【深度学习入门】Paddle实现车辆检测和车辆类型识别(基于YOLOv3和ResNet18)
Paddle实现车辆检测和车辆类型识别(基于YOLOv3和ResNet18)
- 一. PaddleDetection 简介:
- 二. 配置环境并安装 Paddle:
- 三. 安装 PaddleDetetion:
- 四. 调试 YOLOv3 代码:
- 五. YOLO 系列算法详解:
- YOLOv1:
- YOLOv2:
- YOLOv3:
- 六. 检测自己的数据:
- 测试图片:
- 测试视频:
- 七. 使用 X2Paddle 进行模型转换:
- 八. 总结:
今天我们使用 Paddle 开源的两个工具:PaddleDetection 和 X2Paddle 来进行一个车辆检测和类型识别的小demo~
源码地址:https://github.com/Sharpiless/yolov3-vehicle-detection-paddle
最终的检测效果如图:

一. PaddleDetection 简介:
源码地址:https://github.com/PaddlePaddle/PaddleDetection
官方文档:https://paddledetection.readthedocs.io/
PaddleDetection 创立的目的是为工业界和学术界提供丰富、易用的目标检测模型。不仅性能优越、易于部署,而且能够灵活的满足算法研究的需求。

简而言之就是,该工具使用百度开源的 Paddle 框架,集成了多种图像识别和目标检测框架,并且提供了相应的训练、推理和部署工具,使得用户可以自己 DIY 数据集和模型细节,实现深度学习落地应用的快速部署。
特点:
-
易部署:PaddleDetection的模型中使用的核心算子均通过C++或CUDA实现,同时基于PaddlePaddle的高性能推理引擎可以方便地部署在多种硬件平台上。
-
高灵活度:PaddleDetection通过模块化设计来解耦各个组件,基于配置文件可以轻松地搭建各种检测模型。
-
高性能:基于PaddlePaddle框架的高性能内核,在模型训练速度、显存占用上有一定的优势。例如,YOLOv3的训练速度快于其他框架,在Tesla V100 16GB环境下,Mask-RCNN(ResNet50)可以单卡Batch Size可以达到4 (甚至到5)。
支持的主流模型包括:
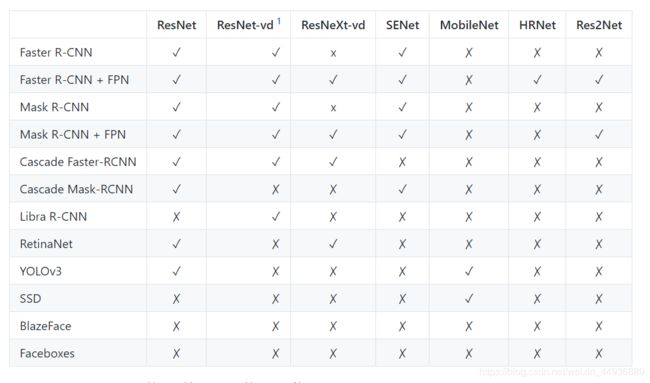
并且支持多种拓展特性:

该工具使得开发者只需修改相应的 yml 格式参数文件,即可一键 DIY 并训练自己的模型:
二. 配置环境并安装 Paddle:
(本机配置:1050Ti,CUDA10.0)
安装 anaconda:
创建 python 环境:
conda create -n paddle_env python=3.6
- 1
激活环境:
conda activate paddle_env
- 1

使用清华源安装依赖库(如opencv-python,matplotlib,Cython等):
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -U 库名 --default-time=1000 --user
- 1

安装 paddlepaddle:
python -m pip install paddlepaddle-gpu
- 1
清华源安装也可以:
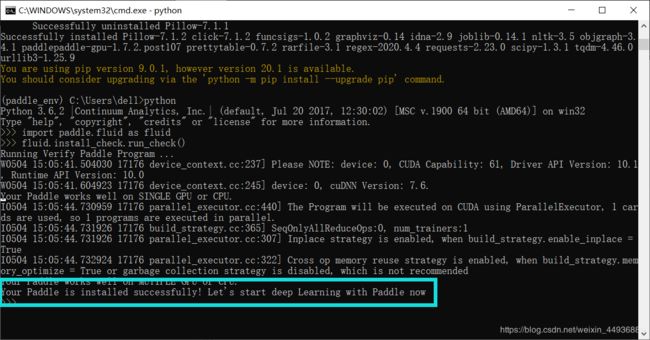
进入 python 环境并测试:
python
- 1
>>> import paddle.fluid as fluid
>>> fluid.install_check.run_check()
- 1
- 2
安装成功~
三. 安装 PaddleDetetion:
新建一个文件夹,在该目录激活环境:

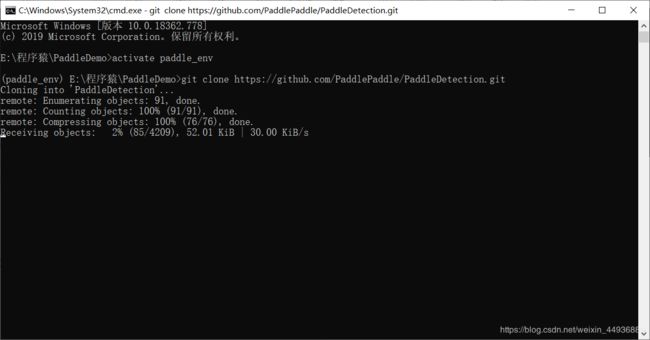
克隆 PaddleDetection 模型库:
git clone https://github.com/PaddlePaddle/PaddleDetection.git
- 1

再次安装依赖库:
pip install -r requirements.txt
- 1

指定当前 Python 路径然后测试:
set PYTHONPATH=%PYTHONPATH%;.
- 1
python ppdet/modeling/tests/test_architectures.py
- 1
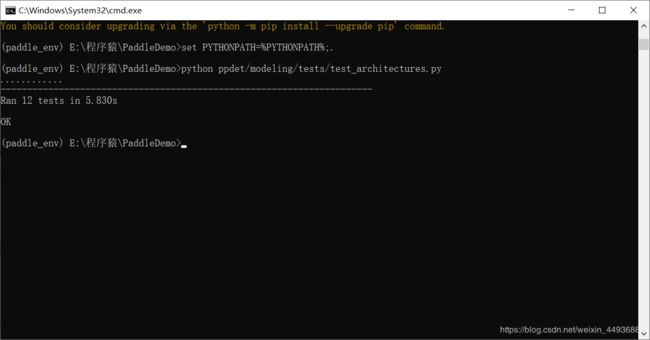
安装成功~
四. 调试 YOLOv3 代码:

