- Python数据分析与可视化实战指南
William数据分析
pythonpython数据
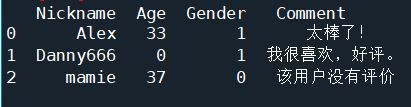
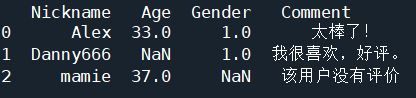
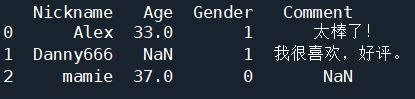
在数据驱动的时代,Python因其简洁的语法、强大的库生态系统以及活跃的社区,成为了数据分析与可视化的首选语言。本文将通过一个详细的案例,带领大家学习如何使用Python进行数据分析,并通过可视化来直观呈现分析结果。一、环境准备1.1安装必要库在开始数据分析和可视化之前,我们需要安装一些常用的库。主要包括pandas、numpy、matplotlib和seaborn等。这些库分别用于数据处理、数学
- C++ | Leetcode C++题解之第409题最长回文串
Ddddddd_158
经验分享C++Leetcode题解
题目:题解:classSolution{public:intlongestPalindrome(strings){unordered_mapcount;intans=0;for(charc:s)++count[c];for(autop:count){intv=p.second;ans+=v/2*2;if(v%2==1andans%2==0)++ans;}returnans;}};
- 《Python数据分析实战终极指南》
xjt921122
python数据分析开发语言
对于分析师来说,大家在学习Python数据分析的路上,多多少少都遇到过很多大坑**,有关于技能和思维的**:Excel已经没办法处理现有的数据量了,应该学Python吗?找了一大堆Python和Pandas的资料来学习,为什么自己动手就懵了?跟着比赛类公开数据分析案例练了很久,为什么当自己面对数据需求还是只会数据处理而没有分析思路?学了对比、细分、聚类分析,也会用PEST、波特五力这类分析法,为啥
- Python开发常用的三方模块如下:
换个网名有点难
python开发语言
Python是一门功能强大的编程语言,拥有丰富的第三方库,这些库为开发者提供了极大的便利。以下是100个常用的Python库,涵盖了多个领域:1、NumPy,用于科学计算的基础库。2、Pandas,提供数据结构和数据分析工具。3、Matplotlib,一个绘图库。4、Scikit-learn,机器学习库。5、SciPy,用于数学、科学和工程的库。6、TensorFlow,由Google开发的开源机
- 自然语言处理_tf-idf
_feivirus_
算法机器学习和数学自然语言处理tf-idf逆文档频率词频
importpandasaspdimportmath1.数据预处理docA="Thecatsatonmyface"docB="Thedogsatonmybed"wordsA=docA.split("")wordsB=docB.split("")wordsSet=set(wordsA).union(set(wordsB))print(wordsSet){'on','my','face','sat',
- K近邻算法_分类鸢尾花数据集
_feivirus_
算法机器学习和数学分类机器学习K近邻
importnumpyasnpimportpandasaspdfromsklearn.datasetsimportload_irisfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportaccuracy_score1.数据预处理iris=load_iris()df=pd.DataFrame(data=ir
- LeetCode 53. Maximum Subarray
枯萎的海风
算法与OJC/C++leetcode
1.题目描述Findthecontiguoussubarraywithinanarray(containingatleastonenumber)whichhasthelargestsum.Forexample,giventhearray[−2,1,−3,4,−1,2,1,−5,4],thecontiguoussubarray[4,−1,2,1]hasthelargestsum=6.clicktos
- leetcode-124 Binary Tree Maximum Path Sum
乐观的大鹏
LeetCode
Givenanon-emptybinarytree,findthemaximumpathsum.Forthisproblem,apathisdefinedasanysequenceofnodesfromsomestartingnodetoanynodeinthetreealongtheparent-childconnections.Thepathmustcontainatleastonenodea
- 【LeetCode】53. Maximum Subarray
墨染百城
LeetCodeleetcode
问题描述问题链接:https://leetcode.com/problems/maximum-subarray/#/descriptionFindthecontiguoussubarraywithinanarray(containingatleastonenumber)whichhasthelargestsum.Forexample,giventhearray[-2,1,-3,4,-1,2,1,-
- Vicky的ScalersTalk第六轮新概念朗读持续力训练Day73 20210411
Vicky_b9de
