【竞赛经验】中国移动人群画像赛TOP1

朋友咨询我作为一名没有竞赛经验的新手如何在竞赛中一步步成长并且最终取得优异成绩。希望能够通过这篇文章让一些数据竞赛入门者及爱好者从中学习到相关的比赛经验和思考历程。在本文中我将以中国移动人群画像赛为基础,从零开始,带领大家一步步完成新手到冠军的竞赛历程,实现冠军之路复盘。希望我的分享与总结能给大家带来些许帮助。
简要介绍
赛题页面
赛题信息
随着社会信用体系建设的深入推进, 社会信用标准建设飞速发展,相关的标准相继发布,包括信用服务标准、信用数据釆集和服务标准、信用修复标准、城市信用标准、行业信用标准等在内的多层次标准体系亟待出台,社会信用标准体系有望快速推进。社会各行业信用服务机构深度参与广告、政务、涉金融、共享单车、旅游、重大投资项目、教育、环保以及社会信用体系建设,社会信用体系建设是个系统工程,通讯运营商作为社会企业中不可缺少的部分同样需要打造企业信用评分体系,助推整个社会的信用体系升级。同时国家也鼓励推进第三方信用服务机构与政府数据交换,以增强政府公共信用信息中心的核心竞争力。
传统的信用评分主要以客户消费能力等少数的维度来衡量,难以全面、客观、及时的反映客户的信用。中国移动作为通信运营商拥有海量、广泛、高质量、高时效的数据,如何基于丰富的大数据对客户进行智能评分是中国移动和新大陆科技集团目前攻关的难题。运营商信用智能评分体系的建立不仅能完善社会信用体系,同时中国移动内部也提供了丰富的应用价值,包括全球通客户服务品质的提升、客户欠费额度的信用控制、根据信用等级享受各类业务优惠等,希望通过本次建模比赛,征集优秀的模型体系,准确评估用户信用分值。
数据清单
train_dataset.zip:训练数据,包含50000行
test_dataset.zip:测试集数据,包含50000行
数据说明
本次提供数据主要包含用户几个方面信息:身份特征、消费能力、人脉关系、位置轨迹、应用行为偏好。字段说明如下:
字段列表 字段说明
用户编码 数值 唯一性
用户实名制是否通过核实 1为是0为否
用户年龄 数值
是否大学生客户 1为是0为否
是否黑名单客户 1为是0为否
是否4G不健康客户 1为是0为否
用户网龄(月) 数值
用户最近一次缴费距今时长(月) 数值
缴费用户最近一次缴费金额(元) 数值
用户近6个月平均消费话费(元) 数值
用户账单当月总费用(元) 数值
用户当月账户余额(元) 数值
缴费用户当前是否欠费缴费 1为是0为否
用户话费敏感度 用户话费敏感度一级表示敏感等级最大。根据极值计算法、叶指标权重后得出的结果,根据规则,生成敏感度用户的敏感级别:先将敏感度用户按中间分值按降序进行排序,前5%的用户对应的敏感级别为一级:接下来的15%的用户对应的敏感级别为二级;接下来的15%的用户对应的敏感级别为三级;接下来的25%的用户对应的敏感级别为四级;最后40%的用户对应的敏感度级别为五级。
当月通话交往圈人数 数值
是否经常逛商场的人 1为是0为否
近三个月月均商场出现次数 数值
当月是否逛过福州仓山万达 1为是0为否
当月是否到过福州山姆会员店 1为是0为否
当月是否看电影 1为是0为否
当月是否景点游览 1为是0为否
当月是否体育场馆消费 1为是0为否
当月网购类应用使用次数 数值
当月物流快递类应用使用次数 数值
当月金融理财类应用使用总次数 数值
当月视频播放类应用使用次数 数值
当月飞机类应用使用次数 数值
当月火车类应用使用次数 数值
当月旅游资讯类应用使用次数 数值评价方式

全面探索
万变不离其宗,首先我们作为一名数据竞赛选手,拿到数据应该进行分析观察,让自己对竞赛题型、数据大致了解,下面开始数据整体探索。
""" 导入基本库 """
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