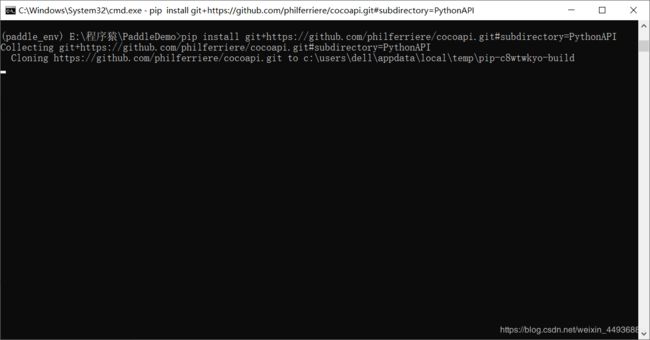
安装 cocotools:
pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
- 1
下载模型的权重文件,地址:https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.2/docs/featured_model/CONTRIB_cn.md

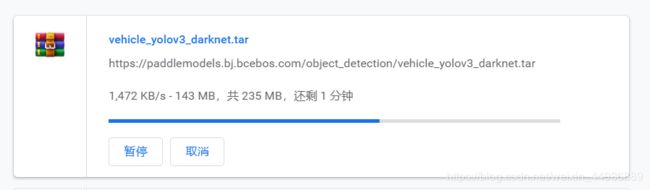
解压到文件目录:

检测这里的几张图片:

python -u tools/infer.py -c contrib/VehicleDetection/vehicle_yolov3_darknet.yml \
-o weights=vehicle_yolov3_darknet \
--infer_dir contrib/VehicleDetection/demo \
--draw_threshold 0.2 \
--output_dir contrib/VehicleDetection/demo/output
- 1
- 2
- 3
- 4
- 5
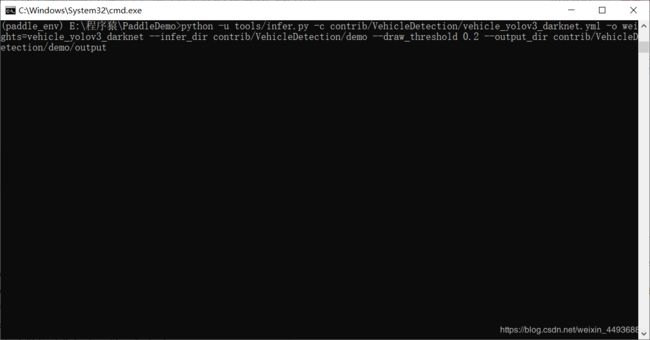

检测结果保存在 contrib\VehicleDetection\demo 目录下:
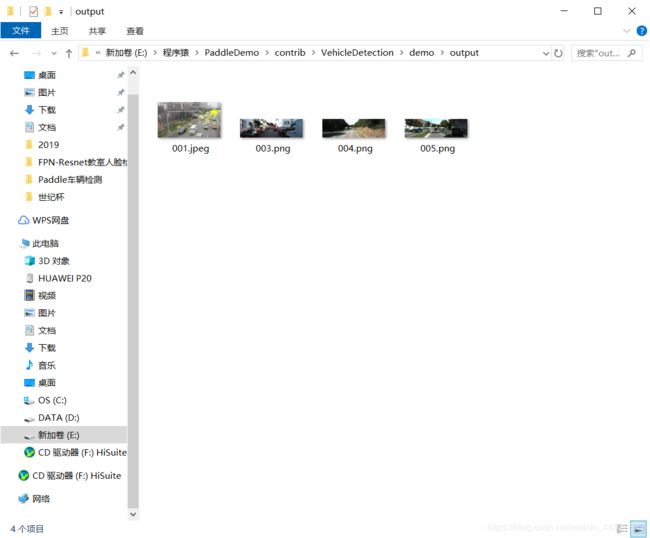
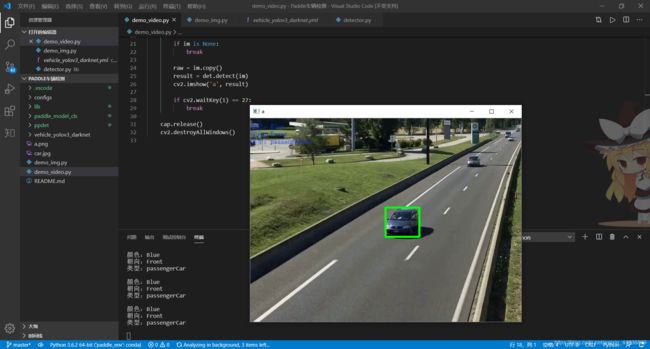
可以看到检测效果非常好~
五. YOLO 系列算法详解:
这一节我们讲一下上面车辆检测使用的算法原理。
这个我之前写过:
【论文阅读笔记】YOLO v1——You Only Look Once: Unified, Real-Time Object Detection:
https://blog.csdn.net/weixin_44936889/article/details/104384273
【论文阅读笔记】YOLO9000: Better, Faster, Stronger:
https://blog.csdn.net/weixin_44936889/article/details/104387529
【论文阅读笔记】YOLOv3: An Incremental Improvement:
https://blog.csdn.net/weixin_44936889/article/details/104390227
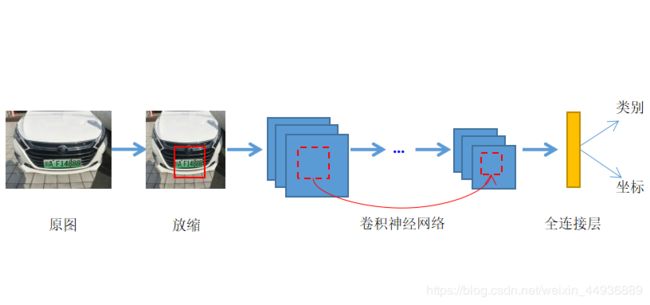
这里以车牌检测为例简单复述一下(图是自己画的hahhh,所以不是很好看的样子):
YOLOv1:
论文地址:https://arxiv.org/pdf/1506.02640.pdf
YOLO算法采用一个单独的卷积神经网络实现了端到端的的目标检测[3],其算法的基本流程为:首先将输入图片通过双线性插值的方法放缩到统一大小(文中使用448×448大小)并划分成互不重叠的网格,然后将放缩后的图像矩阵送入卷积神经网络提取高维语义特征,最后通过全连接层预测每个网格内存在目标的概率,并预测目标的坐标框位置。由于无需RPN网络提取感兴趣区域,所以YOLO的网络结构十分简洁,如图所示:
即YOLO的卷积神经网络(也称之为主干网络)将输入的图片分割成大小相同、互不重叠的单元格,然后每个单元格在卷积提取特征的过程中同时参与计算。提取特征后,每个单元格对应特整层上的特征向量通过全连接层负责去检测那些中心点落在该单元格内的目标,从而输出相应位置存在目标类别的概率和目标的预测坐标,如图所示:
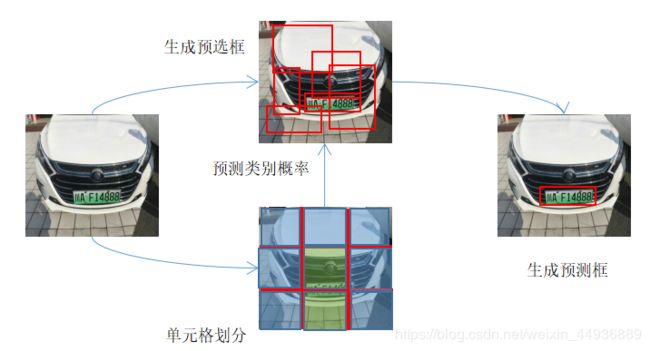
YOLO将原图化分车7×7的49个单元格,主干网络依然采用了分类网络,但最后两层使用了全卷积层,最终输出一个 7×7×30 的特征层,其中每个特征点包含的特征向量代表了每个单元格的特征。这样对于每个区域的特征向量,YOLO分别使用全连接层输出预测,相应的预测值包括:
- 该区域可能包含的相应目标的个坐标框的4个预测坐标值(文中 B=2),分别为{x,y,w,h},同时输出这B个预测框的置信度,选取置信度最高的那个预测框作为最终的结果;
- 该区域可能包含的目标的分类置信度,该置信度记为C,是一个长度为分类书的概率向量,使用softmax函数作为激活函数;
其置信度定义为:

IOU即相应物体预测框与真值框的交并比。因此每个区域生成30个预测值,最后全连接层的输出大小为S×S×30。这里使用B个预选框并生成置信度,是为了使得网络能够在同一个单元格内预测重叠目标,从而提高预测结果的容错率。增大B可以提高模型的鲁棒性,但相应的全连接层的计算复杂度也会大大提高。
此外,为了避免使用Relu函数激活而造成的特征丢失问题,作者在YOLO中将所有的Relu改为Leacky Relu激活:

最终的网络结构如图所示:

YOLOv2:
论文地址:
YOLO算法采用网格划分来检测不同区域的目标,但是由于网络结构较为简单,保证检测速度下精度还有很大的提升空间。因此作者在 YOLO 的基础上,使用了批量标准化来规范特征数据分布并加速收敛;使用高分辨率的图像作为分类器的输入,从而提高检测的精度;加入预选框的概念,提高小目标的检测精度。由此提出了一个更为高效的目标检测算法,称之为YOLO v2。并在此基础上,使用联合训练(Joint Training)算法,能够在有大量分类的图像识别数据集训练目标检测任务(只有分类的loss参与梯度下降),由此训练出的YOLO 9000能够识别和检测超过9000个物体类别。
Batch Normalization在Inception V2中提出的方法,用来替代ResNet使用的残差结构,防止梯度消失的问题。该算法将一个批次的特征值矩阵,通过简单的线性变换,转换为均值为0、方差为1的正太分布上,从而使网络中每一层的特征值大体分布一致。因此每层的梯度不会随着网络结构的加深发生太大变化,从而避免发生梯度爆炸或者梯度消失等问题。因此作者在YOLO中大量使用了Batch Normalization,使得相比原来的YOLO算法mAP上升了2%。计算过程为:
(1)计算数据的均值u;
(2)计算数据的方差σ^2;
(3)通过公式 x’=(x-u)/√(σ^2+ε)标准化数据;
(4)通过公式 y=γx’+β 进行缩放平移;

