100-分布式日志收集-ELK
文章目录
- 1. Elasticsearch版本控制
- 2. 9200与9300的区别
- 3. 倒排索引
- 4. 高级查询
- 5. Dsl语言查询与过滤
- 6. 自定义扩展字典
- 7. ES类型支持
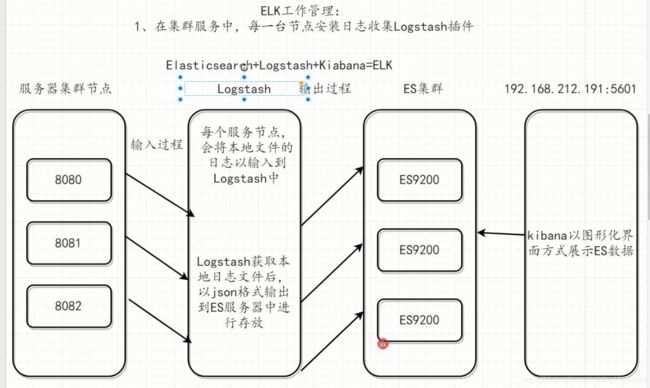
- 7. ELK工作原理
1. Elasticsearch版本控制
索引(Index) ⇒ 类型(type) ⇒ 文档(Docments) ⇒ 字段(Fields)
1.为什么要进行版本控制
为了保证数据再多线程操作下的准确性
2.悲观锁和乐观锁
悲观锁:假设会发生并发冲突,屏蔽一切可能违反数据准确性的操作
悲观锁:假设不会发生并发冲突,只在提交操作是检查是否违反数据完整性。
3.内部版本控制和外部版本控制
内部版本控制:_version自增长,修改数据后,_version会自动的加1
外部版本控制:为了保持_version与外部版本控制的数值一致
使用version_type=external检查数据当前的version值是否小于请求中的version值
###创建索引
PUT /mymayikt
####查询索引
GET /mymayikt
####添加文档 /索引名称/类型/id
PUT /mymayikt/user/1
{
"name":"yushengjun",
"sex":0,
"age":22
}
###查询文档
GET /mymayikt/user/1
###删除索引
DELETE /mymayikt
2. 9200与9300的区别
9300与9200区别
9300端口: ES节点之间通讯使用
9200端口: ES节点 和 外部 通讯使用
9300是TCP协议端口号,ES集群之间通讯端口号
9200端口号,暴露ES RESTful接口端口号
3. 倒排索引
倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。
4. 高级查询
根据id进行查询
GET /mymayikt/user/12
查询当前所有类型的文档
GET /mymayikt/user/_search
根据多个ID批量查询
查询多个id分别为1、2
GET /mymayikt/user/_mget
{
“ids”:[“1”,“2”]
}
复杂条件查询
查询年龄为年龄21岁
GET /mymayikt/user/_search?q=age:21
查询年龄30岁-60岁之间
GET /mymayikt/user/_search?q=age[30 TO 60]
注意:TO 一定要大写
查询年龄30岁-60岁之间 并且年龄降序、从0条数据到第1条数据
GET /mymayikt/user/_search?q=age[30 TO 60]&sort=age:desc&from=0&size=1
查询年龄30岁-60岁之间 并且年龄降序、从0条数据到第1条数据,展示name和age字段
GET /mymayikt/user/_search?q=age[30 TO 60]&sort=age:desc&from=0&size=1
&_source=name,age
5. Dsl语言查询与过滤
GET mymayikt/user/_search
{
"query": {
"term": {
"name": "xiaoming"
}
}
}
GET /mymayikt/user/_search
{
"from": 0,
"size": 2,
"query": {
"match": {
"car": "奥迪"
}
}
}
GET /mymayikt/user/_search
{
"query": {
"bool": {
"must": [{
"match_all": {}
}],
"filter": {
"range": {
"age": {
"gt": 21,
"lte": 51
}
}
}
}
},
"from": 0,
"size": 10,
"_source": ["name", "age"]
}
Term查询不会对字段进行分词查询,会采用精确匹配。
Match会根据该字段的分词器,进行分词查询。
6. 自定义扩展字典
在/usr/local/elasticsearch-6.4.3/plugins/ik/config目录下
vi custom/new_word.dic
vi IKAnalyzer.cfg.xml
<properties>
<comment>IK Analyzer 扩展配置comment>
<entry key="ext_dict">custom/new_word.dicentry>
<entry key="ext_stopwords">entry>
properties>
7. ES类型支持
基本类型
符串:string,string类型包含 text 和 keyword。
text:该类型被用来索引长文本,在创建索引前会将这些文本进行分词,转化为词的组合,建立索引;允许es来检索这些词,text类型不能用来排序和聚合。
keyword:该类型不需要进行分词,可以被用来检索过滤、排序和聚合,keyword类型自读那只能用本身来进行检索(不可用text分词后的模糊检索)。
注意: keyword类型不能分词,Text类型可以分词查询
数指型:long、integer、short、byte、double、float
日期型:date
布尔型:boolean
二进制型:binary
数组类型(Array datatype)
复杂类型
地理位置类型(Geo datatypes)
地理坐标类型(Geo-point datatype):geo_point 用于经纬度坐标
地理形状类型(Geo-Shape datatype):geo_shape 用于类似于多边形的复杂形状
特定类型(Specialised datatypes)
Pv4 类型(IPv4 datatype):ip 用于IPv4 地址
Completion 类型(Completion datatype):completion 提供自动补全建议
Token count 类型(Token count datatype):token_count 用于统计做子标记的字段的index数目,该值会一直增加,不会因为过滤条件而减少
mapper-murmur3 类型:通过插件,可以通过_murmur3_来计算index的哈希值
附加类型(Attachment datatype):采用mapper-attachments插件,可支持_attachments_索引,例如 Microsoft office 格式,Open Documnet 格式, ePub,HTML等
POST /mymayikt/_mapping/user
{
"user":{
"properties":{
"age":{
"type":"integer"
},
"sex":{
"type":"integer"
},
"name":{
"type":"text",
"analyzer":"ik_smart",
"search_analyzer":"ik_smart"
},
"car":{
"type":"keyword"
}
}
}
}
7. ELK工作原理