练习材料:ModerncavemenPart-3ˈmɒdənˈkeɪvmənpɑːt-3Theyplungedintothelake,andafterloadingtheirgearonaninflatablerubberdinghy,letthecurrentcarrythemtotheotherside.Toprotectthemselvesfromtheicywater,theyhadtow
- LeetCode 673. Number of Longest Increasing Subsequence (Java版; Meidum)
littlehaes
字符串动态规划算法leetcode数据结构
welcometomyblogLeetCode673.NumberofLongestIncreasingSubsequence(Java版;Meidum)题目描述Givenanunsortedarrayofintegers,findthenumberoflongestincreasingsubsequence.Example1:Input:[1,3,5,4,7]Output:2Explanatio
- 【大模型应用开发 动手做AI Agent】第一轮行动:工具执行搜索
AI大模型应用之禅
计算科学神经计算深度学习神经网络大数据人工智能大型语言模型AIAGILLMJavaPython架构设计AgentRPA
【大模型应用开发动手做AIAgent】第一轮行动:工具执行搜索作者:禅与计算机程序设计艺术/ZenandtheArtofComputerProgramming1.背景介绍1.1问题的由来随着人工智能技术的飞速发展,大模型应用开发已经成为当下热门的研究方向。AIAgent作为人工智能领域的一个重要分支,旨在模拟人类智能行为,实现智能决策和自主行动。在AIAgent的构建过程中,工具执行搜索是至关重要
- 360前端星计划-动画可以这么玩
马小蜗
动画的基本原理定时器改变对象的属性根据新的属性重新渲染动画functionupdate(context){//更新属性}constticker=newTicker();ticker.tick(update,context);动画的种类1、JavaScript动画操作DOMCanvas2、CSS动画transitionanimation3、SVG动画SMILJS动画的优缺点优点:灵活度、可控性、性能
- 大牛:新型电动汽车电池技术问世! 可将电池能量密度提高2倍成本降一半
38cc8b780dc0
据外媒报道,当地时间6月10日,电动汽车电池技术领导者OneDBatterySciences宣布推出一项可为下一代电动汽车电池提供动力的突破性技术——SINANODE。对于电动汽车行业而言,打造含有更多硅的电池一直是一个挑战,而SINANODE无缝集成至现有的生产工艺中,让硅纳米线与商用石墨粉末融合,将电池阳极的能量密度提高了两倍,但是将每kWh的成本降低了一半。能量密度更高可以让电池的续航更长,
- python编写直方图和饼图
2301_80421078
python开发语言
1.直方图#直方图的绘制#语法格式:plt.hist(x,bins),其中x:数据集;bins:统计数据的分布区间importmatplotlib.pyplotaspltimportpandasaspd#导入文件excel=pd.read_excel('成绩.xlsx')#print(excel)#避免乱码plt.rcParams['font.sans-serif']=['SimHei']x=ex
- pythonpandas函数详解_Python pandas常用函数详解
Senvn
本文研究的主要是pandas常用函数,具体介绍如下。1import语句importpandasaspdimportnumpyasnpimportmatplotlib.pyplotaspltimportdatetimeimportre2文件读取df=pd.read_csv(path='file.csv')参数:header=None用默认列名,0,1,2,3...names=['A','B','C'
- python画出分子化学空间分布(UMAP)
Sakaiay
python
利用umap画出分子化学空间分布图安装pipinstallumap-learn下面是用一个数据集举的例子importtorchimportumapimportpandasaspdimportnumpyasnpimportmatplotlib.pyplotaspltimportseabornassnsfromsklearn.manifoldimportTSNEfromrdkit.Chemimport
- 探索创新科技: Lite-Mono - 简约高效的小型化Mono框架
杭律沛Meris
探索创新科技:Lite-Mono-简约高效的小型化Mono框架Lite-Mono[CVPR2023]Lite-Mono:ALightweightCNNandTransformerArchitectureforSelf-SupervisedMonocularDepthEstimation项目地址:https://gitcode.com/gh_mirrors/li/Lite-Mono如果你在寻找一个轻
- 【C#生态园】深度剖析:C#嵌入式开发工具大揭秘
friklogff
C#生态园c#开发语言
C#嵌入式开发:全面了解六大框架与库前言随着物联网和嵌入式系统的快速发展,越来越多的开发者开始关注使用C#语言进行嵌入式开发。本文将介绍几种用于C#的嵌入式开发框架和相关库,以及它们的核心功能、安装配置方法和API概览,帮助读者了解并选择适合自己项目的工具和资源。欢迎订阅专栏:C#生态园文章目录C#嵌入式开发:全面了解六大框架与库前言1.nanoFramework:一个用于C#的嵌入式开发框架1.