为了解决预测框对于小目标和重叠目标检测精度缺失的问题,作者不再使用YOLO采用网格分割+全连接预测坐标的方法,而是采用了跟SSD、 Faster-RCNN等相似的预选框的方法。
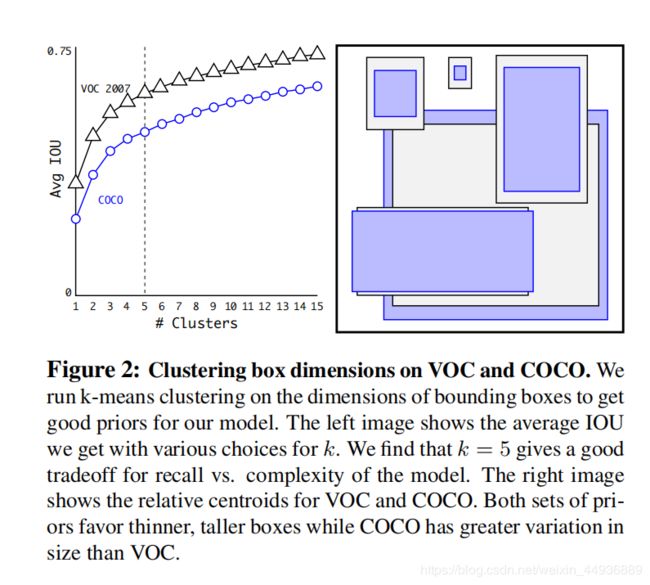
因此YOLOv2中移除了全连接层和最后一个下采样层,来最终得到一个较大的特整层。并且为了使图像最后的预测具有单中心网格,作者使用了416×416 大小作为输入,下采样参数为32,最后得到了一个 13×13大小的特征层;在使用Anchor Boxes之后,虽然mAP下降了0.3%,但是召回率从81%上升到了88%。
并且为了融合目标分类需要的高层语义特征和目标检测需要的低层轮廓特征,YOLOv2还设计了Pass Through层,即取出了最后一个池化层的特整层,(大小为 26×26×512),将每个2×2局部空间区域转换成通道特征,最后得到了一个13×13×4048的用于预测的特征层。
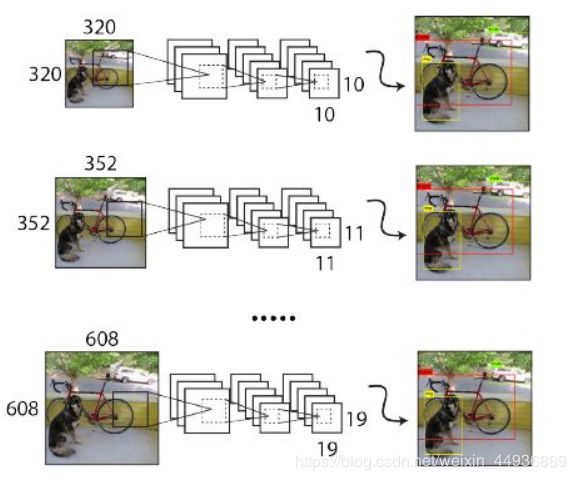
作者在训练时采用了 32 倍数的输入大小为,分别为:320,352,…,608,每 10 个 epoch 重新随机选取一个输入大小;
YOLOv3:
YOLOv3在网络结构上并没有太大改动,主要是将YOLOv2提出后目标检测领域提出的一些模型结构和训练技巧融合到了YOLO框架中。
作者首先在主干网络DarkNet-19的基础上加入了残差结构,使得它在 ImageNet上的表现跟ResNet-101相差无几,但是处理速度却快得多。
此外YOLOv3中,每个单元格对应使用了三个不同比率和大小的预选框,并且还构建了跟FPN目标检测算法相似的特征金字塔,利用不同大小、不同深度的特整层进行不同大小目标的预测。
在特征金字塔中,YOLOv3共选出了3个通过反卷积得到的特征层去检测不同大小的物体,这三个特征层大小分别为:13,26,52。特征金字塔使用卷积网络生成的金字塔型的特征层(左),生成一个融合了高度语义信息和低维特征信息的特征金字塔(右),再在这些特征金字塔的不同层上,使用不共享权重的不同卷积层预测目标的类别和检测框坐标:

六. 检测自己的数据:
这里我写了一个调用 PaddleDetection 车辆检测模型的程序,源码地址:https://github.com/Sharpiless/yolov3-vehicle-detection-paddle

点一个⭐然后下载解压:
这里我使用 VSCode,选择好配置的环境:

测试图片:
将图片路径修改为自己的路径即可:

运行 demo_img.py:

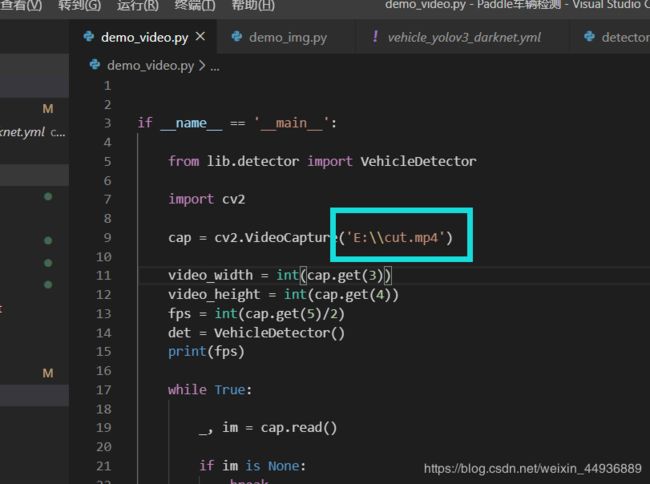
测试视频:
将图片视频修改为自己的路径即可:
七. 使用 X2Paddle 进行模型转换:
(下面只是演示一下如何使用X2Paddle进行模型转换,感兴趣的同学可以试一下)
看到这里有同学要问了,这个类型识别是如何实现的?
这里我们使用的是 torch 的开源车辆类型识别模型,并使用 X2Paddle 工具将其转换为 Paddle 模型;
X2Paddle 源码地址:https://github.com/PaddlePaddle/X2Paddle
深度学习的应用主要包括两个部分,一是通过深度学习框架训练出模型,二是利用训练出来的模型进行预测。
开发者基于不同的深度学习框架能够得到不同的训练模型,如果想要基于一种框架进行预测,就必须要解决不同框架的模型之间的匹配问题。基于这种考虑,也为了帮助用户快速从其他框架迁移,PaddlePaddle开源了模型转换工具X2Paddle。
它可以将TensorFlow、Caffe 的模型转换为PaddlePaddle的核心框架Paddle Fluid可加载的格式。同时X2Paddle还支持ONNX格式的模型转换,这样也相当于支持了众多可以转换为ONNX格式的框架,比如PyTorch、MXNet、CNTK等。
下载 torch 源码:
源码地址:https://github.com/Sharpiless/Paddle-Car-type-recognition
点⭐然后下载解压:
下载权重文件,放到 src 文件夹下面:
链接:https://pan.baidu.com/s/1fBwOr9PM9S7LmCgRddX0Gg
提取码:pv6e

首先运行 torch2onnx.py,将 pth 模型转换为 onnx 中间模型:
然后运行:
x2paddle --framework=onnx --model=classifier.onnx --save_dir=pd_model
- 1