plt.style.use("bmh")
plt.rc('font', family='SimHei', size=13)
pd.set_option('display.max_columns',1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth',1000)在数据清单我们知道本次竞赛有一个训练集压缩包和一个预测集压缩包,在文件夹中解压后直接进行合并,以便后续数据内容变换的统一处理。
""" 导入数据 """
data_path = '../'
test_data = pd.read_csv(data_path + 'test_dataset.csv')
train_data = pd.read_csv(data_path + 'train_dataset.csv')
df_data = pd.concat([train_data, test_data], ignore_index=True)
df_data.head()

""" 数据属性 """
df_data.info()
print()
print("共有数据集:", df_data.shape[0])
print("共有测试集:", test_data.shape[0])
print("共有训练集:", train_data.shape[0])
结论:数据集情况与数据清单相对应,说明我们数据没有下载错误,合并后100000行,可以看到合并数据集特征列中全为数值型特征并且不存在缺失值。在这里,比赛刚开始的时候,一个新手与数据敏感高手的区别就开始体现出来,新手通常会直接忽略该信息。但是我们试着推理一下,中国移动公司获取一个从不开定位的手机信息和一个从不移动的家用手机信息商场出现次数,是应该有区别的,那么从不开定位就是一种缺失值,但在赛题中并没有出现。经过咨询大赛主办方人员,收到反馈是直接将所有缺失值填补为0,导致数据集中不存在缺失值,与推理一致。
""" 数据类别 """
for i,name in enumerate(df_data.columns):
name_sum = df_data[name].value_counts().shape[0]
print("{:2}、{:15} The number of types of features is:{}".format(i + 1, name, name_sum))
""" 数据统计 """
df_data.describe()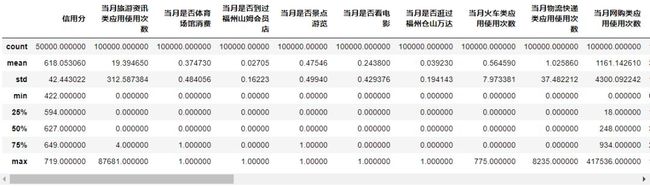
""" 观察训练/测试集数据同分布状况 """
df_data[df_data['信用分'].isnull()].describe()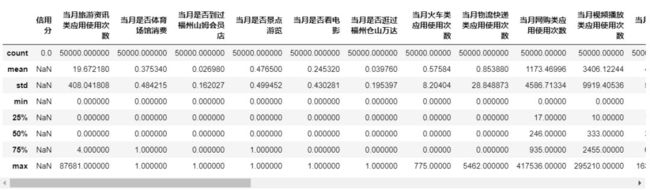
df_data[df_data['信用分'].notnull()].describe()
结论一:数据集情况较好,特征全为数值型特征,我们直接建立模型进行提交验证线下分数。但是大部分的特征存在类拖尾情况,如当月旅游资讯类应用使用次数特征中max为87681次,明显偏离mean约为19的次数,后续我们将会对这些特征单独分析。
结论二:通常一个人的信用分的发展规律是获得基础分,随着时间推移,会有加分事件,和减分事件的发生。伴随着这些事件,信用分逐步上涨或降低。但是对于赛题本身,绝大部份特征属于正面特征。相应的违约,失信记录等负面特征较少。这会导致模型对高信用分结果预测较为准确,低信用分结果预测偏差较大。
结论三:训练集与测试集中都存在拖尾数据,所以拖尾数据不一定是异常数据,需要经过线下验证才能确定。
初级特征探索(数据预处理)