- python-pcl函数_Python简介,第4章-函数
cumei1658
javawebglpythonluaios
python-pcl函数Runningthroughthedoor,Baldricfoundhimselfinanenormouscavern,itsceilinglostinshadow.Greatcolumnsofblackstonesoaredfromtheground,andpoolsoflavabubbledthroughout,lightingthecaverninadarkred.T
- PAT Advanced 1015. Reversible Primes (C语言实现)
OliverLew
我的PAT系列文章更新重心已移至Github,欢迎来看PAT题解的小伙伴请到GithubPages浏览最新内容。此处文章目前已更新至与GithubPages同步。欢迎star我的repo。题目Areversibleprimeinanynumbersystemisaprimewhose"reverse"inthatnumbersystemisalsoaprime.Forexampleinthedec
- python读写CSV文件
bcbobo21cn
.Netpython开发语言机器学习CSV
做数据分析,有时候要分析的数据在CSV文件里;先看一下python读写CSV文件;importpandasaspddf=pd.read_csv('test1.csv')print(df)print('')print(df.head(2))companyname=["A1","B2","E3","F4"]legperson=["lier","yanqi","wangwu","zhangsan"]le
- python如何更方便的处理日期和时间
openwin_top
python编程示例系列python编程示例系列二pythonjava前端
Arrow是一个第三方Python库,提供了更加易用和方便的日期和时间处理接口。它的设计目标是提供一种简单、一致且易于使用的API,以替代Python内置的datetime模块。Arrow支持各种日期和时间的操作,包括时区转换、日期和时间格式化、日期和时间差计算等功能。它还支持与其他日期和时间库的互操作,例如datetime、dateutil和pandas等库。以下是一个使用Arrow库的简单示例
- python下载pandas库镜像_下载pandas库
weixin_39791152
背景交代:在下载matplotlib库时,我已经将pip的下载源手动更改为清华的镜像,所以,如果有小伙伴在下载库遇到问题,如timeout,请先将下载源改为国内镜像,具体操作见我的另一篇文章:今天的主题是安装pandas库~首先,按田字格+R,打开cmd,输入:pipinstallpandas嗯,不出所料地报错了……主要原因:pip._vendor.urllib3.exceptions.ReadT
- python数据分析知识点大全
编程零零七
python数据分析python开发语言python数据分析数据分析知识点大全python数据分析知识点python教程python基础
Python数据分析知识点大全可以归纳为以下几个主要方面:一、基础概念与目的数据分析定义:数据分析是指用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论,对数据加以详细研究和概括总结的过程。其目的在于从数据中挖掘规律、验证猜想、进行预测。Python在数据分析中的优势:Python因其易学性、快速开发、丰富的扩展库(如NumPy、Pandas等)和成熟的框架,成为数据分析领域的
- 如何“选择不同的“?跨越 pandas 中的多个数据框列?
