线上问题排查手册
一 线上常见问题定位
常见问题 1:CPU 利用率高
CPU 使用率是衡量系统繁忙程度的重要指标,一般情况下单纯的 CPU 高并没有问题,它代表系统正在不断的处理我们的任务,但是如果 CPU 过高,导致任务处理不过来,从而引起 load 高,这个是非常危险需要关注的。 CPU 使用率的安全值没有一个标准值,取决于你的系统是计算密集型还是 IO 密集型,一般计算密集型应用 CPU 使用率偏高 load 偏低,IO 密集型相反。
问题原因及定位:
1 频繁 FullGC/YongGC
-
查看 gc 日志
-
jstat -gcutil pid 查看内存使用和 gc 情况
2 代码消耗,如死循环,md5 等内存态操作
1)arthas (已开源:https://github.com/alibaba/arthas)
-
thread -n 5 查看 CPU 使用率最高的前 5 个线程(包含堆栈,第二部分有详解)
2)jstack 查找
-
ps -ef | grep java 找到 Java 进程 id
-
top -Hp pid 找到使用 CPU 最高的线程
-
printf ‘0x%x’ tid 线程 id 转化 16 进制
-
jstack pid | grep tid 找到线程堆栈
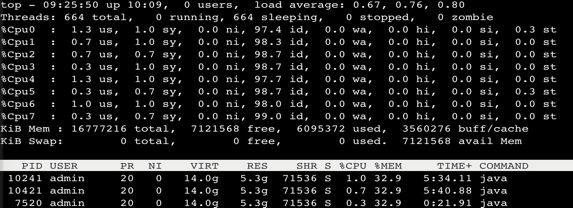
ps:输入“1”可查看每个 CPU 的情况,之前有团队遇到单个 CPU 被中间件绑定导致 CPU 飚高的 case。
常见问题 2:load 高
load 指单位时间内活跃进程数,包含运行态(runnable 和 running)和不可中断态( IO、内核态锁)。关键字是运行态和不可中断态,运行态可以联想到 Java 线程的 6 种状态,如下,线程 new 之后处于 NEW 状态,执行 start 进入 runnable 等待 CPU 调度,因此如果 CPU 很忙会导致 runnable 进程数增加;不可中断态主要包含网络 IO、磁盘 IO 以及内核态的锁,如 synchronized 等。
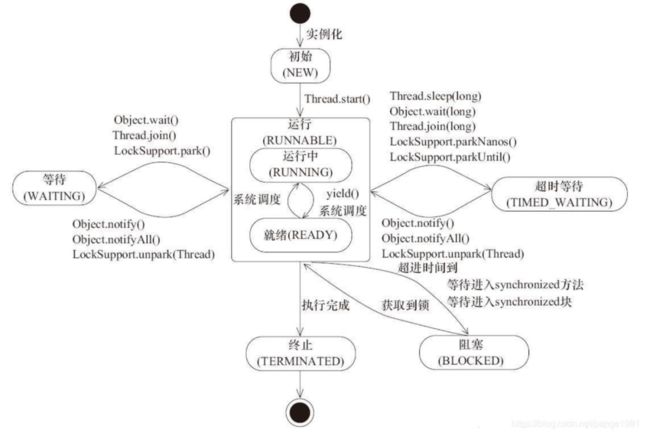
问题原因及定位:
1 CPU 利用率高,可运行态进程数多
-
排查方法见常见问题一
2 iowait,等待 IO
-
vmstat 查看 blocked 进程状况
-
jstack -l pid | grep BLOCKED 查看阻塞态线程堆栈
3 等待内核态锁,如 synchronized
-
jstack -l pid | grep BLOCKED 查看阻塞态线程堆栈
-
profiler dump 线程栈,分析线程持锁情况
常见问题 3:持续 FullGC
在了解 FullGC 原因之前,先花一点时间回顾下 jvm 的内存相关知识:
内存模型
新 new 的对象放在 Eden 区,当 Eden 区满之后进行一次 MinorGC,并将存活的对象放入 S0;
当下一次 Eden 区满的时候,再次进行 MinorGC,并将存活的对象和 S0 的对象放入S1(S0 和 S1 始终有一个是空的);
依次循环直到 S0 或者 S1 快满的时候将对象放入 old 区,依次,直到 old 区满进行 FullGC。
jdk1.7 之前 Java 类信息、常量池、静态变量存储在 Perm 永久代,类的原数据和静态变量在类加载的时候放入 Perm 区,类卸载的时候清理;在 1.8 中,MetaSpace 代替 Perm 区,使用本地内存,常量池和静态变量放入堆区,一定程度上解决了在运行时生成或加载大量类造成的 FullGC,如反射、代理、groovy 等。
回收器
年轻代常用 ParNew,复制算法,多线程并行;
老年代常用 CMS,标记清除算法(会产生内存碎片),并发收集(收集过程中有用户线程产生对象)。
关键常用参数
-
CMSInitiatingOccupancyFraction 表示老年代使用率达到多少时进行 FullGC;
-
UseCMSCompactAtFullCollection 表示在进行 FullGC 之后进行老年代内存整理,避免产生内存碎片。
问题原因及定位:
1 prommotion failed
从S区晋升的对象在老年代也放不下导致 FullGC(fgc 回收无效则抛 OOM)。
1)survivor 区太小,对象过早进入老年代。
-
jstat -gcutil pid 1000 观察内存运行情况;
-
jinfo pid 查看 SurvivorRatio 参数;
2)大对象分配,没有足够的内存。
-
日志查找关键字 “allocating large”;
-
profiler 查看内存概况大对象分布;
3)old 区存在大量对象。
-
实例数量前十的类:jmap -histo pid | sort -n -r -k 2 | head -10
-
实例容量前十的类:jmap -histo pid | sort -n -r -k 3 | head -10
-
dump 堆,profiler 分析对象占用情况