可以看到生成了相应的 Paddle 模型;
此时将 model.py 替换为:
from paddle.fluid.initializer import Constant
from paddle.fluid.param_attr import ParamAttr
import paddle.fluid as fluid
def x2paddle_net(inputs):
x2paddle_124 = fluid.layers.fill_constant(shape=[1], dtype=‘int32’, value=0)
x2paddle_193 = fluid.layers.fill_constant(shape=[1], dtype=‘int32’, value=512)
x2paddle_194 = fluid.layers.fill_constant(shape=[1], dtype=‘int32’, value=1)
x2paddle_202 = fluid.layers.fill_constant(shape=[1], dtype=‘int32’, value=262144)
x2paddle_207 = fluid.layers.fill_constant(shape=[1], dtype=‘float32’, value=9.999999747378752e-06)
# x2paddle_input_1 = fluid.layers.data(dtype=‘float32’, shape=[1, 3, 224, 224], name=‘x2paddle_input_1’, append_batch_size=False)
x2paddle_input_1 = inputs
x2paddle_fc_bias = fluid.layers.create_parameter(dtype=‘float32’, shape=[19], name=‘x2paddle_fc_bias’, attr=‘x2paddle_fc_bias’, default_initializer=Constant(0.0))
x2paddle_fc_weight = fluid.layers.create_parameter(dtype=‘float32’, shape=[19, 262144], name=‘x2paddle_fc_weight’, attr=‘x2paddle_fc_weight’, default_initializer=Constant(0.0))
x2paddle_196 = fluid.layers.assign(x2paddle_193)
x2paddle_197 = fluid.layers.assign(x2paddle_194)
x2paddle_204 = fluid.layers.assign(x2paddle_202)
x2paddle_123 = fluid.layers.shape(x2paddle_input_1)
x2paddle_126 = fluid.layers.conv2d(x2paddle_input_1, num_filters=64, filter_size=[7, 7], stride=[2, 2], padding=[3, 3], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_0_weight’, name=‘x2paddle_126’, bias_attr=False)
x2paddle_125 = fluid.layers.gather(input=x2paddle_123, index=x2paddle_124)
x2paddle_127 = fluid.layers.batch_norm(x2paddle_126, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_1_weight’, bias_attr=‘x2paddle_features_1_bias’, moving_mean_name=‘x2paddle_features_1_running_mean’, moving_variance_name=‘x2paddle_features_1_running_var’, use_global_stats=False, name=‘x2paddle_127’)
x2paddle_195 = fluid.layers.assign(x2paddle_125)
x2paddle_203 = fluid.layers.assign(x2paddle_125)
x2paddle_128 = fluid.layers.relu(x2paddle_127, name=‘x2paddle_128’)
x2paddle_198 = fluid.layers.concat([x2paddle_195, x2paddle_196, x2paddle_197], axis=0)
x2paddle_205 = fluid.layers.concat([x2paddle_203, x2paddle_204], axis=0)
x2paddle_129 = fluid.layers.pool2d(x2paddle_128, pool_size=[3, 3], pool_type=‘max’, pool_stride=[2, 2], pool_padding=[1, 1], ceil_mode=False, name=‘x2paddle_129’, exclusive=False)
x2paddle_130 = fluid.layers.conv2d(x2paddle_129, num_filters=64, filter_size=[3, 3], stride=[1, 1], padding=[1, 1], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_4_0_conv1_weight’, name=‘x2paddle_130’, bias_attr=False)
x2paddle_131 = fluid.layers.batch_norm(x2paddle_130, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_4_0_bn1_weight’, bias_attr=‘x2paddle_features_4_0_bn1_bias’, moving_mean_name=‘x2paddle_features_4_0_bn1_running_mean’, moving_variance_name=‘x2paddle_features_4_0_bn1_running_var’, use_global_stats=False, name=‘x2paddle_131’)
x2paddle_132 = fluid.layers.relu(x2paddle_131, name=‘x2paddle_132’)
x2paddle_133 = fluid.layers.conv2d(x2paddle_132, num_filters=64, filter_size=[3, 3], stride=[1, 1], padding=[1, 1], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_4_0_conv2_weight’, name=‘x2paddle_133’, bias_attr=False)
x2paddle_134 = fluid.layers.batch_norm(x2paddle_133, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_4_0_bn2_weight’, bias_attr=‘x2paddle_features_4_0_bn2_bias’, moving_mean_name=‘x2paddle_features_4_0_bn2_running_mean’, moving_variance_name=‘x2paddle_features_4_0_bn2_running_var’, use_global_stats=False, name=‘x2paddle_134’)
x2paddle_135 = fluid.layers.elementwise_add(x=x2paddle_134, y=x2paddle_129, name=‘x2paddle_135’)
x2paddle_136 = fluid.layers.relu(x2paddle_135, name=‘x2paddle_136’)
x2paddle_137 = fluid.layers.conv2d(x2paddle_136, num_filters=64, filter_size=[3, 3], stride=[1, 1], padding=[1, 1], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_4_1_conv1_weight’, name=‘x2paddle_137’, bias_attr=False)
x2paddle_138 = fluid.layers.batch_norm(x2paddle_137, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_4_1_bn1_weight’, bias_attr=‘x2paddle_features_4_1_bn1_bias’, moving_mean_name=‘x2paddle_features_4_1_bn1_running_mean’, moving_variance_name=‘x2paddle_features_4_1_bn1_running_var’, use_global_stats=False, name=‘x2paddle_138’)
x2paddle_139 = fluid.layers.relu(x2paddle_138, name=‘x2paddle_139’)
x2paddle_140 = fluid.layers.conv2d(x2paddle_139, num_filters=64, filter_size=[3, 3], stride=[1, 1], padding=[1, 1], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_4_1_conv2_weight’, name=‘x2paddle_140’, bias_attr=False)
x2paddle_141 = fluid.layers.batch_norm(x2paddle_140, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_4_1_bn2_weight’, bias_attr=‘x2paddle_features_4_1_bn2_bias’, moving_mean_name=‘x2paddle_features_4_1_bn2_running_mean’, moving_variance_name=‘x2paddle_features_4_1_bn2_running_var’, use_global_stats=False, name=‘x2paddle_141’)
