Self-attention GAN
SAGAN是基于注意力机制的长期范围的生成模型(这里的长期范围是说能够兼顾更多的视野域)。传统的卷积GAN生成高分辨率细节,以低分辨率特征图中的空间局部点作为方法。【应该是卷积带来的负面影响】SAGAN可以利用所有的特征位置上生成细节。鉴别器可以检查偏远部分的高细节特征是否一致。【这个翻译也是很懵逼】最近 的论文都显示了生成条件影响GAN的性能。利用这一点,我们使用了谱归一化,的确能够提高GAN的性能。对attention层进行可视化,可以发现生成器利用的是和物体形状有关的点,而不是某些固定的局部的点。
引言
图片生成是一个很重要的计算机可视化问题。随着GAN的提出,生成图片有着很大的进步,尽管有很多问题仍然存在。基于深度卷积的GAN很成功,然而仔细检查基于深度卷积GAN的生成图片,在多个类别数据集下,一些类别的生成质量不如其他类别的生成质量。比如最先进的ImageNet GAN模型合成的图像有结构限制(比如海,陆地等类别),它生成纹理特征比生成几何特征更加优秀,它不能捕捉到经常出现的一些几何或者结构模式(例如狗虽然生成虽然纹理生动,但是少了一只脚)。一种可能的解释是之前的模型严重依赖卷积网络对图片区域的相关性进行建模。由于卷积网有视野域,大范围的结构需要跨越几个卷积网。由于种种原因,这会影响模型学习到物体结构:小模型是不能表达这个关系的(结构关系),优化算法很难找到那些能够弥补结构缺失的参数,并且那些参数敏感,无法提前设置。增加卷积核的size虽然能够增加视野,但是不仅减弱了卷积表达,而且增加了计算复杂度。Self-Attention是一个比较的方法,平衡了大范围结构和计算统计效率。Self-Attention计算每个位置的响应,使用加权特征和的方式,权重或者注意力向量的计算是简单的。
我们的工作是将self-attention机制引入到条件GANs中。注意力模块是对卷积的补充,帮助卷积对大范围多层次跨图像区域的依赖关系建模(注意力模块对整体结构进行把握)。使用了self-attention机制,生成器抽取图像特征,可以将局部的细节和遥远部分的细节信息相互关联。另外鉴别器也能更好的进行全局图片结构的判断。(这里没有说鉴别器是否使用了注意力机制)。
对于self-attention机制,我们结合了对条件对GAN的影响的一些研究。研究显示条件比较好的生成器的性能比较好。我们建议加强使用谱归一化的GANs的条件变量,谱归一化技术以前被用在鉴别器上。
我们也进行实验,验证我们注意力机制的想法和稳定方式。
相关工作
Attention Model 注意力机制. 注意力机制已经成为很多模型的重要的组成部分 ,以来获得全局依赖(这个应该指的在GAN中的应用)。注意力机制通过一个序列中所有元素和它的位置,来计算某个位置的响应。使用这个技术,机器翻译能够达到很好的水平。Parmar等在自回归模型中应用自注意力机制进行图像产生。Wang等将自注意力机制形式化为序列的空间时间依赖,处理视频数据。除了这些进步,GANs中没有单独的进行self-attention机制的探索(AttenGAN中的self-attention是对文本数据的处理,在模型尼内部没有使用self-attention)。SAGAN探索self-attention在GANs内部,寻找长范围依赖。
SAGAN
现在大部分生成图像的GAN模型都是使用的卷积结构。卷积处理图像信息都是局部的,因此卷积网单独无法处理长范围依赖关系建模。在这里,我们对非局部模型进行改进,引入self-attention到GANs框架中,得到的生成器和鉴别器能够处理更宽泛的图片区域。
自注意力的实现
[下面只是翻译,以便以后查阅]
来自于之前隐藏层的图片特征x,为了计算注意力,x首先被转化到两个特征空间f、g:f(x) = WfX、g(x) = WgX。
 B(i,j)表示当获得或者生成第j个像素的特征时,模型对第i个位置的关注程度。其中,C是通道数,N=WH。注意力层的输出是o = (o1 , o2, …, oj , …, oN ) ∈RC×N 。
B(i,j)表示当获得或者生成第j个像素的特征时,模型对第i个位置的关注程度。其中,C是通道数,N=WH。注意力层的输出是o = (o1 , o2, …, oj , …, oN ) ∈RC×N 。
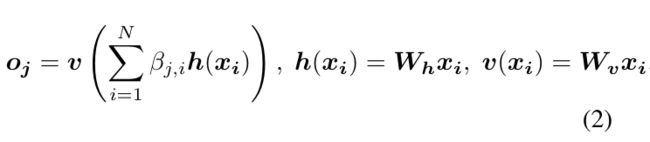 Wg,Wf,Wv,Wh都是学习到的权重矩阵,是由11的卷积核生成。
Wg,Wf,Wv,Wh都是学习到的权重矩阵,是由11的卷积核生成。
我们将注意力层的输出乘以一个比例,重新加入特征图。
![]() 其中r变量是一个可以学习到的变量,它被初始化为0。引入的r可以允许首先依靠附近区域提供信息线索,因为这很容易,之后逐渐的分配更多的权重给非局部区域。这种做法的理由很直白:首先学习简单的任务,然后逐渐的加大难度。我们将注意力模块应用在鉴别器和生成器中,然后通过hinge loss进行迭代优化:
其中r变量是一个可以学习到的变量,它被初始化为0。引入的r可以允许首先依靠附近区域提供信息线索,因为这很容易,之后逐渐的分配更多的权重给非局部区域。这种做法的理由很直白:首先学习简单的任务,然后逐渐的加大难度。我们将注意力模块应用在鉴别器和生成器中,然后通过hinge loss进行迭代优化:

稳定方法
Miyato提出的稳定训练的方式是在鉴别器上应用谱归一化,通过约束谱范数达到Lipschitz约束。相比较于,其他的标准化方式,谱归一化不需要额外的超参数进行微调(实际上,设置所有层的谱归一化权重为1),并且这个计算代价很小。
我们认为生成器也能使用这个方法,最近的一个文献指出生成器的条件设置对于GANs的性能有很大关联度的。在生成器上的谱归一化能够防止参数过大和梯度异常。生成器和鉴别器都使用谱归一化能够让每次更新生成器后,更少的更新鉴别器,因此它可以减少很多的计算训练。这个方法也让训练更加稳定。
生成器和鉴别器不平衡的学习率
之前的工作发现,鉴别器的正则化减慢了GANs的学习过程,实际上,使用了正则化的鉴别器在每次更新生成器之后,需要更多次的更新鉴别器。Hausel等人对生成器和鉴别器使用不同的学习率(TTUR)。因此我们也建议那么做,来弥补正则化带来的问题。
实验
实验是在ImageNet2012上进行验证,5.1节是验证我们提出的两个稳定GANs训练的方法,5.2节是我们自己的SAGAN的实验,5.3节是SAGAN和现在最顶尖的几个方法的比较。模型在4个GPU上训练了两周,使用的是SGD优化。
验证的度量:我们是用的是IS和FID两个指标。虽然有一些其他的方案,不过其他方案的应用不是很广泛。IS是计算条件分布和边缘分布的散度。IS的分数越高,说明生成质量越好(有关于IS的知识在另外一篇博客上)。IS的应用更加的广泛。IS也有很严重的限制,它只是确保生成图片在InceptionNet的分类极度靠近某个类别,并且图片来自于很多类别,但是它不能体现图片的生成细节,并且无法验证类的内在分布(生成类别的分布和真实类别的图片分布)。【对FID的一个综合的评价和简介】
网络结构和实现细节:SAGAN生成128*128的图片。谱归一化被用在生成器和鉴别器的所有层上。所有模型使用动量优化。鉴别器和生成器的学习率分别是0.0004和0.00001。
5.1 验证稳定措施
这一节验证了实验措施的稳定性,比如SN(spectral normal)和TTUR(不平衡速率)。
5.2 自注意力模型
为了探索自注意力机制的有效性,我们将这个机制加入到生成器和鉴别器的不同阶段。
笔记
以上呢,都是翻译,部分内容的理解给予了链接,下面主要记录自己的理解:
自注意力机制的实现
这篇知乎【https://zhuanlan.zhihu.com/p/55741364】给予我很大 的帮助。我自己也是看了很久才明白自注意力机制的实现,并且尝试转化为自己的东西:
原文中是这样做的:
首先,将input 的x变现为 CN,N=HW,也就相当于Xi 表示的是第 i 个元素的特征(1C):
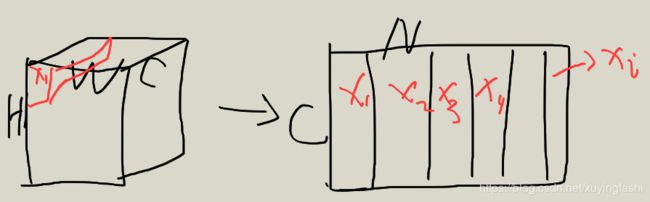 请原谅我这拙劣的画技,但意思就是这个意思。这一点理解很重要,很多方法都是那么理解的,C的通道是这个位置的特征,不要被“通道”(channel)这次词迷惑了,那只是术语。
请原谅我这拙劣的画技,但意思就是这个意思。这一点理解很重要,很多方法都是那么理解的,C的通道是这个位置的特征,不要被“通道”(channel)这次词迷惑了,那只是术语。
然后,f(x)=Wf×X, g(x)=Wg×X【这个符号需要修正】,它使用一个11的通道数为C’卷积核对X进行卷积,获得新的空间下两个特征图:
 g也是这个操作,这样就可以获得两个不同空间下的特征图,这一点没有什么,其实就是两个特征。
g也是这个操作,这样就可以获得两个不同空间下的特征图,这一点没有什么,其实就是两个特征。
 这个公式的理解是这样的:s(i,j)是第i个像素对第j个像素的关联程度:
这个公式的理解是这样的:s(i,j)是第i个像素对第j个像素的关联程度:
 我解释一下这幅灵魂画作:s表示的第i个像素和第j个像素的一个线性乘积,B(i,j)是s(i,j)/sum_i(i,j),所有的f和gj之间的线性乘积与fi和gj之间比值。也就是第j个元素相对于其他元素的关联程度([0,1]之间)。
我解释一下这幅灵魂画作:s表示的第i个像素和第j个像素的一个线性乘积,B(i,j)是s(i,j)/sum_i(i,j),所有的f和gj之间的线性乘积与fi和gj之间比值。也就是第j个元素相对于其他元素的关联程度([0,1]之间)。
这个关联值怎么运用的?
和g,f一样的手法,得到h,然后按照关联程度,加权相加,再进行转换到C通道大小的空间:
 很开心,在放一张丑图:
很开心,在放一张丑图:
 将B(i,1)和每一个h(i)相乘,然后相加,获得成比例的新特征,再经过特征变换。
将B(i,1)和每一个h(i)相乘,然后相加,获得成比例的新特征,再经过特征变换。
那篇知乎给予的代码稍稍微微 有点问题,并且key和value的说法,我觉的说不过去,个人看法,毕竟我还年轻,刚入门。