Stateful Functions 2.0 基于Apache Flink的事件驱动数据库
Stateful Functions 2.0 基于Apache Flink的事件驱动数据库
原文:https://flink.apache.org/news/2020/04/07/release-statefun-2.0.0.html#event-driven-database-vs-requestresponse-database
应用流式处理的事件驱动应用替换CRUD数据库应用
2020-4-7, Apache Flink 团队,宣布了Stateful Functions (StateFun) 2.0正式发布--Stateful Functions第一次作为Apache Flink项目一部分的发布。这是个巨大的里程碑: Stateful Functions 2.0不仅仅是一个API升级,而是基于第一版基于Apache Flink之上构建的事件驱动数据库(event-driven database)。
Stateful Functions 2.0 使有状态性和弹性有效的结合在一起,实现了类似AWS Lambada和Kubernetes资源编排工具的快速缩放/缩放到零以及滚动升级的特性。
通过这些特性, Stateful Functions 2.0有效的解决了FaaS被诟病的两个缺点:状态一致性和函数间消息交换效率。
事件驱动数据库
Stateful Functions年初刚加入Apache Flink时,这个项目作为基于Flink的类库,用于构建通用的事件驱动应用。用可以实现接受和发送消息的函数,并且管理持久化的变量状态。Flink提供了一个高效的exactly-once状态和消息的基础运行时。Stateful Functions 1.0受到FaaS的启发,结合了流式处理和Actor编程。
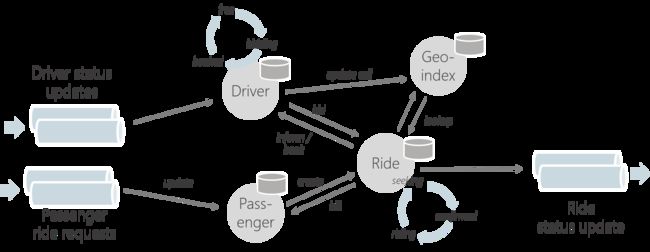
在2.0版本中,Stateful Functions已经从Flink与JVM中解耦出来,只需通过服务调用他们。这可以使在Faas平台,K8S部署或其他(微)服务上运行函数变为可行。
Flink根据接收的事件通过HTTP或gRPC调用函数,并提供状态访问。系统保证每个实体在任何状态下仅会被消费一次,这样通过隔离保证了状态一致性。通过提供状态访问作为函数的一部分,函数本身可以被当做无状态的,函数的管理变得更为简单,并且带来了快速缩放,缩放到零,无缝滚动升级等优点。
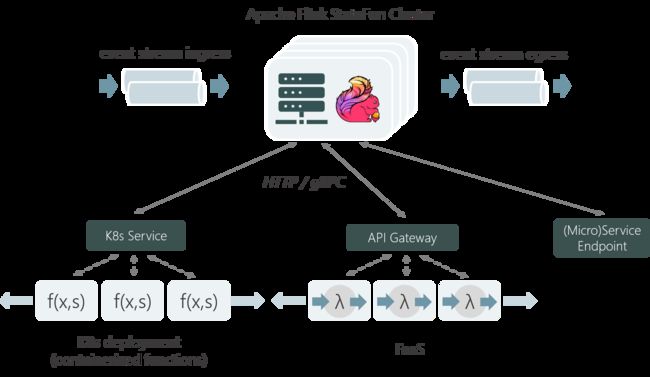
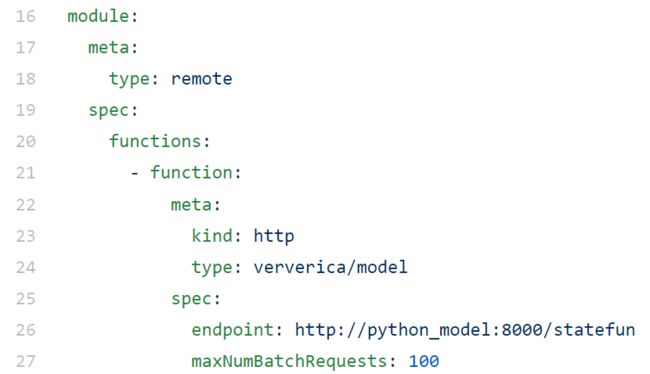
函数可以用任何能处理HTTP请求或者启动gRPC服务的编程语言。StateFun project 包含了一个轻量级的Python SDK,它能处理请求并分发到声明的函数。我们的目标是微诶其他语言提供想死的SDK,如Go,JavaScript或者Rust。用户无需写任何Flink代码(或是JVM代码)。数据的输入、输出和函数入口可以通过YAML规范定义。

Flink进程(Flink JVM)不必执行任何用户代码,当然为了优化应用程序性能也可以通过Embedded Functions使用进程。Flink中只需要保存函数的状态并提供函数间消息传递的消息面,小心地分发这些消息/调用事件驱动函数,并保证一致性。而无需执行用户应用特定的数据流。
实际上,Flink取代了数据库的角色,但是它更适用于事件驱动的函数和服务。它通过集成状态存储,保证了函数或服务间传递消息的有状态性。因此,Stateful Functions 2.0也可以被当做基于Apache Flink的事件驱动数据库。
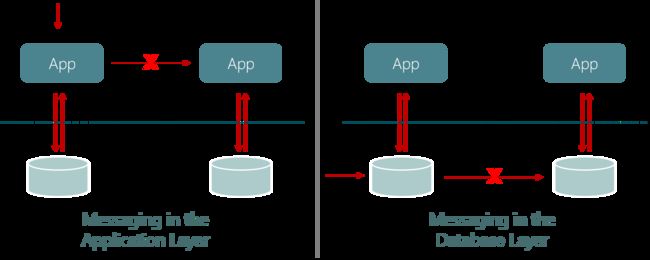
事件驱动数据库与请求/响应数据库的对比
