姿态估计0-05:DenseFusion(6D姿态估计)-源码解析(1)-训练代码初探,框架了解
以下链接是个人关于DenseFusion(6D姿态估计) 所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:a944284742相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。
姿态估计0-00:DenseFusion(6D姿态估计)-目录-史上最新无死角讲解https://blog.csdn.net/weixin_43013761/article/details/103053585
代码详细注解
从之前的博客,我相信大家都已经知道,训练代码为tools/train.py,下面时对该代码的详细注解(这里只要随便看看就好,最后面还有总结)
# --------------------------------------------------------
# DenseFusion 6D Object Pose Estimation by Iterative Dense Fusion
# Licensed under The MIT License [see LICENSE for details]
# Written by Chen
# --------------------------------------------------------
import _init_paths
import argparse
import os
import random
import time
import numpy as np
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
from torch.autograd import Variable
from datasets.ycb.dataset import PoseDataset as PoseDataset_ycb
from datasets.warehouse.dataset import PoseDataset as PoseDataset_warehouse
from datasets.linemod.dataset import PoseDataset as PoseDataset_linemod
from lib.network import PoseNet, PoseRefineNet
from lib.loss import Loss
from lib.loss_refiner import Loss_refine
from lib.utils import setup_logger
from torchsummary import summary
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', type=str, default = 'ycb', help='ycb or warehouse or linemod')
parser.add_argument('--dataset_root', type=str, default = '', help='dataset root dir (''YCB_Video_Dataset'' or ''Warehouse_Dataset'' or ''Linemod_preprocessed'')')
parser.add_argument('--batch_size', type=int, default = 8, help='batch size')
# 加载数据的线程数目
parser.add_argument('--workers', type=int, default = 10, help='number of data loading workers')
# 初始学习率
parser.add_argument('--lr', default=0.0001, help='learning rate')
parser.add_argument('--lr_rate', default=0.3, help='learning rate decay rate')
# 初始权重
parser.add_argument('--w', default=0.015, help='learning rate')
# 权重衰减率
parser.add_argument('--w_rate', default=0.3, help='learning rate decay rate')
#
parser.add_argument('--decay_margin', default=0.016, help='margin to decay lr & w')
# 大概是loss到了这个设定的值,则会进行refine模型的训练
parser.add_argument('--refine_margin', default=0.013, help='margin to start the training of iterative refinement')
# 给训练数据添加噪声相关的参数,可以理解为数据增强
parser.add_argument('--noise_trans', default=0.03, help='range of the random noise of translation added to the training data')
# 训练refinenet的时候是连续迭代几次
parser.add_argument('--iteration', type=int, default = 2, help='number of refinement iterations')
# 训练到多少个epoch则停止
parser.add_argument('--nepoch', type=int, default=500, help='max number of epochs to train')
# 是否继续训练posenet模型,继续训练则加载posenet预训练模型
parser.add_argument('--resume_posenet', type=str, default = '', help='resume PoseNet model')
# 是否继续训练refinenet模型,继续训练则加载refinenet预训练模型
parser.add_argument('--resume_refinenet', type=str, default = '', help='resume PoseRefineNet model')
parser.add_argument('--start_epoch', type=int, default = 1, help='which epoch to start')
opt = parser.parse_args()
def main():
opt.manualSeed = random.randint(1, 100)
# 为CPU随机生成数设定的种子
random.seed(opt.manualSeed)
# 为GPU随机生成数设定的种子
torch.manual_seed(opt.manualSeed)
# 根据数据集的不同,分别配置其
# 训练数据的物体种类数目,输入点云的数目,训练模型保存的目录,log保存的目录,起始的epoch数目
if opt.dataset == 'ycb':
opt.num_objects = 21 #number of object classes in the dataset
opt.num_points = 1000 #number of points on the input pointcloud