潮易
pandas
在pandas中,如果你想要选择不同的列,你可以使用DataFrame的loc属性和iloc属性的组合。loc属性是基于标签的,iloc属性则是基于索引的。如果你想要选择多个列,你只需要将它们放入一个列表即可。以下是一个代码示例:```pythonimportpandasaspd#创建一个数据框df=pd.DataFrame({'A':[1,2,3],'B':[4,5,6],'C':[7,8,9]
- 运算符、一元运算符、自增、自减
玖岁灬
运算符运算符也叫操作符通过运算符可以对一个或多个值进行运算,并获取运算结果比如:typeof就是运算符,可以来获得一个值的类型,它会将该值的类型以字符串的形式返回"number""string""boolean""undefined""object"算数运算符当对非Number类型的值进行运算时,会将这些值转换为Number然后在运算任何值和NaN做运算都得NaN++可以对两个值进行加法运算,并将
- 详解 Pandas 的 query 函数
文刀小桂
Pandaspandaspython开发语言
Pandas的query()方法能够使用字符串表达式来筛选DataFrame数据的行,类似于SQL的where子句importpandasaspddf=pd.DataFrame({"A":[1,3,5,6,7],"B":[11,10,9,8,12],"C":["hello","pandas","python","java","shell"],"D":["2024-02-01","2023-12-1
- 详解 Pandas 的 isin 用法
文刀小桂
Pandaspandaspython
Pandas的isin()方法可以判断数据值是否在某个数据集合中,若与集合中的某个值相等则返回True,反之返回False。importpandasaspddf=pd.DataFrame({"title":["one","two","three","four"],"type":["small","common","middle","large"],"num":[10,20,30,40]})#1.判
- Rust: duckdb和polars读csv文件比较
songroom
rust开发语言后端
duckdb在数据分析上,有非常多不错的特质。1、快;2、客户体验好,特别是可以同时批量读csv(在一个目录下的csv等文件)。polars的性能比pandas有非常多的超越。但背后的一些基于arrow的技术栈有很多相同之类。今天想比较一下两者在csv数据读写的情况。一、文件准备csv样本内容,是N行9列的csv标准格式,有字符串,有浮点数,有整型。具体如下:本次准备了两个csv文件,一个大约是2
- 关于旗正规则引擎中的MD5加密问题
何必如此
jspMD5规则加密
一般情况下,为了防止个人隐私的泄露,我们都会对用户登录密码进行加密,使数据库相应字段保存的是加密后的字符串,而非原始密码。
在旗正规则引擎中,通过外部调用,可以实现MD5的加密,具体步骤如下:
1.在对象库中选择外部调用,选择“com.flagleader.util.MD5”,在子选项中选择“com.flagleader.util.MD5.getMD5ofStr({arg1})”;
2.在规
- 【Spark101】Scala Promise/Future在Spark中的应用
bit1129
Promise
Promise和Future是Scala用于异步调用并实现结果汇集的并发原语,Scala的Future同JUC里面的Future接口含义相同,Promise理解起来就有些绕。等有时间了再仔细的研究下Promise和Future的语义以及应用场景,具体参见Scala在线文档:http://docs.scala-lang.org/sips/completed/futures-promises.html
- spark sql 访问hive数据的配置详解
daizj
spark sqlhivethriftserver
spark sql 能够通过thriftserver 访问hive数据,默认spark编译的版本是不支持访问hive,因为hive依赖比较多,因此打的包中不包含hive和thriftserver,因此需要自己下载源码进行编译,将hive,thriftserver打包进去才能够访问,详细配置步骤如下:
1、下载源码
2、下载Maven,并配置
此配置简单,就略过
- HTTP 协议通信
周凡杨
javahttpclienthttp通信
一:简介
HTTPCLIENT,通过JAVA基于HTTP协议进行点与点间的通信!
二: 代码举例
测试类:
import java
- java unix时间戳转换
g21121
java
把java时间戳转换成unix时间戳:
Timestamp appointTime=Timestamp.valueOf(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date()))
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd hh:m
- web报表工具FineReport常用函数的用法总结(报表函数)
老A不折腾
web报表finereport总结
说明:本次总结中,凡是以tableName或viewName作为参数因子的。函数在调用的时候均按照先从私有数据源中查找,然后再从公有数据源中查找的顺序。
CLASS
CLASS(object):返回object对象的所属的类。
CNMONEY
CNMONEY(number,unit)返回人民币大写。