在传统的数据库或者Key/Value存储(这里称之为请求/响应数据库)中,应用需主动发送一个查询到数据库(如SQL via JDBC,GET/PUT via HTTP)。然而,在StateFun这类事件驱动数据库中,这个关系被反转了:数据库根据到达的消息来调用函数或服务。这个特性非常适合FaaS或者事件驱动架构的应用。
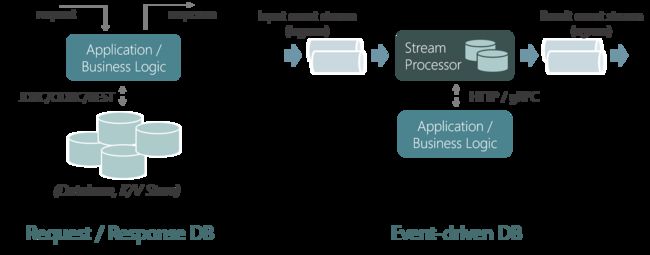
基于请求/响应数据库的应用中,数据库只负责保存状态。函数或服务间的通讯通常一个独立的服务层进行处理。相反,事件驱动数据库以紧密集成的方式既保存了状态的存储,又承担了消息的传输。
与Actor编程模型类似,状态函数使用了可寻址实体(addressable entities)的概念,这里的实体被定义为一类具有唯一ID的函数。这些可寻址实体拥有这些状态,它是也消息传递的目标。与Actor系统不同的是这些应用逻辑在系统外部,可寻址实体也不在物理内存中存储,而是Flink中管理的状态。
状态和一致性
事件驱动数据库除了满足了无状态应用和FaaS的需求,同时也简化了一致性状态的管理。
想想以下这个例子,一个具有两个入口的的应用,如两个微服务(Service1, Service2)。Service1被调用更新了数据库中的状态,同时发送请求到Service2。 假设这个调用请求失败。 那么通常情况下,Service1很难知道Service2是否正确的处理并更新了它的状态。为了解决这个问题,我们引入了很多种技术,如保证服务的幂等性或者重试机制,使用commit/rollback协议,或者其他外部事务调度系统。在应用层解决这些问题就已经足够复杂了,如果再引入数据库到这些场景中,应用将变得难以维护。
同样的场景中,事件驱动数据库承担了状态管理和消息传递的责任,以上问题变得很容易解决。假设数据库的一个分片接收到了初始的消息,并更新了它的状态,调用了Service1,并将处理过的消息路由到了另外一个分片,它将被分发到Service2。如果这个消息在传输过程中发生错误,它可能传输失败或成功,然后我们并不能确定。因为数据库负责状态管理和消息传递,它可以提供通用的解决方案来保证两个数据的一致性,例如通过事务或者consistent snapshots。应用的函数是无状态的,他们的调用没有任何副作用,这也就意味着我们可以重复调用它们,而不用担心一致性问题。
这也是过去几年中,我们从流式处理技术开发过程中总结的宝贵经验:状态的访问与更新必须与消息传递进行集成。它在状态访问和计算瓶颈等场景中带给你一致性,可扩展性和反压性。
尽管状态管理和计算任务被物理的切割开,调度和分发的函数调用依然被集成在状态管理中,也就是说为了保证一致性,它们的物理位置相同。
Remote, Co-located or Embedded Functions
函数可以根据应用的耦合性,独立扩展性和性能开销以不同的方式部署。每个函数模块都可以不同,一些函数可以远程运行,而另外一些可以使用嵌入式运行。
远程函数(Remote Functions)
远程函数是上文中主要讨论的方式,函数被部署在Flink集群之外。状态管理和消息传递层(如Flink进程)和函数层都被可以被单独部署与缩放。所有函数通过远程服务终结点进行远程调用。

与数据库提供标准化协议(如ODBC/JDBC等传统关系数据,基于REST的Key/value存储)访问类似,StateFun 2.0通过一个基于HTTP或gRPC的标准协议调用函数和服务。
本地函数(Co-located Functions)
另外一种部署方式被称为Co-located Functions,函数被运行在与Flink JVM相同的位置。在这种模式下,每个Flink TaskMananger只与“临近”的函数通信。一个通用的方式就是使用K8S类似的系统将Flink容器和函数容器定义在同一个POD下,它们通过pod的本地网络进行通信。
这个模式支持不同的编程语言,同时避免了通过服务/网关/负载均衡进行调用,但是无法将状态和计算单元独立的缩放。
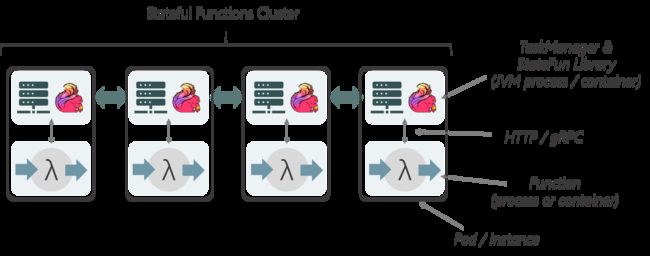
