opencv特征检测和匹配
opencv可以检测图像的主要特征,然后提取这些特征,使其成为图像描述符,利用这些图像描述符来搜索数据库里,进行图像的检测
1.特征检测算法
算法:
- Harris:用于检测角点
- SIFT:用于检测斑点
- SURF:用于检测斑点
- FAST:用于检测角点
- BRIEF:用于检测斑点
- ORB:代表带有方向的FAST算法与具有旋转不变性的BRIEF算法
方法:
- 暴力匹配法
- 基于FLANN的匹配法
2.cornerHarris角点检测
import cv2
import numpy as np
img = cv2.imread('E:\\opencv3\\charpter6\\chess_board.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
gray = np.float32(gray)#为了使用cornerHarris函数,需要将棋盘图像转化为灰度个事
dst = cv2.cornerHarris(gray,4,21,0.04)#从灰度图像做处理,提取角点信息
#第二个参数:参数值越小,标记点的大小越小
#第三个参数:参数值只能在3-31之间,而且必须是奇数,表示敏感度,越小,敏感度越强,会把很多细节的东西也算成角点
#第三个参数:自由参数,取值参数为 [0,04,0.06]
img[dst>0.01*dst.max()] = [0,0,255]
while (True):
cv2.imshow('result',img)
if cv2.waitKey(5) & 0xff == ord('q'):
break
cv2.destroyAllWindows()

dst>0.01*dst.max()这么多返回是满足条件的dst索引值,根据索引值来设置这个点的颜色,这里是设定一个阈值 当大于这个阈值分数的都可以判定为角点
3.DOG和SIFT进行特征提取与描述
cornerHarris函数可以很好的检测到角点,这与焦点的特性有关,即使图片旋转,也能检测到角点,但是如果图像压缩了或者增大了,那么cornerHarris检测的角点信息就可能遗漏,图像越小越有可能丢失掉角点信息
这使我们可以用一种与图像比例无关的角点检测方法:SIFT
该函数在图像尺度变化时依然能输出同样的结果,但是SIFT并不检测关键点,关键点是由DOG检测的,但是SIFT会通过一个特征向量来描述特征点周围的区域情况
DOG(Differen Of Gaussians)
DOG是对同一副图像使用不同的高斯滤波器所得到的结果,前面有提到过cv2.GaussianBlur()低通滤波的模糊处理效果,DOG技术可以有效地检测到边缘,做种结果是感兴趣的区域(关键点)
import cv2
import numpy as np
impath = 'E:\\opencv3\\charpter6\\chess_board.jpg'
img = cv2.imread(impath)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
sift = cv2.xfeatures2d.SIFT_create()
keypoints,descriptor = sift.detectAndCompute(gray,None)
#返回的是关键点信息和描述符
img = cv2.drawKeypoints(image = img,
outImage = img,
keypoints = keypoints,
flags = cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS,
color = (51,163,236))
cv2.imshow('sift_keypoints',img)
while(True):
if cv2.waitKey(5) & 0xff == ord('q'):
break
cv2.destroyAllWindows()

sift = cv2.xfeatures2d.SIFT_create()
keypoints,descriptor = sift.detectAndCompute(gray,None)
这里创建了一个SIFT对象,SIFT对象会使用DOG检测关键点,并对灰度图像进行计算,计算每个关键点周围的区域特征向量,总的来说就是进行两个主要的操作:检测,计算。
这里得到的keypoints:

一共有840个特征点,每个特征点有六个属性:
**pt:**表示图像中关键点的x,y坐标
keypoints[3].pt
Out[3]: (9.074405670166016, 35.200592041015625)
**size:**表示特征的直径
keypoints[3].size
Out[4]: 5.260268211364746
**angle:**表示特征的方向
keypoints[3].angle
Out[5]: 0.021240234375
**response:**表示关键点的强度,有的特征会比其他特征好一些,response可以查看评估特征强度
keypoints[10].response
Out[7]: 0.053790051490068436
**octave:**表示所在金字塔的层级
keypoints[10].octave
Out[8]: 9372159
**class_id:**表示关键点的id
keypoints[10].class_id
Out[10]: -1
这里的descriptor:
表示计算的特征点周围的特征向量
descriptor
Out[11]:
array([[ 1., 1., 12., …, 0., 0., 1.],
[ 0., 0., 0., …, 2., 1., 5.],
[ 0., 0., 0., …, 0., 0., 7.],
…,
[ 2., 0., 0., …, 67., 19., 38.],
[20., 0., 0., …, 0., 0., 0.],
[20., 2., 0., …, 0., 0., 0.]], dtype=float32)
这是一个(840,128)的矩阵,每个特征点都用一个128维的特征向量表示
画图时用的:
cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS
表示画图时每个关键点都绘制圆圈和方向
4.Hessian算法和SURF进行特征的提取和检测
SURF特征检测算法比SIFT算法快好几倍,它吸收了SIFT算法的思想
SURF与SIFT原理类似:
SUFT采用Hessian算法检测关键点,用SURF提取特征;
SIFT采用DOG算法检测关键点,用SIFT提取特征。
import cv2
import numpy as np
impath = 'E:\\opencv3\\charpter6\\chess_board.jpg'
img = cv2.imread(impath)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
threshold = 8000 #阈值,阈值越小特征点越多
surt = cv2.xfeatures2d.SURF_create(float(threshold))
keypoints,descriptor = surt.detectAndCompute(gray,None)
#返回的是关键点信息和描述符
img = cv2.drawKeypoints(image = img,
outImage = img,
keypoints = keypoints,
flags = 4,
color = (51,163,236))
cv2.imshow('surf_keypoints',img)
while(True):
if cv2.waitKey(5) & 0xff == ord('q'):
break
cv2.destroyAllWindows()
SURF跟SIFT比较就是多了一个阈值,这个值越高,能识别的特征就越少,可以用试探法来得到最优检测。

SIFT和SURF的比较:
参考文献1
5.FAST算法
FAST 全称 Features from accelerated segment test,一种用于角点检测的算法,该算法的原理是取图像中检测点,以该点为圆心的周围的16个像素点判断检测点是否为角点。通俗的讲就是中心的的像素值比大部分周围的像素值要亮一个阈值 或者 暗一个阈值则为角点。

对于检测点p,若周围的16个像素点中有N个连续的点的像素值都比其小一个阈值 或 大 一个阈值,则该点可作为角点。即img[x] < img[p] - threshold 或 img[x] > img[p] + threshold
6.BRIEF算法
BRIEF并不是检测算法,它只是一个描述符。
SIFT和SURF的核心是detectAndCompute()函数,该函数包括两个步骤:检测和计算
关键点描述符是图像的一种表示,可以通过比较两个图片的关键点描述符,找出共同之处,因此描述符是现在作为特征匹配的一种方法
BRIEF是目前最快的描述符。
7.暴力匹配法(Brute-Force)
暴力匹配法是一种描述符匹配方法。原理是,比较两个描述符,产生匹配列表。暴力是指该算法不涉及优化,第一个描述符的所有特征都用来跟第二个描述符比较,每次比较算出一个距离值,距离值最小的被认为是匹配的。
综上所述
Harris,FAST都是用来检测角点的
SIFT(中的DOG),SURF(中的Hessian)是检测斑点的(关键点区域)
BRIEF也是检测斑点的。
ORB特征是基于FAST和BRIEF算法的,也是一种检测特征的算法
检测到了这些图像描述符,就需要进行一个匹配的操作,匹配的操作有:
暴力匹配法,FLANN匹配。
ORB特征匹配、K近邻特征匹配都是用暴力匹配法作为匹配器(BFMatcher )的
8.ORB特征匹配
ORB特征匹配可以得到的结果:
- 给FAST增加一个快速的准确的方向分量
- 能高效的计算带方向的BRIEF特征
- 在旋转的方式下,还能使用BRIEF查询图像之间的匹配情况
import cv2
import numpy as np
import matplotlib.pyplot as plt
img1 = cv2.imread('chess_board.jpg',cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread('chess_min.jpg',cv2.IMREAD_GRAYSCALE)
orb = cv2.ORB_create()
kp1,des1 = orb.detectAndCompute(img1,None)
kp2,des2 = orb.detectAndCompute(img2,None)
bf = cv2.BFMatcher(cv2.NORM_HAMMING,crossCheck = True)
matches = bf.match(des1,des2)
matches = sorted(matches,key = lambda x:x.distance)
img3 = cv2.drawMatches(img1,kp1,img2,kp2,matches[:40],img2,flags = 2)
plt.imshow(img3)
plt.show()
plt.imsave('orb.jpg',img3)
img1 = cv2.imread('chess_board.jpg',cv2.IMREAD_GRAYSCALE)
imread()的第二个参数也可以用0代替,这里的参数还可以填其他的:
IMREAD_ANYCOLOR 4
IMREAD_ANYDEPTH 2
IMREAD_COLOR 1
IMREAD_GRAYSCALE 0
IMREAD_LOAD_GDAL 8
IMREAD_UNCHANGED -1
orb = cv2.ORB_create()
kp1,des1 = orb.detectAndCompute(img1,None)
kp2,des2 = orb.detectAndCompute(img2,None)
对查询的图像和训练图片都要进行检测,然后计算关键点和描述符
kp1有500个关键点,kp2有392个关键点
des1,des2分别是这些关键点的特征向量,直接暴力匹配,遍历描述符,在满足一定置信度下,显示前n个匹配的描述符。
bf = cv2.BFMatcher(cv2.NORM_HAMMING,crossCheck = True)
matches = bf.match(des1,des2)
matches = sorted(matches,key = lambda x:x.distance)
这是暴力匹配的过程
原始图片:

局部图片:

匹配图:
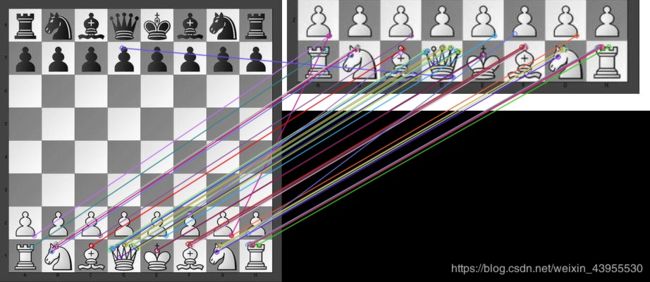
9.K-近邻匹配
KNN是一种匹配检测算法。
import numpy as np
import cv2
from matplotlib import pyplot as plt
img1 = cv2.imread('chess_min.jpg',cv2.IMREAD_GRAYSCALE)#查询图像
img2 = cv2.imread('chess_board.jpg',cv2.IMREAD_GRAYSCALE)#训练图像
#开始创建orb特征检测器和描述符
orb = cv2.ORB_create()
kp1,des1 = orb.detectAndCompute(img1,None)
kp2,des2 = orb.detectAndCompute(img2,None)
#使用默认参数的BFMatch()
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1,des2,k = 2)###knnMatch用knnMatch返回k个匹配
###drawMatchesKnn绘制匹配
img3 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,matches,img2,flags = 2)
#先填写查询图像,后填写训练图像
plt.imshow(img3)
plt.show()
plt.imsave('knn.jpg',img3)
cv2.BFMatcher创建一个 BF-Matcher 对象,它有两个可选参数。
第一个是用来指定要使用的距离测试类型,默认值为 cv2.Norm_L2。对于使用二进制描述符的 ORB,BRIEF,BRISK算法等,要使用 cv2.NORM_HAMMING,这样就会返回两个测试对象之间的汉明距离。如果 ORB 算法的参数设置为 V T A_K==3 或 4,normType就应该设置成 cv2.NORM_HAMMING2。
第二个参数是布尔变量 crossCheck,默认值为 False。如果设置为True,匹配条件就会更加严格,只有到 A 中的第 i 个特征点与 B 中的第 j 个特征点距离最近,并且 B 中的第 j 个特征点到 A 中的第 i 个特征点也是最近(A 中没有其他点到 j 的距离更近)时才会返回最佳匹配(i,j)。也就是这两个特征点要互相匹配才行。这样就能提供统一的结果。
BFMatcher 对象具有两个方法, BFMatcher.match() 和 BFMatcher.knnMatch()。第一个方法会返回最佳匹配。第二个方法为每个关键点返回 k 个最佳匹配(降序排列之后取前 k 个),其中 k 是由用户设定的。