opt.outf = 'trained_models/ycb' #folder to save trained models
opt.log_dir = 'experiments/logs/ycb' #folder to save logs
opt.repeat_epoch = 1 #number of repeat times for one epoch training
elif opt.dataset == 'warehouse':
opt.num_objects = 13
opt.num_points = 1000
opt.outf = 'trained_models/warehouse'
opt.log_dir = 'experiments/logs/warehouse'
opt.repeat_epoch = 1
elif opt.dataset == 'linemod':
opt.num_objects = 13
opt.num_points = 500
opt.outf = 'trained_models/linemod'
opt.log_dir = 'experiments/logs/linemod'
opt.repeat_epoch = 20
else:
print('Unknown dataset')
return
# 该处为网络的构建,构建完成之后,能对物体的6D姿态进行预测
estimator = PoseNet(num_points = opt.num_points, num_obj = opt.num_objects)
estimator.cuda()
#summary(estimator,[(3, 120, 120),(500,3),(1,500),(1,)])
# 对初步预测的姿态进行提炼
refiner = PoseRefineNet(num_points = opt.num_points, num_obj = opt.num_objects)
refiner.cuda()
# 对posenet以及refinenet模型的加载,然后标记对应的网络是否已经开始训练过了,以及是否进行衰减
if opt.resume_posenet != '':
estimator.load_state_dict(torch.load('{0}/{1}'.format(opt.outf, opt.resume_posenet)))
if opt.resume_refinenet != '':
refiner.load_state_dict(torch.load('{0}/{1}'.format(opt.outf, opt.resume_refinenet)))
opt.refine_start = True
opt.decay_start = True
opt.lr *= opt.lr_rate
opt.w *= opt.w_rate
opt.batch_size = int(opt.batch_size / opt.iteration)
optimizer = optim.Adam(refiner.parameters(), lr=opt.lr)
else:
opt.refine_start = False
opt.decay_start = False
optimizer = optim.Adam(estimator.parameters(), lr=opt.lr)
# 加载对应的训练和验证数据集
if opt.dataset == 'ycb':
dataset = PoseDataset_ycb('train', opt.num_points, True, opt.dataset_root, opt.noise_trans, opt.refine_start)
elif opt.dataset == 'warehouse':
dataset = PoseDataset_warehouse('train', opt.num_points, True, opt.dataset_root, opt.noise_trans, opt.refine_start)
elif opt.dataset == 'linemod':
dataset = PoseDataset_linemod('train', opt.num_points, True, opt.dataset_root, opt.noise_trans, opt.refine_start)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=True, num_workers=opt.workers)
if opt.dataset == 'ycb':
test_dataset = PoseDataset_ycb('test', opt.num_points, False, opt.dataset_root, 0.0, opt.refine_start)
elif opt.dataset == 'warehouse':
test_dataset = PoseDataset_warehouse('test', opt.num_points, False, opt.dataset_root, 0.0, opt.refine_start)
elif opt.dataset == 'linemod':
test_dataset = PoseDataset_linemod('test', opt.num_points, False, opt.dataset_root, 0.0, opt.refine_start)
testdataloader = torch.utils.data.DataLoader(test_dataset, batch_size=1, shuffle=False, num_workers=opt.workers)
opt.sym_list = dataset.get_sym_list()
#print(opt.sym_list)
opt.num_points_mesh = dataset.get_num_points_mesh()
print('>>>>>>>>----------Dataset loaded!---------<<<<<<<<\nlength of the training set: {0}\nlength of the testing set: {1}\nnumber of sample points on mesh: {2}\nsymmetry object list: {3}'.format(len(dataset), len(test_dataset), opt.num_points_mesh, opt.sym_list))
# loss计算
criterion = Loss(opt.num_points_mesh, opt.sym_list)
criterion_refine = Loss_refine(opt.num_points_mesh, opt.sym_list)
# 初始设置最好模型的loss为无限大
best_test = np.Inf
if opt.start_epoch == 1:
for log in os.listdir(opt.log_dir):
os.remove(os.path.join(opt.log_dir, log))
st_time = time.time()
# 开始循环迭代
for epoch in range(opt.start_epoch, opt.nepoch):
# 保存开始开始迭代的log信息
logger = setup_logger('epoch%d' % epoch, os.path.join(opt.log_dir, 'epoch_%d_log.txt' % epoch))