这个部署模式类似于 Apache Beam’s的适配层和Flink的Python API,他们被部署在无需JVM运行时的环境中。
嵌入式函数(Embedded Functions)
嵌入式函数是Stateful Functions 1.0支持的模式,支持Flink的 Java/Scala流式处理API。函数被部署在JVM中,并消息可以直接调用和访问状态。这是最高效的方式,然而仅允许JVM支持语言。

以数据库作为类比, 嵌入式函数有点像存储过程, 然而更严格的讲:这里的函数是实现了标准接口的Java/Scala/Kotlin函数。
加载数据到数据库
当构建一个有状态应用时,通常不会从一个完全空的数据库开始。通常,应用有它的初始状态,例如一个“bootstrap”状态,或者恢复前一个版本的状态。当使用数据库时,我们可以简单的批量加载这些数据。
同样的步骤可以通过包含初始状态的Flink的savepoint实现。Savepoints是分布流式处理应用的状态快照,将它传进Flink后,Flink可以这个状态进行恢复。可以把它们当做数据库转储文件,但是是一个分布式分布式流处理数据库。在StateFun例子中,savepoint包含了函数的状态。
如果需要创建Stateful Functions程序的savepoint,请查看StateFun 2.0的 State Bootstrapping API。State Bootstrapping API当前使用了Flink的DataSet API,下一版本中我们计划提供SQL支持。
Try it out and get involved!
We hope that we could convey some of the excitement we feel about Stateful Functions. If we managed to pique your curiosity, try it out — for example, starting with this walkthrough.
The project is still in a comparatively early stage, so if you want to get involved, there is lots to work on: SDKs for other languages (e.g. Go, JavaScript, Rust), ingresses/egresses and tools for testing, among others.
To follow the project and learn more, please check out these resources:
Code: https://github.com/apache/flink-statefun Docs: https://ci.apache.org/projects/flink/flink-statefun-docs-release-2.0/ Apache Flink project site: https://flink.apache.org/ Apache Flink on Twitter: @ApacheFlink Stateful Functions Webpage: https://statefun.io Stateful Functions on Twitter: @StateFun_IO Thank you!
Thank you!
The Apache Flink community would like to thank all contributors that have made this release possible:
David Anderson, Dian Fu, Igal Shilman, Seth Wiesman, Stephan Ewen, Tzu-Li (Gordon) Tai, hequn8128