哈希表基本操作及其扩展
哈希表
- 哈希表的概念:
- 哈希表本身是一个数组,其元素在数组中存放位置为:通过哈希函数使元素关键码和元素存储位置有一定的映射关系
- 哈希表的特点:
- 搜索数组中某一元素时,可以通过该元素的关键码和存储位置的映射关系直接找到对应位置查看是否存在
- 在数组中插入元素时,根据哈希函数计算出插入元素的位置并且在此位置存放
- 存在哈希冲突:两个不同的元素通过哈希函数所映射的存储位置相同即为哈希冲突。例如:两个元素的关键字X != y,但有HashFunc(x) == HashFunc(y)
哈希冲突的解决方法
根据哈希表的特点可知,哈希冲突在所难免,虽然可以通过调整哈希函数来降低哈希函数的可能性,但还是不能完全避免哈希冲突,因此提出两种解决方案:
闭散列:开放地址法,即当哈希表未装满时,将待插入元素Key放在下一“空位”处,
- “空位寻找”:线性探测和二次探测
线性探测:从发生哈希冲突的位置挨着挨着向后找空位置,直到找到空位置,例如:
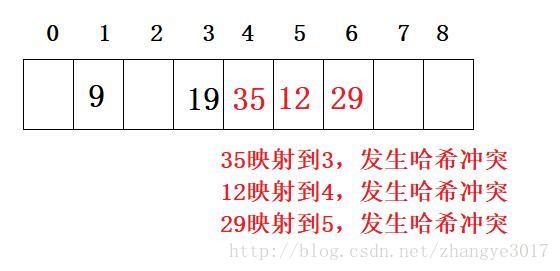
二次探测:从哈希冲突的位置加上 i2 i 2 ,i=1,2,3,….例如:

开散列:拉链法,首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中(如图)
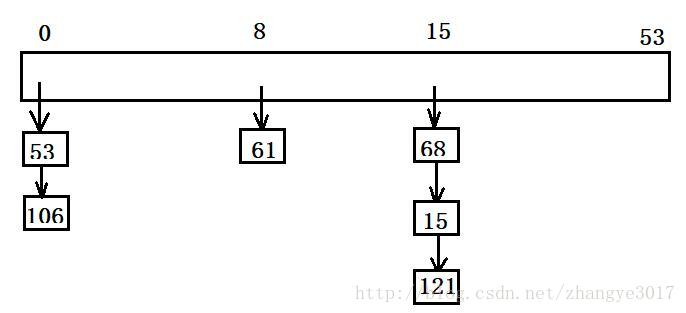
基本操作
插入
- 注意问题:
(1)使用闭散列方法时扩容须满足的负载因子 (大于0.7)
(2)使用开散列方法时扩容须满足的负载因子 (等于1)
(3)扩容时将原哈希表中的内容存放至新表时,映射到新表的位置须重新计算
(4)为了尽可能的避免哈希冲突,使用素数表对齐做哈希表的容量
- 注意问题:
删除
- 注意问题:
(1) 闭散列删除时只需要将其元素的状态改为删除即可
(2)开散列在删除时需要将其所在节点进行删除,删除节点须注意是否为头节点
- 注意问题:
查找
- 注意问题:
(1)闭散列查找某一元素时,只须在存在状态的元素中寻找,如果状态该元素的关键码所映射的位置为空(EMPTY)或者删除(DELET),表示该元素不存在
(2)闭散列查找某一元素时,不仅需要在所映射的当前位置去找,还须在其所挂链表中寻找
- 注意问题:
代码实现
- 闭散列(开放地址)
#include- 开散列(拉链法)
#include哈希扩展
扩展一(位图)
- 位图理解:,位图是利用每一位来表示一个整数是否存在来节省空间,1表示存在,0表示不存在。
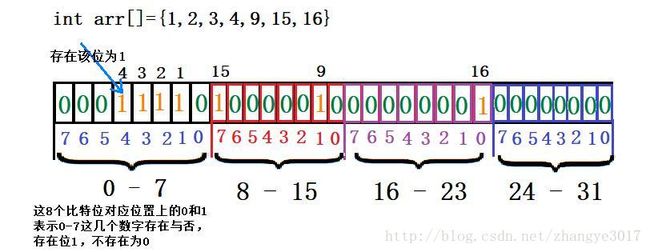
位图优缺点
(1)优点:位图所开空间只与范围有关,节省空间,在处理海量数据问题时,可使用位图;例如:在40亿个数中判断一个数是否存在
(2)缺点:通过位图所得到的结果不精确位图操作
(1)插入:注意位置的计算,先计算待插入元素在数组当中的位置,在计算在哪一个比特位
(2)重置:和插入一样,找到位置,进行去反即可
(3)查找:因为是1代表存在,故利用按位与(&)操作符查看是否为1
扩展二(布隆过滤器)
概念
Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。特点
(1)它适用于判断元素是否存在集合当中,速率非常高。Bloom Filter有可能会出现错误判断,但不会漏掉判断。
(2)Bloom Filter可以准确的判断出某个元素不在集合之中。但如果判断某个元素存在集合中,有一定的概率判断错误。因此,Bloom Filter不适合那些“零错误”的应用场合。
(3)在能容忍低错误率的应用场合下,Bloom Filter比其他查找算法(如hash,折半查找)极大节省了空间。- 结构
(1)数组:既然是哈希的扩展,结构中必然包含数组,但此数组是有比特位(bite)组成的数组
(2)含有多个哈希函数,为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,n}的范围中。 操作
(1)插入:布隆的结构里有多个哈希函数,必然某一数据的关键码映射到数组的位置不止一个
(2)删除:一个数据对应多个位置,故删除一个必然会影响其他数据,布隆过滤器的操作里不支持删除
(3)查找:前面布隆的特点已经说过查找会出现误差,故布隆不适合出现在“零错误”的场合应用
(1)对y使用k个哈希函数得到k个哈希值
(2)判断是否所有hash(y)的位置都是1(1≤i≤k),即k个位置都被设置为1了,
(3)如果所有位置都已置成了‘1’,y就可能集合中的元素;只有一个位置上是‘0’,那y一定不是集合中的元素。
注意1:布隆过滤器无法准确判断某个元素存在于集合中,因为一个不存在元素通过k个哈希函数映射出来的位置上的值可能都是‘1’。
注意2:布隆过滤器不能删除元素。删除一个元素就要把k个位置置为‘0’,这样就会影响其他元素。(可以改进)改进
前面我们提到布隆过滤器不能删除元素这一缺点是可以改进的,解决方案是用多个bit来存储一个元素。这里为了计算方便,采用32bit来存储。全‘0’代表不存在,出现一个便加一,删除元素时把对应位置减一就可以了。
位图和布隆具体操作源码可点下面链接:
http://blog.csdn.net/zhangye3017/article/details/79477293
位图和布隆经典例题,可以点下面链接
http://blog.csdn.net/zhangye3017/article/details/79431449