x2paddle_142 = fluid.layers.elementwise_add(x=x2paddle_141, y=x2paddle_136, name=‘x2paddle_142’)
x2paddle_143 = fluid.layers.relu(x2paddle_142, name=‘x2paddle_143’)
x2paddle_144 = fluid.layers.conv2d(x2paddle_143, num_filters=128, filter_size=[3, 3], stride=[2, 2], padding=[1, 1], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_5_0_conv1_weight’, name=‘x2paddle_144’, bias_attr=False)
x2paddle_149 = fluid.layers.conv2d(x2paddle_143, num_filters=128, filter_size=[1, 1], stride=[2, 2], padding=[0, 0], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_5_0_downsample_0_weight’, name=‘x2paddle_149’, bias_attr=False)
x2paddle_145 = fluid.layers.batch_norm(x2paddle_144, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_5_0_bn1_weight’, bias_attr=‘x2paddle_features_5_0_bn1_bias’, moving_mean_name=‘x2paddle_features_5_0_bn1_running_mean’, moving_variance_name=‘x2paddle_features_5_0_bn1_running_var’, use_global_stats=False, name=‘x2paddle_145’)
x2paddle_150 = fluid.layers.batch_norm(x2paddle_149, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_5_0_downsample_1_weight’, bias_attr=‘x2paddle_features_5_0_downsample_1_bias’, moving_mean_name=‘x2paddle_features_5_0_downsample_1_running_mean’, moving_variance_name=‘x2paddle_features_5_0_downsample_1_running_var’, use_global_stats=False, name=‘x2paddle_150’)
x2paddle_146 = fluid.layers.relu(x2paddle_145, name=‘x2paddle_146’)
x2paddle_147 = fluid.layers.conv2d(x2paddle_146, num_filters=128, filter_size=[3, 3], stride=[1, 1], padding=[1, 1], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_5_0_conv2_weight’, name=‘x2paddle_147’, bias_attr=False)
x2paddle_148 = fluid.layers.batch_norm(x2paddle_147, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_5_0_bn2_weight’, bias_attr=‘x2paddle_features_5_0_bn2_bias’, moving_mean_name=‘x2paddle_features_5_0_bn2_running_mean’, moving_variance_name=‘x2paddle_features_5_0_bn2_running_var’, use_global_stats=False, name=‘x2paddle_148’)
x2paddle_151 = fluid.layers.elementwise_add(x=x2paddle_148, y=x2paddle_150, name=‘x2paddle_151’)
x2paddle_152 = fluid.layers.relu(x2paddle_151, name=‘x2paddle_152’)
x2paddle_153 = fluid.layers.conv2d(x2paddle_152, num_filters=128, filter_size=[3, 3], stride=[1, 1], padding=[1, 1], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_5_1_conv1_weight’, name=‘x2paddle_153’, bias_attr=False)
x2paddle_154 = fluid.layers.batch_norm(x2paddle_153, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_5_1_bn1_weight’, bias_attr=‘x2paddle_features_5_1_bn1_bias’, moving_mean_name=‘x2paddle_features_5_1_bn1_running_mean’, moving_variance_name=‘x2paddle_features_5_1_bn1_running_var’, use_global_stats=False, name=‘x2paddle_154’)
x2paddle_155 = fluid.layers.relu(x2paddle_154, name=‘x2paddle_155’)
x2paddle_156 = fluid.layers.conv2d(x2paddle_155, num_filters=128, filter_size=[3, 3], stride=[1, 1], padding=[1, 1], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_5_1_conv2_weight’, name=‘x2paddle_156’, bias_attr=False)
x2paddle_157 = fluid.layers.batch_norm(x2paddle_156, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_5_1_bn2_weight’, bias_attr=‘x2paddle_features_5_1_bn2_bias’, moving_mean_name=‘x2paddle_features_5_1_bn2_running_mean’, moving_variance_name=‘x2paddle_features_5_1_bn2_running_var’, use_global_stats=False, name=‘x2paddle_157’)
x2paddle_158 = fluid.layers.elementwise_add(x=x2paddle_157, y=x2paddle_152, name=‘x2paddle_158’)
x2paddle_159 = fluid.layers.relu(x2paddle_158, name=‘x2paddle_159’)
x2paddle_160 = fluid.layers.conv2d(x2paddle_159, num_filters=256, filter_size=[3, 3], stride=[2, 2], padding=[1, 1], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_6_0_conv1_weight’, name=‘x2paddle_160’, bias_attr=False)
x2paddle_165 = fluid.layers.conv2d(x2paddle_159, num_filters=256, filter_size=[1, 1], stride=[2, 2], padding=[0, 0], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_6_0_downsample_0_weight’, name=‘x2paddle_165’, bias_attr=False)
x2paddle_161 = fluid.layers.batch_norm(x2paddle_160, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_6_0_bn1_weight’, bias_attr=‘x2paddle_features_6_0_bn1_bias’, moving_mean_name=‘x2paddle_features_6_0_bn1_running_mean’, moving_variance_name=‘x2paddle_features_6_0_bn1_running_var’, use_global_stats=False, name=‘x2paddle_161’)
x2paddle_166 = fluid.layers.batch_norm(x2paddle_165, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_6_0_downsample_1_weight’, bias_attr=‘x2paddle_features_6_0_downsample_1_bias’, moving_mean_name=‘x2paddle_features_6_0_downsample_1_running_mean’, moving_variance_name=‘x2paddle_features_6_0_downsample_1_running_var’, use_global_stats=False, name=‘x2paddle_166’)
x2paddle_162 = fluid.layers.relu(x2paddle_161, name=‘x2paddle_162’)
x2paddle_163 = fluid.layers.conv2d(x2paddle_162, num_filters=256, filter_size=[3, 3], stride=[1, 1], padding=[1, 1], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_6_0_conv2_weight’, name=‘x2paddle_163’, bias_attr=False)