采用比率测试来过滤掉不满足用户定义条件的匹配:
# 应用比率测试(ratio test)
good = []
for m, n in matches:
if m.distance < 0.75 * n.distance:
good.append([m])
img3 = cv2.drawMatchesKnn(img1, kp1, img2, kp2, good, None, flags=2)
plt.imshow(img3)
plt.show()
plt.imsave('knn_ratio_test.jpg',img3)
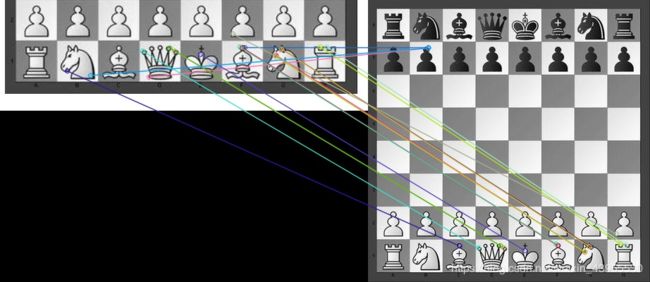
np.shape(matches)
Out[8]: (500, 2)
matches有500个匹配,每个匹配匹配两个特征点
matches[0]
Out[12]: [, ]
cv2.DMatch是opencv中匹配函数(例如:knnMatch)返回的用于匹配关键点描述符的类,这个DMatch 对象具有下列属性:
• DMatch.distance - 描述符之间的距离。越小越好。
• DMatch.trainIdx - 目标图像中描述符的索引。
• DMatch.queryIdx - 查询图像中描述符的索引。
• DMatch.imgIdx - 目标图像的索引。
if m.distance < 0.75 * n.distance
这里的参数越小,匹配越严格,匹配对数越少
matches[0][0].distance
Out[13]: 379.7446594238281
matches[0][1].distance
Out[14]: 398.87591552734375
这里good:
[[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
如果要访问queryIdx,trainIdx,imgIdx
good[4][0].queryIdx
Out[69]: 146
matches[0][0].queryIdx
Out[72]: 0
一定要保证访问属性的是DMatch而不是[DMatch]

10.FLANN匹配
FLANN比其他的最近邻搜索软件快10倍,基于FLANN的匹配非常准确,快速方便。
import numpy as np
import cv2
from matplotlib import pyplot as plt
queryImage = cv2.imread('chess_min.jpg',0)#查询图像
trainingImage = cv2.imread('chess_board.jpg',0)#训练图像
#创建一个SIFT对象,检测并计算
sift = cv2.xfeatures2d.SIFT_create()
kp1,des1 = sift.detectAndCompute(queryImage,None)
kp2,des2 = sift.detectAndCompute(trainingImage,None)
#创建FLANN匹配器
FLANN_INDEX_KDTREE = 0
indexParams = dict(algorithm = FLANN_INDEX_KDTREE,tree = 5)
searchParams = dict(checks = 50)#指定索引树被遍历多少次,次数越多,计算时间越长,越精确
flann = cv2.FlannBasedMatcher(indexParams,searchParams)
matches = flann.knnMatch(des1,des2,k = 2)
#准备一个空的mask画good匹配
matchesMask = [[0,0] for i in range(len(matches))]
for i,(m,n) in enumerate(matches):
if m.distance < 0.7*n.distance:
matchesMask[i] = [1,0]
drawParams = dict(matchColor = (0,255,0),
singlePointColor = (255,0,0),
matchesMask = matchesMask,
flags = 0)#设置匹配的颜色,特征点的颜色
resultImage = cv2.drawMatchesKnn(queryImage,kp1,trainingImage,kp2,matches,None,**drawParams)
#用指定的颜色上色,就不用彩色的那种了
plt.imshow(resultImage)
plt.show()
plt.imsave('flann.jpg',resultImage)