2 concurrent mode failed
在 CMS GC 过程中业务线程将对象放入老年代(并发收集的特点)内存不足。详细原因:
1)fgc 触发比例过大,导致老年代占用过多,并发收集时用户线程持续产生对象导致达到触发 FGC 比例。
-
jinfo 查看 CMSInitiatingOccupancyFraction 参数,一般 70~80 即可
2)老年代存在内存碎片。
-
jinfo 查看 UseCMSCompactAtFullCollection 参数,在 FullGC 后整理内存
常见问题 4:线程池满
Java 线程池以有界队列的线程池为例,当新任务提交时,如果运行的线程少于 corePoolSize,则创建新线程来处理请求。如果正在运行的线程数等于 corePoolSize 时,则新任务被添加到队列中,直到队列满。当队列满了后,会继续开辟新线程来处理任务,但不超过 maximumPoolSize。当任务队列满了并且已开辟了最大线程数,此时又来了新任务,ThreadPoolExecutor 会拒绝服务。
问题原因及定位:
1 下游 RT 高,超时时间不合理
-
业务监控
-
sunfire
-
eagleeye
2 数据库慢 sql 或者数据库死锁
-
日志关键字 “Deadlock found when trying to get lock”
-
Jstack 或 zprofiler 查看阻塞态线程
3 Java 代码死锁
-
jstack –l pid | grep -i –E 'BLOCKED | deadlock'
-
dump thread 通过 zprofiler 分析阻塞线程和持锁情况
常见问题 5:NoSuchMethodException
问题原因及定位:
1 jar 包冲突
java 在装载一个目录下所有 jar 包时,它加载的顺序完全取决于操作系统。
-
mvn dependency:tree 分析报错方法所在的 jar 包版本,留下新的
-
arthas:sc -d ClassName
-
XX:+TraceClassLoading
2 同类问题
-
ClassNotFoundException
-
NoClassDefFoundError
-
ClassCastException
二 常用工具介绍
常用命令
1 tail
-
-f 跟踪文件
2 grep
-
-i 忽略大小写
-
-v 反转查找
-
-E 扩展正则表达式 :grep -E 'pattern1|pattern2' filename
3 pgm
-
-b 开启并发
-
-p 指定并发数
-
-A 开启 askpass
4 awk
-
-F 指定分隔符:awk -F “|” '{print $1}‘ | sort -r | uniq -c
5 sed
-
时间段匹配:sed '/2020-03-02 10:00:00/,/2020-03-02 11:00:00/p' filename
arthas
阿里巴巴开源 Java 诊断工具(开源地址:https://github.com/alibaba/arthas),基于 javaAgent 方式,使用 Instrumentation 方式修改字节码方式进行 Java 应用诊断。
基础功能介绍
-
dashboard:系统实时数据面板, 可查看线程,内存,gc 等信息
-
thread:jvm 线程堆栈信息,如查看最繁忙的前 n 线程
-
getstatic:获取静态属性值,如 getstatic className attrName 可用于查看线上开关真实值
-
sc:查看 jvm 已加载类信息,可用于排查 jar 包冲突
-
sm:查看 jvm 已加载类的方法信息
-
jad:反编译 jvm 加载类信息,排查代码逻辑没执行原因
-
watch:观测方法执行数据,包含出入参,异常等;
watch xxxClass xxxMethod " {params, throwExp} " -e -x 2
watch xxxClass xxxMethod "{params,returnObj}" "params[0].sellerId.equals('189')" -x 2
watch xxxClass xxxMethod sendMsg '@com.taobao.eagleeye.EagleEye@getTraceId()'
-
trace:方法内部调用时长,并输出每个节点的耗时,用于性能分析
-
tt:用于记录方法,并做回放
三 常见问题恢复
1 线程池满
-
rpc 框架线程池满
高 RT 接口进行线程数限流
-
应用内线程池满
重启可短暂缓解,具体还得看问题原因
2 CPU 高,load 高
-
单机置换或重启,可短暂缓解,恢复看具体原因
-
集群高且流量大幅增加,扩容,恢复看具体原因
3 下游 RT 高
-
限流
-
降级
4 数据库
-
死锁
kill 进程
-
慢 sql
sql 限流
线上问题的排查是一个积累的过程,只有了解问题背后的原理才能更快速的定位和恢复,除此之外更需要有一些趁手的工具来辅助排查,从而降低整个团队问题定位和快恢的门槛。
来自:阿里技术