文章目录
- 前言
- 爬取流程
- 敲代码前的试探
- 通过试探,总结一下编程思路。
- 思路有了,上代码!
- 后记
前言
- 开门见山,直接切入正题,先看最终效果
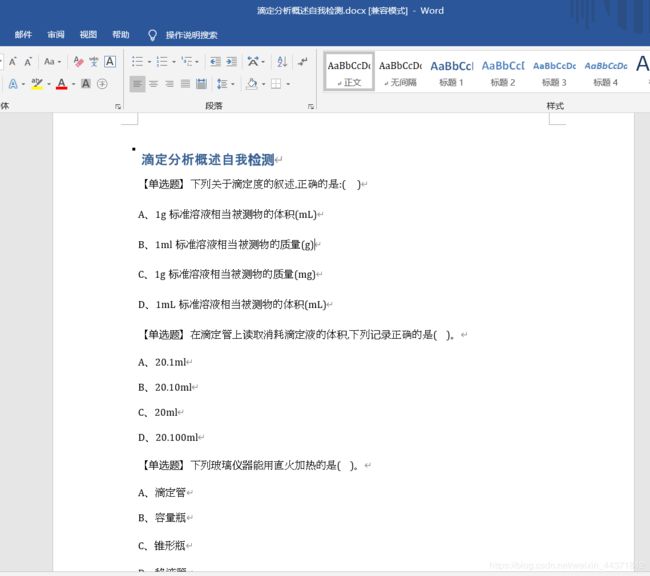
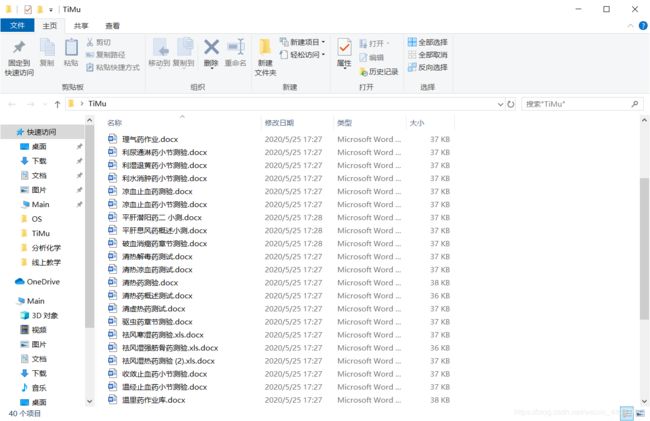
- 最终效果很理想,但这个过程是非常残酷的。
爬取流程
敲代码前的试探
import requests
courseId = 208420018
mHeaders = {
'User-Agent': r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
r'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3'
}
url = "https://mooc1.chaoxing.com/nodedetailcontroller/visitnodedetail?courseId=208255733&knowledgeId=263215264"
mHtml = requests.get(url,headers = mHeaders).content.decode('utf-8')
if '人类进入21世纪' in mHtml:
print('甩了')
else:
print('不妥')
- 输出结果——不妥,说明并不能够通过静态页面直接爬取题目。一般经验肯定是认为是接口传输的,于是开始找接口。。。。
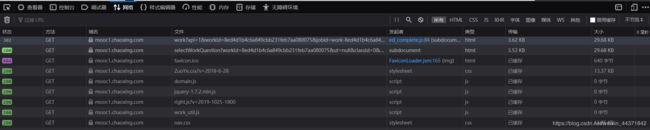
- 但是,网络传输的数据除了图片就剩html,css和js了,根本找不到传输题目的接口。
- 当我把指针选中所有题目时,我发现了一个以我的前端知识理解不了的东西。
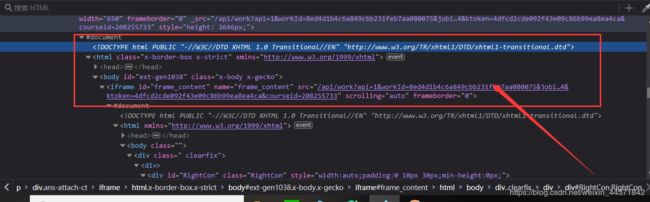
- Html中又镶嵌了一个Html,emmm…这就触及到我的知识盲区了。而且,点击下面的iframe标签里的src会跳转到一个新的页面,而这个页面正是所有的测验题目!!!