x2paddle_164 = fluid.layers.batch_norm(x2paddle_163, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_6_0_bn2_weight’, bias_attr=‘x2paddle_features_6_0_bn2_bias’, moving_mean_name=‘x2paddle_features_6_0_bn2_running_mean’, moving_variance_name=‘x2paddle_features_6_0_bn2_running_var’, use_global_stats=False, name=‘x2paddle_164’)
x2paddle_167 = fluid.layers.elementwise_add(x=x2paddle_164, y=x2paddle_166, name=‘x2paddle_167’)
x2paddle_168 = fluid.layers.relu(x2paddle_167, name=‘x2paddle_168’)
x2paddle_169 = fluid.layers.conv2d(x2paddle_168, num_filters=256, filter_size=[3, 3], stride=[1, 1], padding=[1, 1], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_6_1_conv1_weight’, name=‘x2paddle_169’, bias_attr=False)
x2paddle_170 = fluid.layers.batch_norm(x2paddle_169, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_6_1_bn1_weight’, bias_attr=‘x2paddle_features_6_1_bn1_bias’, moving_mean_name=‘x2paddle_features_6_1_bn1_running_mean’, moving_variance_name=‘x2paddle_features_6_1_bn1_running_var’, use_global_stats=False, name=‘x2paddle_170’)
x2paddle_171 = fluid.layers.relu(x2paddle_170, name=‘x2paddle_171’)
x2paddle_172 = fluid.layers.conv2d(x2paddle_171, num_filters=256, filter_size=[3, 3], stride=[1, 1], padding=[1, 1], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_6_1_conv2_weight’, name=‘x2paddle_172’, bias_attr=False)
x2paddle_173 = fluid.layers.batch_norm(x2paddle_172, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_6_1_bn2_weight’, bias_attr=‘x2paddle_features_6_1_bn2_bias’, moving_mean_name=‘x2paddle_features_6_1_bn2_running_mean’, moving_variance_name=‘x2paddle_features_6_1_bn2_running_var’, use_global_stats=False, name=‘x2paddle_173’)
x2paddle_174 = fluid.layers.elementwise_add(x=x2paddle_173, y=x2paddle_168, name=‘x2paddle_174’)
x2paddle_175 = fluid.layers.relu(x2paddle_174, name=‘x2paddle_175’)
x2paddle_176 = fluid.layers.conv2d(x2paddle_175, num_filters=512, filter_size=[3, 3], stride=[2, 2], padding=[1, 1], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_7_0_conv1_weight’, name=‘x2paddle_176’, bias_attr=False)
x2paddle_181 = fluid.layers.conv2d(x2paddle_175, num_filters=512, filter_size=[1, 1], stride=[2, 2], padding=[0, 0], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_7_0_downsample_0_weight’, name=‘x2paddle_181’, bias_attr=False)
x2paddle_177 = fluid.layers.batch_norm(x2paddle_176, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_7_0_bn1_weight’, bias_attr=‘x2paddle_features_7_0_bn1_bias’, moving_mean_name=‘x2paddle_features_7_0_bn1_running_mean’, moving_variance_name=‘x2paddle_features_7_0_bn1_running_var’, use_global_stats=False, name=‘x2paddle_177’)
x2paddle_182 = fluid.layers.batch_norm(x2paddle_181, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_7_0_downsample_1_weight’, bias_attr=‘x2paddle_features_7_0_downsample_1_bias’, moving_mean_name=‘x2paddle_features_7_0_downsample_1_running_mean’, moving_variance_name=‘x2paddle_features_7_0_downsample_1_running_var’, use_global_stats=False, name=‘x2paddle_182’)
x2paddle_178 = fluid.layers.relu(x2paddle_177, name=‘x2paddle_178’)
x2paddle_179 = fluid.layers.conv2d(x2paddle_178, num_filters=512, filter_size=[3, 3], stride=[1, 1], padding=[1, 1], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_7_0_conv2_weight’, name=‘x2paddle_179’, bias_attr=False)
x2paddle_180 = fluid.layers.batch_norm(x2paddle_179, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_7_0_bn2_weight’, bias_attr=‘x2paddle_features_7_0_bn2_bias’, moving_mean_name=‘x2paddle_features_7_0_bn2_running_mean’, moving_variance_name=‘x2paddle_features_7_0_bn2_running_var’, use_global_stats=False, name=‘x2paddle_180’)
x2paddle_183 = fluid.layers.elementwise_add(x=x2paddle_180, y=x2paddle_182, name=‘x2paddle_183’)
x2paddle_184 = fluid.layers.relu(x2paddle_183, name=‘x2paddle_184’)
x2paddle_185 = fluid.layers.conv2d(x2paddle_184, num_filters=512, filter_size=[3, 3], stride=[1, 1], padding=[1, 1], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_7_1_conv1_weight’, name=‘x2paddle_185’, bias_attr=False)
x2paddle_186 = fluid.layers.batch_norm(x2paddle_185, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_7_1_bn1_weight’, bias_attr=‘x2paddle_features_7_1_bn1_bias’, moving_mean_name=‘x2paddle_features_7_1_bn1_running_mean’, moving_variance_name=‘x2paddle_features_7_1_bn1_running_var’, use_global_stats=False, name=‘x2paddle_186’)
x2paddle_187 = fluid.layers.relu(x2paddle_186, name=‘x2paddle_187’)
x2paddle_188 = fluid.layers.conv2d(x2paddle_187, num_filters=512, filter_size=[3, 3], stride=[1, 1], padding=[1, 1], dilation=[1, 1], groups=1, param_attr=‘x2paddle_features_7_1_conv2_weight’, name=‘x2paddle_188’, bias_attr=False)
x2paddle_189 = fluid.layers.batch_norm(x2paddle_188, momentum=0.8999999761581421, epsilon=9.999999747378752e-06, data_layout=‘NCHW’, is_test=True, param_attr=‘x2paddle_features_7_1_bn2_weight’, bias_attr=‘x2paddle_features_7_1_bn2_bias’, moving_mean_name=‘x2paddle_features_7_1_bn2_running_mean’, moving_variance_name=‘x2paddle_features_7_1_bn2_running_var’, use_global_stats=False, name=‘x2paddle_189’)
