alter table add partition ... location ...语法
目录
结论
建表语句
create table `wxtest`(
`groupId` string,
`uuid` string,
`userId` string,
`dt_index` string)
partitioned by(
`dt` string,
`projId` string)
row format delimited
fields terminated by '\t';添加两个分区
insert into table wxtest partition(dt='20190621' , projId='111') values('a1','b1','c1','d1');
insert into table wxtest partition(dt='20190622' , projId='112') values('a2','b2','c2','d2');查询数据如下:
hive> select * from wxtest;
OK
a1 b1 c1 d1 20190621 111
a2 b2 c2 d2 20190622 112下面是测试语法:
alter table wxtest add if not exists partition(dt='test1',projId='test2')
location '/home/hdp_teu_dpd/resultdata/wmda/terra/group/group_user_list/test1/test2';然后往新分区里插入数据:
insert into table wxtest partition(dt='test1' , projId='test2') values('a3','b3','c3','d3');然后查询hive表,发现hive表中是可以看到新分区(dt='test1' , projId='test2')的数据
hive> select * from wxtest;
OK
a1 b1 c1 d1 20190621 111
a2 b2 c2 d2 20190622 112
a3 b3 c3 d3 test1 test2但是hive表的HDFS存储路径下,并没有该分区的信息,只有两个原始分区的数据

查询sql语句中,location后的路径,发现该分区数据跑这来了
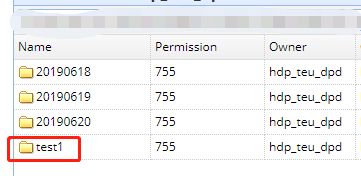
然后再往hive表中添加一个新分区数据:
insert into table wxtest partition(dt='20190619' , projId='113') values('a4','b4','c4','d4');发现该分区数据依然在hive表原始路径下
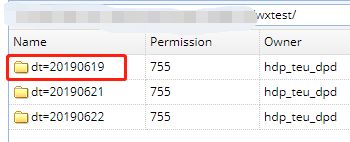
得出结论:
alter table add if not exists partition....location....
这种语法,只是将hive表的新分区换了一个路径,该新分区数据不在hive表原始HDFS路径下,
同时也不影响hive中后续添加分区,依然处于原始路径下