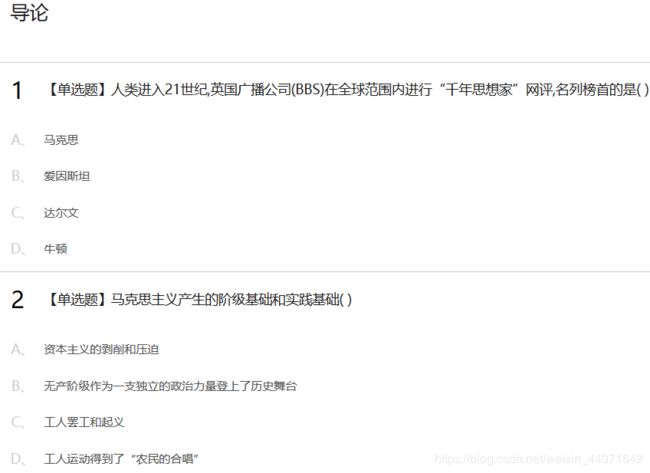
- 用postman简单Get一下,发现能够得到所有的题目!
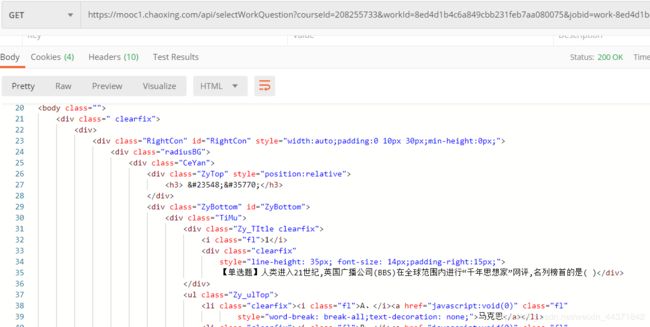
- 接下来就改分析url了,总共有7个参数,其中下图打√的是必须的,其他几个可以不加。方法:用postman挨个请求就行。对于这三个参数,courseId是本来就知道的,那么我们的目标就是找到workId和knowledgeid即可。
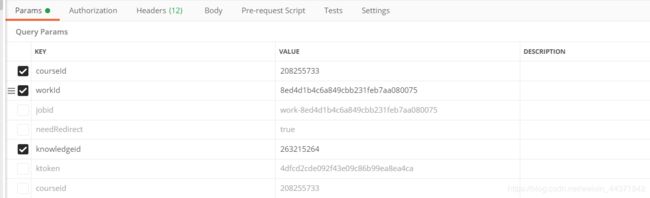
- 一番寻找后,发现knowledgeid通过静态页面就能获取。
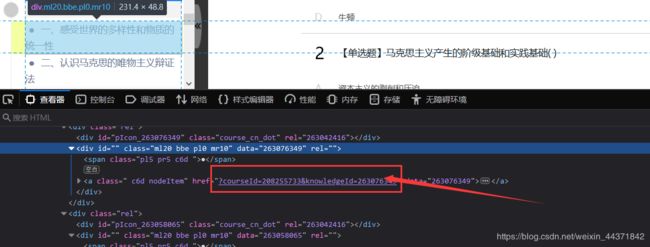
- 而workId在刚才找到的iframe标签的测验地址里,有人可能会问,那为啥不直接用测验地址呢,这我也试过,但是postman请求后的结果发现,得到的iframe标签里并没有地址,但是有个data属性,其中基本全是html转义符。

- 用Python的html库反转义后可得到workId。(后来发现,反转义与否不影响获取,直接用正则表达式就可以得到)

通过试探,总结一下编程思路。
- 首先得到课程ID(courseId),并组成url供后续访问得到章节ID(knowledgeId);
- 其次,通过访问主页面得到每一个knowledgeId,将knowledgeId和courseId组成url供后续获取workId;
- 然后,访问用courseId和knowledgeId组成的url,得到章节的workId,并将courseId,knowledgeId和workId组成最终的小测验地址;
- 对小测验地址进行访问,挨个爬取题目、选项并写入Word文档。
思路有了,上代码!