FLANN匹配器有两个参数:indexParams,searchParams,这两个参数在python中以字典形式进行参数传递,C++中以结构体形式进行参数传递。
indexParams:需要我们配置要使用的算法,这里用的是随机k-d树算法(The Randomized k-d TreeAlgorithm)(kd-trees可以指定待处理核密度树的数量,最理想的数量在1-16之间),当然也可以使用其他的算法,如:LinearIndex,KTreeIndex,KMeansIndex,CompositeIndex,AutotuneIndex。参考文献2
SearchParams:这是一个字典,它用来指定递归遍历的次数。值越高结果越准确,但是消耗的时间也越多。如果想修改这个值,可以传入参数。
这里5kd-trees和50checks能在合理的精度范围内,并且读时间完成
for m,n in matches:
print(m)
print(n)
得到的是
for i,(m,n) in enumerate(matches):
print(i)
print(m)
print(n)
692
693
694
695
696
697
698
699
if m.distance < 0.7*n.distance
这里丢弃掉任何距离大于0.7的值,可以避免90%的错误匹配
cv2.drawMatches()与cv2.drawMatchesKnn()区别
cv2.drawMatches()使用的点对集是一维的,(N,)
cv2.drawMatchesKnn()使用的点对集是二维的,(N,2)或者(N,1)
#np.shape(good) is (646,)
#np.shape(matches) is (6202, 2)
cv2.drawMatches(queryImage,kp1,trainingImage,kp2,good,None,**draw_params)
cv2.drawMatchesKnn(img1, kp1, img2, kp2, matches, None, flags=2)
FLANN的单应性匹配
什么叫单应性:
单应性是一个条件,该条件表示,当两幅图像中有一副图像出现了投影几遍(变形了,不是正常的矩形了)时,他们还能匹配
import numpy as np
import cv2
from matplotlib import pyplot as plt
queryImage = cv2.imread('queryImage.jpg',0)#查询图像
trainingImage = cv2.imread('trainingImage.jpg',0)#训练图像
MIN_MATCH_COUNT = 10
#创建一个sift对象检测和计算特征点
sift = cv2.xfeatures2d.SIFT_create()
kp1,des1 = sift.detectAndCompute(queryImage,None)
kp2,des2 = sift.detectAndCompute(trainingImage,None)
#创建FLANN匹配器
FLANN_INDEX_KDTREE = 0
indexParams = dict(algorithm = FLANN_INDEX_KDTREE,tree = 5)
searchParams = dict(checks = 50)
#指定索引树被遍历多少次,次数越多,计算时间越长,越精确
flann = cv2.FlannBasedMatcher(indexParams,searchParams)
matches = flann.knnMatch(des1,des2,k = 2)
good = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good.append(m)
if len(good) > MIN_MATCH_COUNT:
#如果好的匹配大于MIN_MATCH_COUNT个数的话
#就在原始图像和训练图像中把这些匹配的关键点m找出来
#获取关键点的坐标
src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1,1,2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1,1,2)
#这里的m是[DMatch]是一个列表,所以要去列表
# print('src_pts',src_pts)
# print('dst_pts',dst_pts)
#单应性
#计算变换矩阵和MASK,由关键点坐标匹配得到的变换矩阵
M,mask = cv2.findHomography(src_pts,dst_pts,cv2.RANSAC,5.0)
matchesMask = mask.ravel().tolist()
#对第二张图片计算相对于原始目标的投影畸变,绘制边框
h,w = queryImage.shape
# print(h,w)
pts = np.float32([[0,0],[0,h-1],[w-1,h-1],[w-1,0]]).reshape(-1,1,2)
dst = cv2.perspectiveTransform(pts,M)
trainingImage = cv2.polylines(trainingImage,[np.int32(dst)],True,255,3,cv2.LINE_AA)
else:
print('Not enough matches are found - %d/%d' %(len(good),MIN_MATCH_COUNT))
matchesMask = None
draw_params = dict(matchColor = (0,255,0),#匹配线画成绿色
singlePointColor = None,
matchesMask = matchesMask,
flags = 2)#只画线不画匹配点,这里颜色用的RGB标准
resultImage = cv2.drawMatches(queryImage,kp1,trainingImage,kp2,good,None,**draw_params)
#只画好的匹配,good,这里用drawMatches而不是drawMatchesKnn,因为这里是good而不是matches
#np.shape(good) is (646,)
#np.shape(matches) is (6202, 2)
plt.imshow(resultImage)
plt.show()
plt.imsave('flann_mask.jpg',resultImage)
综上所述
匹配方法有两种:暴力匹配法(Brute-Force)和FLANN法
实际代码中
暴力匹配法由BFMatcher对象实现暴力匹配:
bf = cv2.BFMatcher(cv2.NORM_HAMMING,crossCheck = True)
matches = bf.match(des1,des2)
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1,des2,k = 2)###knnMatch用knnMatch返回k个匹配
FLANN算法由FlannBasedMatcher实现:
flann = cv2.FlannBasedMatcher(indexParams,searchParams)
matches = flann.knnMatch(des1,des2,k = 2)
而在特征检测器方面
暴力匹配多用于orb特征的匹配中:
orb = cv2.ORB_create()
kp1,des1 = orb.detectAndCompute(img1,None)
kp2,des2 = orb.detectAndCompute(img2,None)
FLANN多用于SIFT特征的匹配中:
sift = cv2.xfeatures2d.SIFT_create()
kp1,des1 = sift.detectAndCompute(queryImage,None)
kp2,des2 = sift.detectAndCompute(trainingImage,None)