x2paddle_190 = fluid.layers.elementwise_add(x=x2paddle_189, y=x2paddle_184, name=‘x2paddle_190’)
x2paddle_191 = fluid.layers.relu(x2paddle_190, name=‘x2paddle_191’)
x2paddle_192 = fluid.layers.pool2d(x2paddle_191, pool_type=‘avg’, global_pooling=True, name=‘x2paddle_192’)
x2paddle_198_cast = fluid.layers.cast(x2paddle_198, dtype=‘int32’)
x2paddle_199 = fluid.layers.reshape(x2paddle_192, name=‘x2paddle_199’, actual_shape=x2paddle_198_cast, shape=[1, 512, 1])
x2paddle_200 = fluid.layers.transpose(x2paddle_199, perm=[0, 2, 1], name=‘x2paddle_200’)
x2paddle_201 = fluid.layers.matmul(x=x2paddle_199, y=x2paddle_200, name=‘x2paddle_201’)
x2paddle_205_cast = fluid.layers.cast(x2paddle_205, dtype=‘int32’)
x2paddle_206 = fluid.layers.reshape(x2paddle_201, name=‘x2paddle_206’, actual_shape=x2paddle_205_cast, shape=[1, 262144])
x2paddle_208 = fluid.layers.elementwise_add(x=x2paddle_206, y=x2paddle_207, name=‘x2paddle_208’)
x2paddle_209 = fluid.layers.sqrt(x2paddle_208, name=‘x2paddle_209’)
x2paddle_210_mm = fluid.layers.matmul(x=x2paddle_209, y=x2paddle_fc_weight, transpose_x=False, transpose_y=True, alpha=1.0, name=‘x2paddle_210_mm’)
x2paddle_210 = fluid.layers.elementwise_add(x=x2paddle_210_mm, y=x2paddle_fc_bias, name=‘x2paddle_210’)
return [x2paddle_input_1], [x2paddle_210]
def run_net(param_dir="./"):
import os
inputs, outputs = x2paddle_net()
for i, out in enumerate(outputs):
if isinstance(out, list):
for out_part in out:
outputs.append(out_part)
del outputs[i]
exe = fluid.Executor(fluid.CPUPlace())
exe.run(fluid.default_startup_program())
def if_exist(var):
b = os.path.exists(os.path.join(param_dir, var.name))
return b
fluid.io.load_vars(exe,
param_dir,
fluid.default_main_program(),
predicate=if_exist)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
然后创建调用 Paddle 模型的 test_img.py:
import cv2
from pd_model.model_with_code.model import x2paddle_net
import argparse
import functools
import numpy as np
import paddle.fluid as fluid
from PIL import ImageFont, ImageDraw, Image
font_path = r’./simsun.ttc’
font = ImageFont.truetype(font_path, 32)
def putText(img, text, x, y, color=(0, 0, 255)):
img_pil = Image.fromarray(img)
draw = ImageDraw.Draw(img_pil)
b, g, r = color
a = 0
draw.text((x, y), text, font=font, fill=(b, g, r, a))
img = np.array(img_pil)
return img
# 定义一个预处理图像的函数
def process_img(img_path=’’, image_shape=[3, 224, 224]):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
img = cv2.imread(img_path)
img = cv2.resize(img, (image_shape[1], image_shape[2]))
#img = cv2.resize(img,(256,256))
#img = crop_image(img, image_shape[1], True)
# RBG img [224,224,3]->[3,224,224]
img = img[:, :, ::-1].astype('float32').transpose((2, 0, 1)) / 255
#img = img.astype('float32').transpose((2, 0, 1)) / 255
img_mean = np.array(mean).reshape((3, 1, 1))
img_std = np.array(std).reshape((3, 1, 1))
img -= img_mean
img /= img_std
img = img.astype('float32')
img = np.expand_dims(img, axis=0)
return img
# 模型推理函数
color_attrs = [‘Black’, ‘Blue’, ‘Brown’,
‘Gray’, ‘Green’, ‘Pink’,
‘Red’, ‘White’, ‘Yellow’] # 车体颜色
direction_attrs = [‘Front’, ‘Rear’] # 拍摄位置
type_attrs = [‘passengerCar’, ‘saloonCar’,
‘shopTruck’, ‘suv’, ‘trailer’, ‘truck’, ‘van’, ‘waggon’] # 车辆类型
def inference(img):
fetch_list = [out.name]
output = exe.run(eval_program,
fetch_list=fetch_list,
feed={'image': img})
color_idx, direction_idx, type_idx = get_predict(np.array(output))
color_name = color_attrs[color_idx]
direction_name = direction_attrs[direction_idx]
type_name = type_attrs[type_idx]
return color_name, direction_name, type_name
def get_predict(output):
output = np.squeeze(output)
pred_color = output[:9]
pred_direction = output[9:11]
pred_type = output[11:]
color_idx = np.argmax(pred_color)
direction_idx = np.argmax(pred_direction)
type_idx = np.argmax(pred_type)
return color_idx, direction_idx, type_idx
use_gpu = True
# Attack graph
adv_program = fluid.Program()
# 完成初始化
with fluid.program_guard(adv_program):
input_layer = fluid.layers.data(
name=‘image’, shape=[3, 224, 224], dtype=‘float32’)
# 设置为可以计算梯度
input_layer.stop_gradient = False
# model definition
_, out_logits = x2paddle_net(inputs=input_layer)
out = fluid.layers.softmax(out_logits[0])
place = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
# 记载模型参数
fluid.io.load_persistables(exe, './pd_model/model_with_code/')
# 创建测试用评估模式
eval_program = adv_program.clone(for_test=True)
# im_pt = ‘./a.jpg’
im_pt = ‘./a.png’
img = process_img(im_pt)
color_name, direction_name, type_name = inference(img)
label = ‘颜色:{}\n朝向:{}\n类型:{}’.format(color_name, direction_name, type_name)
img = cv2.imread(im_pt)
img = putText(img, label, x=1, y=10, color=(0, 215, 255))
cv2.imshow(‘a’, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
运行测试:

成功~
八. 总结:
在本篇文章中,我们使用了 PaddleDetection 和 X2Paddle 两个工具,实现了一个图片、视频中车帘检测和类型识别的小项目。
其中:
- PaddleDetection 提供了很好的应用接口和预训练模型,实现了快速的车辆检测;
- X2Paddle 则解决了不同深度学习框架的模型权重文件转换的问题;
更多其他项目和信息请关注我的博客:https://blog.csdn.net/weixin_44936889