- 课程ID直接给,组成url并访问,得到页面。
def getHtml():
mUrl = url.replace('{{courseId}}',courseId)
response = requests.get(mUrl,headers=mHeaders)
response.encoding = 'utf-8'
mHtml = html.unescape(response.text)
print(mHtml)
return mHtml
- 得到每一个小节的knowledgeId并和courseId组成url,并对爬取的地址进行试探是否是章节的地址。
def getCourseUrlList(zhtml):
divList = []
re_rule = 'courseId=' + courseId + '&knowledgeId=(.*?)">'
divList = re.findall(re_rule,zhtml)
urlList = []
for i in divList:
mUrl = 'https://mooc1.chaoxing.com/nodedetailcontroller/visitnodedetail?courseId='+courseId+'&knowledgeId='+i
print(mUrl)
try:
response = requests.get(mUrl,headers=mHeaders,timeout=1)
if response.status_code == 200:
if courseId in response.text:
urlList.append(mUrl)
print('访问成功')
else:
print('非课程网页')
except Exception as e:
print('访问失败')
return urlList
- 得到workId并和courseId、knowledgeId组成小测验的url。
def getZuoYeUrl(urlList):
tUrlList = []
for i in urlList:
response = requests.get(i,headers=mHeaders).content.decode('utf-8')
res = re.findall('workid":"(.*?)",', response)
if len(res):
for i in res:
tUrl = "https://mooc1.chaoxing.com/api/selectWorkQuestion?workId="+i+"&ut=null&classId=0&courseId="+courseId
tUrlList.append(tUrl)
return tUrlList
- 访问小测验的地址并爬取标题、题干、选项写入Word文档。
def writeDocx(urlList):
for url in urlList:
mHtml = requests.get(url, headers=mHeaders).content.decode("utf-8")
file = docx.Document()
h3 = re.findall('(.*?)
', mHtml)
Title = ""
for i in h3:
Title = html.unescape(i)
file.add_heading(Title)
text = html.unescape(mHtml)
mHtml = etree.HTML(text)
timuList = mHtml.xpath('//div[@class="TiMu"]')
for i in timuList:
time.sleep(0.05)
mStr = etree.tostring(i).decode('utf-8')
res = html.unescape(mStr)
tType = re.findall('(【.*?】)', res)
tRType = []
for a in tType:
p_rule = '<.*?>'
tRType.append(re.sub(p_rule,'',str(a)))
tGan = re.findall('】?(.*?)', res)
if not len(tGan):
tGan = re.findall('(.*?)
', res)
if not len(tGan):
tGan = re.findall('】(.*?)
'
,res
)
tRGan
= []
for a
in tGan
:
p_rule
= '<.*?>'
tRGan
.append
(re
.sub
(p_rule
,'',str(a
)))
file.add_paragraph
(tRType
+ tRGan
)
'''
for j in tType:
print(j)
file.add_paragraph(j)
for j in tGan:
print(j)
file.add_paragraph(j)
'''
XuanXiang
= etree
.HTML
(res
)
tAny
= XuanXiang
.xpath
('//li[@class="clearfix"]')
for j
in tAny
:
tStr
= etree
.tostring
(j
).decode
('utf-8')
tRes
= html
.unescape
(tStr
)
tXuan
= re
.findall
('(.*?).*?none;">?(.*?)?', tRes
)
tRXuan
= []
for a
in tXuan
:
tRRXuan
= ""
for b
in a
:
p_rule
= '<.*?>'
tRRXuan
= tRRXuan
+ re
.sub
(p_rule
, '', str(b
))
tRXuan
.append
(tRRXuan
)
for k
in tRXuan
:
file.add_paragraph
(k
)
file.save
("D:\\"+Title
+".docx")
file.close
()
print(Title
+'爬取完成')
time
.sleep
(0.3)
- 全局变量及导库(放在开头)
from lxml import etree
import docx
import requests
import re
import html
import time
url = "https://mooc1.chaoxing.com/course/{{courseId}}.html"
mHeaders = {
'User-Agent': r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
r'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3'
}
- 主函数
if __name__ == "__main__":
courseId = "208255733"
zHtml = getHtml()
canUseUrl = getCourseUrlList(zHtml)
zuoYeUrl = getZuoYeUrl(canUseUrl)
writeDocx(zuoYeUrl)
后记
- 经实验,本程序适用于大部分超星学习通课程,课程号可以在访问该课程时的地址栏url中获取。
- 不要脸的推荐本人的其余爬虫文章:记一次用Python统计全国女性Size
- 如复制出错,可去博主Github取完整代码点击直达,记得点个star哦,感激不尽。
- 如有大佬发现文章错误,或代码错误,烦请指正,感激不尽。
- 创作不易,转载请注明出处,感谢。