logger.info('Train time {0}'.format(time.strftime("%Hh %Mm %Ss", time.gmtime(time.time() - st_time)) + ', ' + 'Training started'))
train_count = 0
train_dis_avg = 0.0
# 判断是否开始训练refine模型
if opt.refine_start:
estimator.eval()
refiner.train()
else:
estimator.train()
optimizer.zero_grad()
# 每次 epoch 重复训练的次数
for rep in range(opt.repeat_epoch):
for i, data in enumerate(dataloader, 0):
points, choose, img, target, model_points, idx = data
# points:由深度图计算出来的点云,该点云数据以摄像头主轴参考坐标
# choose:所选择点云的索引,[bs, 1, 500]
# img:通过box剪切下来的RGB图像
# target:根据model_points点云信息,以及旋转偏移矩阵转换过的点云信息[bs,500,3]
# model_points:目标初始帧(模型)对应的点云信息[bs,500,3]
# idx:训练图片样本的下标
points, choose, img, target, model_points, idx = Variable(points).cuda(), \
Variable(choose).cuda(), \
Variable(img).cuda(), \
Variable(target).cuda(), \
Variable(model_points).cuda(), \
Variable(idx).cuda()
# 进行预测获得,获得预测的姿态,姿态预测之前的特征向量
# pred_r: 预测的旋转参数[bs, 500, 4]
# pred_t: 预测的偏移参数[bs, 500, 3]
# pred_c: 预测的置信度[bs, 500, 1],置信度
#
pred_r, pred_t, pred_c, emb = estimator(img, points, choose, idx)
# 对结果进行评估,计算loss
loss, dis, new_points, new_target = criterion(pred_r, pred_t, pred_c, target, model_points, idx, points, opt.w, opt.refine_start)
# 如果已经对refiner模型进行了训练,则进行姿态的提炼预测,对结果进行评估计算dis,并且对dis反向传播
if opt.refine_start:
for ite in range(0, opt.iteration):
pred_r, pred_t = refiner(new_points, emb, idx)
dis, new_points, new_target = criterion_refine(pred_r, pred_t, new_target, model_points, idx, new_points)
dis.backward()
else:
loss.backward()
train_dis_avg += dis.item()
train_count += 1
# log信息存储
if train_count % opt.batch_size == 0:
logger.info('Train time {0} Epoch {1} Batch {2} Frame {3} Avg_dis:{4}'.format(time.strftime("%Hh %Mm %Ss", time.gmtime(time.time() - st_time)), epoch, int(train_count / opt.batch_size), train_count, train_dis_avg / opt.batch_size))
optimizer.step()
optimizer.zero_grad()
train_dis_avg = 0
# 模型保存
if train_count != 0 and train_count % 1000 == 0:
if opt.refine_start:
torch.save(refiner.state_dict(), '{0}/pose_refine_model_current.pth'.format(opt.outf))
else:
torch.save(estimator.state_dict(), '{0}/pose_model_current.pth'.format(opt.outf))
print('>>>>>>>>----------epoch {0} train finish---------<<<<<<<<'.format(epoch))
logger = setup_logger('epoch%d_test' % epoch, os.path.join(opt.log_dir, 'epoch_%d_test_log.txt' % epoch))
logger.info('Test time {0}'.format(time.strftime("%Hh %Mm %Ss", time.gmtime(time.time() - st_time)) + ', ' + 'Testing started'))
test_dis = 0.0
test_count = 0
# 验证模型构建
estimator.eval()
refiner.eval()
for j, data in enumerate(testdataloader, 0):
# 获得验证模型的的输入数据,并且分配在GPU上运行
points, choose, img, target, model_points, idx = data
points, choose, img, target, model_points, idx = Variable(points).cuda(), \
Variable(choose).cuda(), \
Variable(img).cuda(), \
Variable(target).cuda(), \
Variable(model_points).cuda(), \
Variable(idx).cuda()
pred_r, pred_t, pred_c, emb = estimator(img, points, choose, idx)
# 对结果进行评估
_, dis, new_points, new_target = criterion(pred_r, pred_t, pred_c, target, model_points, idx, points, opt.w, opt.refine_start)
# 如果refine模型已经开始训练,则对该模型也进行评估
if opt.refine_start:
for ite in range(0, opt.iteration):
pred_r, pred_t = refiner(new_points, emb, idx)
dis, new_points, new_target = criterion_refine(pred_r, pred_t, new_target, model_points, idx, new_points)
test_dis += dis.item()
# 保存评估的log信息
logger.info('Test time {0} Test Frame No.{1} dis:{2}'.format(time.strftime("%Hh %Mm %Ss", time.gmtime(time.time() - st_time)), test_count, dis))