number:需要转换的数值型的数。
unit:单位,
- java jni调用c++ 代码 报错
墙头上一根草
javaC++jni
#
# A fatal error has been detected by the Java Runtime Environment:
#
# EXCEPTION_ACCESS_VIOLATION (0xc0000005) at pc=0x00000000777c3290, pid=5632, tid=6656
#
# JRE version: Java(TM) SE Ru
- Spring中事件处理de小技巧
aijuans
springSpring 教程Spring 实例Spring 入门Spring3
Spring 中提供一些Aware相关de接口,BeanFactoryAware、 ApplicationContextAware、ResourceLoaderAware、ServletContextAware等等,其中最常用到de匙ApplicationContextAware.实现ApplicationContextAwaredeBean,在Bean被初始后,将会被注入 Applicati
- linux shell ls脚本样例
annan211
linuxlinux ls源码linux 源码
#! /bin/sh -
#查找输入文件的路径
#在查找路径下寻找一个或多个原始文件或文件模式
# 查找路径由特定的环境变量所定义
#标准输出所产生的结果 通常是查找路径下找到的每个文件的第一个实体的完整路径
# 或是filename :not found 的标准错误输出。
#如果文件没有找到 则退出码为0
#否则 即为找不到的文件个数
#语法 pathfind [--
- List,Set,Map遍历方式 (收集的资源,值得看一下)
百合不是茶
listsetMap遍历方式
List特点:元素有放入顺序,元素可重复
Map特点:元素按键值对存储,无放入顺序
Set特点:元素无放入顺序,元素不可重复(注意:元素虽然无放入顺序,但是元素在set中的位置是有该元素的HashCode决定的,其位置其实是固定的)
List接口有三个实现类:LinkedList,ArrayList,Vector
LinkedList:底层基于链表实现,链表内存是散乱的,每一个元素存储本身
- 解决SimpleDateFormat的线程不安全问题的方法
bijian1013
javathread线程安全
在Java项目中,我们通常会自己写一个DateUtil类,处理日期和字符串的转换,如下所示:
public class DateUtil01 {
private SimpleDateFormat dateformat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public void format(Date d
- http请求测试实例(采用fastjson解析)
bijian1013
http测试
在实际开发中,我们经常会去做http请求的开发,下面则是如何请求的单元测试小实例,仅供参考。
import java.util.HashMap;
import java.util.Map;
import org.apache.commons.httpclient.HttpClient;
import
- 【RPC框架Hessian三】Hessian 异常处理
bit1129
hessian
RPC异常处理概述
RPC异常处理指是,当客户端调用远端的服务,如果服务执行过程中发生异常,这个异常能否序列到客户端?
如果服务在执行过程中可能发生异常,那么在服务接口的声明中,就该声明该接口可能抛出的异常。
在Hessian中,服务器端发生异常,可以将异常信息从服务器端序列化到客户端,因为Exception本身是实现了Serializable的
- 【日志分析】日志分析工具
bit1129
日志分析
1. 网站日志实时分析工具 GoAccess
http://www.vpsee.com/2014/02/a-real-time-web-log-analyzer-goaccess/
2. 通过日志监控并收集 Java 应用程序性能数据(Perf4J)
http://www.ibm.com/developerworks/cn/java/j-lo-logforperf/
3.log.io
和
- nginx优化加强战斗力及遇到的坑解决
ronin47
nginx 优化
先说遇到个坑,第一个是负载问题,这个问题与架构有关,由于我设计架构多了两层,结果导致会话负载只转向一个。解决这样的问题思路有两个:一是改变负载策略,二是更改架构设计。
由于采用动静分离部署,而nginx又设计了静态,结果客户端去读nginx静态,访问量上来,页面加载很慢。解决:二者留其一。最好是保留apache服务器。
来以下优化:
- java-50-输入两棵二叉树A和B,判断树B是不是A的子结构
bylijinnan
java
思路来自:
http://zhedahht.blog.163.com/blog/static/25411174201011445550396/
import ljn.help.*;
public class HasSubtree {
/**Q50.
* 输入两棵二叉树A和B,判断树B是不是A的子结构。
例如,下图中的两棵树A和B,由于A中有一部分子树的结构和B是一
- mongoDB 备份与恢复
开窍的石头
mongDB备份与恢复
Mongodb导出与导入
1: 导入/导出可以操作的是本地的mongodb服务器,也可以是远程的.
