数学分析模型(一):数据的无量纲处理方法及示例(附完整代码)
数据的无量纲处理方法及示例(附完整代码)
- (1)极值化方法
- (2)标准化方法
- (3)均值化方法
- 示例
- 要求
- 建模步骤
- 程序
- 结果
- 备注
在对实际问题建模过程中,特别是在建立指标评价体系时,常常会面临不同类型的数据处理及融合。而各个指标之间由于计量单位和数量级的不尽相同,从而使得各指标间不具有可比性。在数据分析之前,通常需要先将数据标准化,利用标准化后的数据进行分析。数据标准化处理主要包括同趋化处理和无量纲化处理两个方面。数据的同趋化处理主要解决不同性质的数据问题,对不同性质指标直接累加不能正确反应不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对评价体系的作用力同趋化。数据无量纲化主要解决数据的不可比性,在此处主要介绍几种数据的无量纲化的处理方式。
(1)极值化方法
可以选择如下的三种方式:
(A)![]() 即每一个变量除以该变量取值的全距,标准化后的每个变量的取值范围限于[-1,1]。
即每一个变量除以该变量取值的全距,标准化后的每个变量的取值范围限于[-1,1]。
(B) ![]() 即每一个变量与变量最小值之差除以该变量取值的全距,标准化后各变量的取值范围限于[0,1]。
即每一个变量与变量最小值之差除以该变量取值的全距,标准化后各变量的取值范围限于[0,1]。
(C)![]() ,即每一个变量值除以该变量取值的最大值,标准化后使变量的最大取值为1。
,即每一个变量值除以该变量取值的最大值,标准化后使变量的最大取值为1。
采用极值化方法对变量数据无量纲化是通过变量取值的最大值和最小值将原始数据转换为界于某一特定范围的数据,从而消除量纲和数量级的影响。由于极值化方法对变量无量纲化过程中仅仅对该变量的最大值和最小值这两个极端值有关,而与其他取值无关,这使得该方法在改变各变量权重时过分依赖两个极端取值。
(2)标准化方法
利用![]() 来计算,即每一个变量值与其平均值之差除以该变量的标准差,无量纲化后各变量的平均值为0,标准差为1,从而消除量纲和数量级的影响。虽然该方法在无量纲化过程中利用了所有的数据信息,但是该方法在无量纲化后不仅使得转换后的各变量均值相同,且标准差也相同,即无量纲化的同时还消除了各变量在变异程度上的差异。
来计算,即每一个变量值与其平均值之差除以该变量的标准差,无量纲化后各变量的平均值为0,标准差为1,从而消除量纲和数量级的影响。虽然该方法在无量纲化过程中利用了所有的数据信息,但是该方法在无量纲化后不仅使得转换后的各变量均值相同,且标准差也相同,即无量纲化的同时还消除了各变量在变异程度上的差异。
(3)均值化方法
计算公式为:![]() ,该方法在消除量纲和数量级影响的同时,保留了各变量取值差异程度上的信息。
,该方法在消除量纲和数量级影响的同时,保留了各变量取值差异程度上的信息。
(4)标准差化方法
计算公式为:![]() 。该方法是标准化方法的基础上的一种变形,两者的差别仅在无量纲化后各变量的均值上,标准化方法处理后各变量的均值为0,而标准差化方法处理后各变量均值为原始变量均值与标准差的比值。
。该方法是标准化方法的基础上的一种变形,两者的差别仅在无量纲化后各变量的均值上,标准化方法处理后各变量的均值为0,而标准差化方法处理后各变量均值为原始变量均值与标准差的比值。
综上所述,针对不同类型的数据,可以选择相应的无量纲化方法。如下的示例就是一个典型的评价体系中无量纲化的范例。
示例
近年来我国淡水湖水质富营养化的污染日益严重,如何对湖泊水质的富营养化进行综合评价与治理是摆在我们面前的任务,下面两个表格分别为我国5个湖泊的实测数据和湖泊水质评价标准。
表1 全国五个主要湖泊评价参数的实测数据
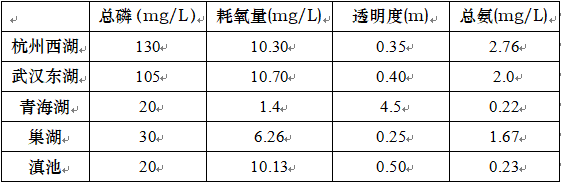
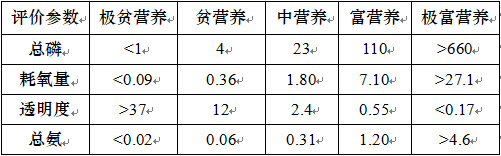
表2 湖泊水质评价标准
要求
(1)试用以上数据,分析总磷,耗氧量,透明度,总氨这4个指标对湖泊水质评价富营养化的作用。
(2)对这5个湖泊的水质综合评价,确定水质等级。
在进行综合评价之前,首先要对评价的指标进行分析。通常评价指标分成效益型,成本型和固定型指标。效益型指标是指那些数值越大影响力越大的统计指标(也称正向型指标);成本型指标是指数值越小越好的指标(也称逆向型指标);而固定型指标是指数值越接近于某个常数越好的指标(也称适度型指标)。如果每个评价指标的属性不一样,则在综合评价时就容易发生偏差,必须先对各评价指标统一属性。
建模步骤
(ⅰ)建立无量纲化实测数据矩阵和评价标准矩阵,其中实测数据矩阵和等级标准矩阵如下,
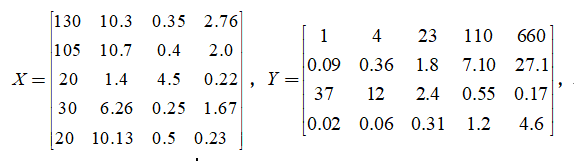
然后建立无量纲化实测数据矩阵和无量纲化等级标准矩阵,其中
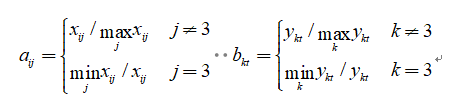
得到
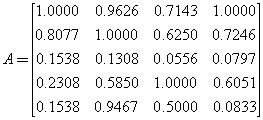

