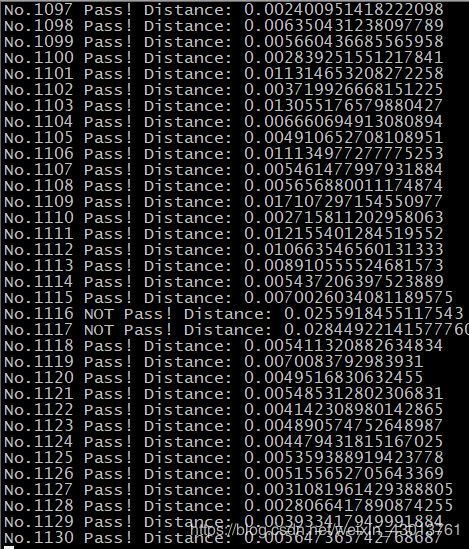
最终打印:
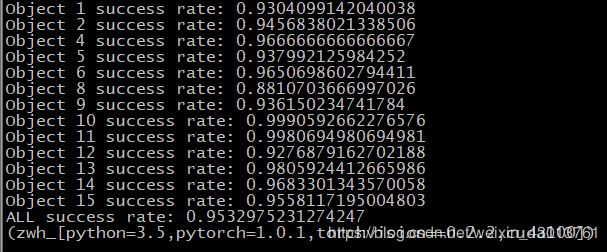
为了这个结果真的不容易啊,几天时间都消耗在这里了,不过也算过来了。如果后续YCB_Video Dataset下载成功了,我应该也会带着大家过一遍。从下篇博客开始,我们先讲解论文,然后再对代码进行详细讲解。