所以,都有如下通用选项:
-h host 主机
--port port 端口
-u username 用户名
-p passwd 密码
2: mongoexport 导出json格式的文件
- [网络与通讯]椭圆轨道计算的一些问题
comsci
网络
如果按照中国古代农历的历法,现在应该是某个季节的开始,但是由于农历历法是3000年前的天文观测数据,如果按照现在的天文学记录来进行修正的话,这个季节已经过去一段时间了。。。。。
也就是说,还要再等3000年。才有机会了,太阳系的行星的椭圆轨道受到外来天体的干扰,轨道次序发生了变
- 软件专利如何申请
cuiyadll
软件专利申请
软件技术可以申请软件著作权以保护软件源代码,也可以申请发明专利以保护软件流程中的步骤执行方式。专利保护的是软件解决问题的思想,而软件著作权保护的是软件代码(即软件思想的表达形式)。例如,离线传送文件,那发明专利保护是如何实现离线传送文件。基于相同的软件思想,但实现离线传送的程序代码有千千万万种,每种代码都可以享有各自的软件著作权。申请一个软件发明专利的代理费大概需要5000-8000申请发明专利可
- Android学习笔记
darrenzhu
android
1.启动一个AVD
2.命令行运行adb shell可连接到AVD,这也就是命令行客户端
3.如何启动一个程序
am start -n package name/.activityName
am start -n com.example.helloworld/.MainActivity
启动Android设置工具的命令如下所示:
# am start -
- apache虚拟机配置,本地多域名访问本地网站
dcj3sjt126com
apache
现在假定你有两个目录,一个存在于 /htdocs/a,另一个存在于 /htdocs/b 。
现在你想要在本地测试的时候访问 www.freeman.com 对应的目录是 /xampp/htdocs/freeman ,访问 www.duchengjiu.com 对应的目录是 /htdocs/duchengjiu。
1、首先修改C盘WINDOWS\system32\drivers\etc目录下的
- yii2 restful web服务[速率限制]
dcj3sjt126com
PHPyii2
速率限制
为防止滥用,你应该考虑增加速率限制到您的API。 例如,您可以限制每个用户的API的使用是在10分钟内最多100次的API调用。 如果一个用户同一个时间段内太多的请求被接收, 将返回响应状态代码 429 (这意味着过多的请求)。
要启用速率限制, [[yii\web\User::identityClass|user identity class]] 应该实现 [[yii\filter
- Hadoop2.5.2安装——单机模式
eksliang
hadoophadoop单机部署
转载请出自出处:http://eksliang.iteye.com/blog/2185414 一、概述
Hadoop有三种模式 单机模式、伪分布模式和完全分布模式,这里先简单介绍单机模式 ,默认情况下,Hadoop被配置成一个非分布式模式,独立运行JAVA进程,适合开始做调试工作。
二、下载地址
Hadoop 网址http:
- LoadMoreListView+SwipeRefreshLayout(分页下拉)基本结构
gundumw100
android
一切为了快速迭代
import java.util.ArrayList;
import org.json.JSONObject;
import android.animation.ObjectAnimator;
import android.os.Bundle;
import android.support.v4.widget.SwipeRefreshLayo
- 三道简单的前端HTML/CSS题目
ini
htmlWeb前端css题目
使用CSS为多个网页进行相同风格的布局和外观设置时,为了方便对这些网页进行修改,最好使用( )。http://hovertree.com/shortanswer/bjae/7bd72acca3206862.htm
在HTML中加入<table style=”color:red; font-size:10pt”>,此为( )。http://hovertree.com/s
- overrided方法编译错误
kane_xie
override
问题描述:
在实现类中的某一或某几个Override方法发生编译错误如下:
Name clash: The method put(String) of type XXXServiceImpl has the same erasure as put(String) of type XXXService but does not override it
当去掉@Over
- Java中使用代理IP获取网址内容(防IP被封,做数据爬虫)
mcj8089
免费代理IP代理IP数据爬虫JAVA设置代理IP爬虫封IP
推荐两个代理IP网站:
1. 全网代理IP:http://proxy.goubanjia.com/
2. 敲代码免费IP:http://ip.qiaodm.com/
Java语言有两种方式使用代理IP访问网址并获取内容,
方式一,设置System系统属性
// 设置代理IP
System.getProper
- Nodejs Express 报错之 listen EADDRINUSE
qiaolevip
每天进步一点点学习永无止境nodejs纵观千象
当你启动 nodejs服务报错:
>node app
Express server listening on port 80
events.js:85
throw er; // Unhandled 'error' event
^
Error: listen EADDRINUSE
at exports._errnoException (
- C++中三种new的用法
_荆棘鸟_
C++new
转载自:http://news.ccidnet.com/art/32855/20100713/2114025_1.html
作者: mt
其一是new operator,也叫new表达式;其二是operator new,也叫new操作符。这两个英文名称起的也太绝了,很容易搞混,那就记中文名称吧。new表达式比较常见,也最常用,例如:
string* ps = new string("
- Ruby深入研究笔记1
wudixiaotie
Ruby
module是可以定义private方法的
module MTest
def aaa
puts "aaa"
private_method
end
private
def private_method
puts "this is private_method"
end
end