(ⅱ)计算各评价指标的权重
计算矩阵B的各行向量的均值和标准差,
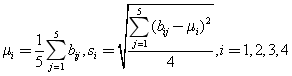
然后计算变异系数![]()
最后对变异系数归一化得到各指标的权重为
![]()
(ⅲ)建立各湖泊水质的综合评价模型
通常可以利用向量之间的距离来衡量两个向量之间的接近程度,在Matlab中,有以下的函数命令来计算向量之间的距离;
dist(w,p): 计算中的每个行向量和中每个列向量之间的欧式距离;
mandist(w,p): 绝对值距离。
计算中各行向量到中各列向量之间的欧氏距离,

若![]() ,则第个湖泊属于第级。
,则第个湖泊属于第级。
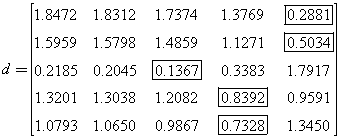
这说明杭州西湖,武汉东湖都属于极富营养水质,青海湖属于中营养水质,而巢湖和滇池属于富营养水质。
同时也可以计算中各行向量到中各列向量之间的绝对值距离![]()
若![]() ,则第个湖泊属于第级。
,则第个湖泊属于第级。

其评价结果与利用欧氏距离得到的评价结果完全一样。
所以,从上面的计算可以看出,尽管欧氏距离和绝对值距离的意义完全不一样,但对湖泊水质的评价等级是一样的,这表明了方法的稳定性。
程序
X=[130 10.3 0.35 2.76;
105 10.7 0.4 2;
20 1.4 4.5 0.22
30 6.26 0.25 1.67 ;
20 10.13 0.5 0.23];
A1=X(:,1)./130;
A2=X(:,2)./10.7;
A3=0.25./X(:,3);
A4=X(:,4)./2.76;
A=[A1 A2 A3 A4];
Y=[1 4 23 100 660;
0.09 0.36 1.8 7.1 27.1;
37 12 2.4 0.55 0.17;
0.02 0.06 0.31 1.2 4.6];
B1=Y(1,:)./660;
B2=Y(2,:)./27.1;
B3=0.17./Y(3,:);
B4=Y(4,:)./4.6;
B=[B1;B2;B3;B4];
% dist是一个欧式距离加权函数,给一个输入使用权值,去获得加权的输入
% dist(W,P)中:W——S×R的权值矩阵;P——R×Q的矩阵,表示Q个输入(列)向量
% dist(w,p): 计算中的每个行向量和中每个列向量之间的欧式距离;
jd=dist(A,B);
jd
% mandist(w,p): 绝对值距离
mjd=mandist(A,B);
mjd
结果
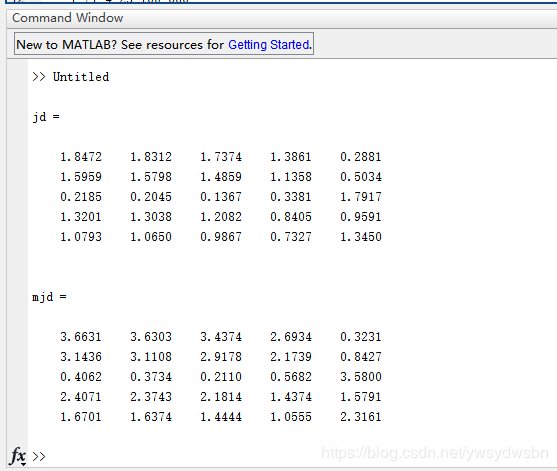
备注
各位老铁养成习惯,看完点个赞呗,随便也来个关注!!!
各位老铁养成习惯,看完点个赞呗,随便也来个关注!!!
各位老铁养成习惯,看完点个赞呗,随便也来个关注!!!