test_count += 1
# 计算测试数据的平均dis
test_dis = test_dis / test_count
logger.info('Test time {0} Epoch {1} TEST FINISH Avg dis: {2}'.format(time.strftime("%Hh %Mm %Ss", time.gmtime(time.time() - st_time)), epoch, test_dis))
# 如果该次的测试结果,比之前最好的模型还要好,则保存目前的模型为最好的模型
if test_dis <= best_test:
best_test = test_dis
if opt.refine_start:
torch.save(refiner.state_dict(), '{0}/pose_refine_model_{1}_{2}.pth'.format(opt.outf, epoch, test_dis))
else:
torch.save(estimator.state_dict(), '{0}/pose_model_{1}_{2}.pth'.format(opt.outf, epoch, test_dis))
print(epoch, '>>>>>>>>----------BEST TEST MODEL SAVED---------<<<<<<<<')
# 判断模型测试的结果是否达到,学习率和权重衰减的衰减要求,达到了则进行权重和学习率的衰减
if best_test < opt.decay_margin and not opt.decay_start:
opt.decay_start = True
opt.lr *= opt.lr_rate
opt.w *= opt.w_rate
optimizer = optim.Adam(estimator.parameters(), lr=opt.lr)
# 如果模型没有达到refine_margin的基准(也就是loss比设定的要低),并且refine_start=False,则设定opt.refine_start = True
# 设定改参数数,也要传递给数据集迭代器,让数据集迭代器也知道此时需要提供refine模型的相关数据了
if best_test < opt.refine_margin and not opt.refine_start:
opt.refine_start = True
opt.batch_size = int(opt.batch_size / opt.iteration)
optimizer = optim.Adam(refiner.parameters(), lr=opt.lr)
if opt.dataset == 'ycb':
dataset = PoseDataset_ycb('train', opt.num_points, True, opt.dataset_root, opt.noise_trans, opt.refine_start)
if opt.dataset == 'warehouse':
dataset = PoseDataset_warehouse('train', opt.num_points, True, opt.dataset_root, opt.noise_trans, opt.refine_start)
elif opt.dataset == 'linemod':
dataset = PoseDataset_linemod('train', opt.num_points, True, opt.dataset_root, opt.noise_trans, opt.refine_start)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=True, num_workers=opt.workers)
if opt.dataset == 'ycb':
test_dataset = PoseDataset_ycb('test', opt.num_points, False, opt.dataset_root, 0.0, opt.refine_start)
if opt.dataset == 'warehouse':
test_dataset = PoseDataset_warehouse('test', opt.num_points, False, opt.dataset_root, 0.0, opt.refine_start)
elif opt.dataset == 'linemod':
test_dataset = PoseDataset_linemod('test', opt.num_points, False, opt.dataset_root, 0.0, opt.refine_start)
testdataloader = torch.utils.data.DataLoader(test_dataset, batch_size=1, shuffle=False, num_workers=opt.workers)
opt.sym_list = dataset.get_sym_list()
opt.num_points_mesh = dataset.get_num_points_mesh()
print('>>>>>>>>----------Dataset loaded!---------<<<<<<<<\nlength of the training set: {0}\nlength of the testing set: {1}\nnumber of sample points on mesh: {2}\nsymmetry object list: {3}'.format(len(dataset), len(test_dataset), opt.num_points_mesh, opt.sym_list))
criterion = Loss(opt.num_points_mesh, opt.sym_list)
criterion_refine = Loss_refine(opt.num_points_mesh, opt.sym_list)
if __name__ == '__main__':
main()
思路总结
大家也不要觉得太复杂,其上总的来说可以分为以下几个部分
1.搭建网络
estimator = PoseNet(num_points = opt.num_points, num_obj = opt.num_objects)
refiner = PoseRefineNet(num_points = opt.num_points, num_obj = opt.num_objects)
2.构建训练验证测试数据集的迭代器:
PoseDataset_ycb PoseDataset_warehouse PoseDataset_linemod
3.循环迭代,在迭代过程总,每个epoch结束之后,都会对当前模型进行一次判断
if best_test < opt.refine_margin and not opt.refine_start:
如果达到了要求,则开始训练refiner模型
其上的PoseNet网络,对应论文中如下部分:

是的,你没有看错,都包揽在其中,后续我们会大家一一分析讲解每个模块。其后的PoseRefineNet模块,对应论文的中的如下部分:
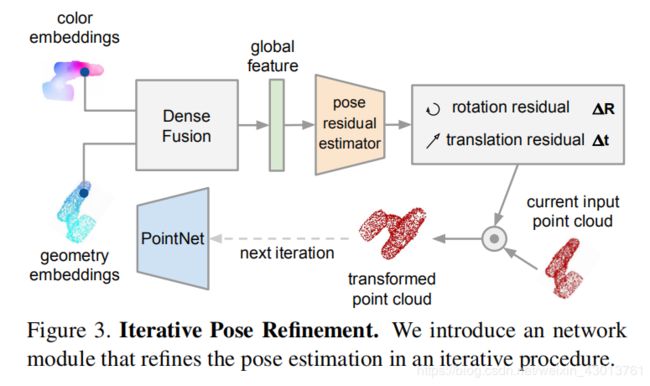
后续我也会为大家一一分析。
思路带领
那么,知道了网络框架,我们接下来要了解什么呢?当然是数据集和数据预处理,那么下小节我们就开始讲解,因为只有这样,我们才能知道网络的输入是什么。