接下来开始分析特征与信用分的关联性、开展相关的初级特征探索。很多新手经常在特征探索容易出现无从下手的情况,在这里作者新手推荐两种方案,1:按照特征顺序,2:按照连续、离散、非结构化特征顺序来进行特征探索,总之要先上手为强。高手在经历一定的比赛以后就会开始总结出根据业务场景相关的特征探索思路。
""" 拖尾/顺序特征分析 """
f, ax = plt.subplots(figsize=(20, 6))
sns.scatterplot(data=df_data, x='当月通话交往圈人数', y='信用分', color='k', ax=ax)
plt.show()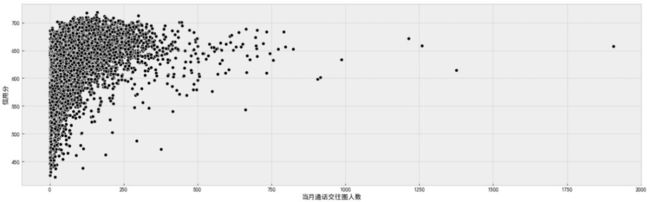
name_list = ['当月旅游资讯类应用使用次数', '当月火车类应用使用次数', '当月物流快递类应用使用次数', '当月网购类应用使用次数',
'当月视频播放类应用使用次数', '当月金融理财类应用使用总次数', '当月飞机类应用使用次数', '用户年龄',
'用户当月账户余额(元)', '用户账单当月总费用(元)', '用户近6个月平均消费值(元)', '缴费用户最近一次缴费金额(元)']
f, ax = plt.subplots(3, 4, figsize=(20, 20))
for i,name in enumerate(name_list):
sns.scatterplot(data=df_data, x=name, y='信用分', color='b', ax=ax[i // 4][i % 4])
plt.show()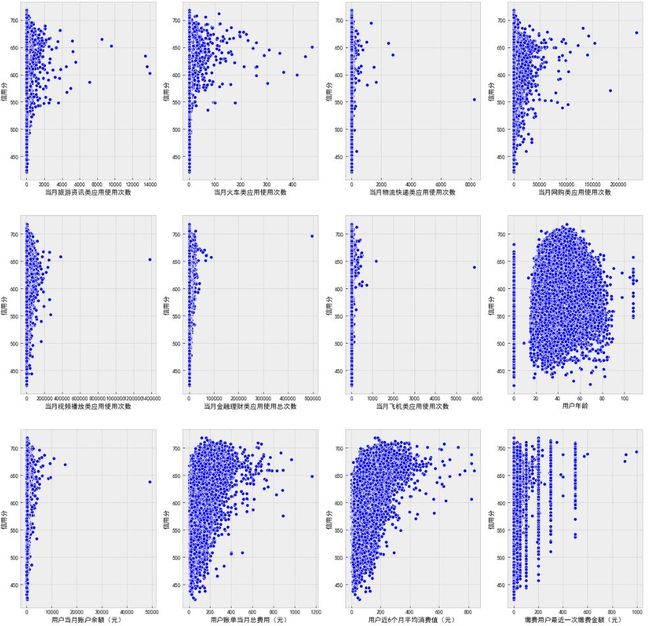
f, ax = plt.subplots(1, 3, figsize=(20, 6))
sns.kdeplot(data=df['当月飞机类应用使用次数'], color='r', shade=True, ax=ax[0])
sns.kdeplot(data=df['当月火车类应用使用次数'], color='c', shade=True, ax=ax[1])
sns.kdeplot(data=df['当月旅游资讯类应用使用次数'], color='b', shade=True, ax=ax[2])
plt.show()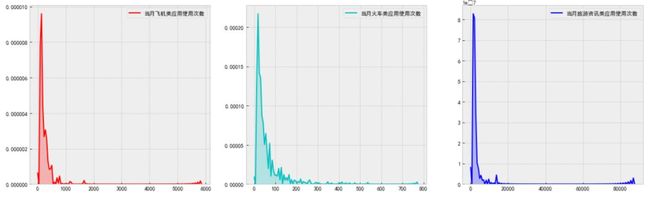
结论:观察前面提到的拖尾型特征在上述散点图中的确存在相关的拖尾现象,但是拖尾数据不一定就是无效数据,就像缺失值自己也可能代表某种意义一样,后期在处理拖尾数据时应结合模型进行线下验证。
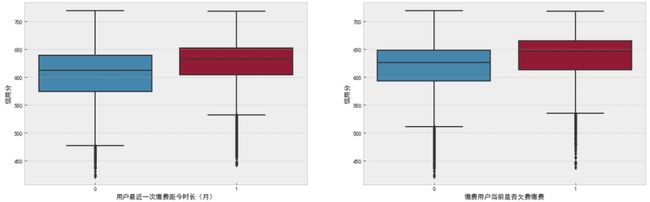
""" 离散特征分析 """
f, ax = plt.subplots(1, 2, figsize=(20, 6))
sns.boxplot(data=df_data, x='用户最近一次缴费距今时长(月)', y='信用分', ax=ax[0])
sns.boxplot(data=df_data, x='缴费用户当前是否欠费缴费', y='信用分', ax=ax[1])
plt.show()
name_list = ['当月是否体育场馆消费', '当月是否到过福州山姆会员店', '当月是否景点游览', '当月是否看电影', '当月是否逛过福州仓山万达',
'是否4G不健康客户', '是否大学生客户', '是否经常逛商场的人', '是否黑名单客户', '用户实名制是否通过核实']
f, ax = plt.subplots(2, 5, figsize=(20, 12))
for i,name in enumerate(name_list):
sns.boxplot(data=df_data, x=name, y='信用分', ax=ax[i // // 5][i % 5])
plt.show()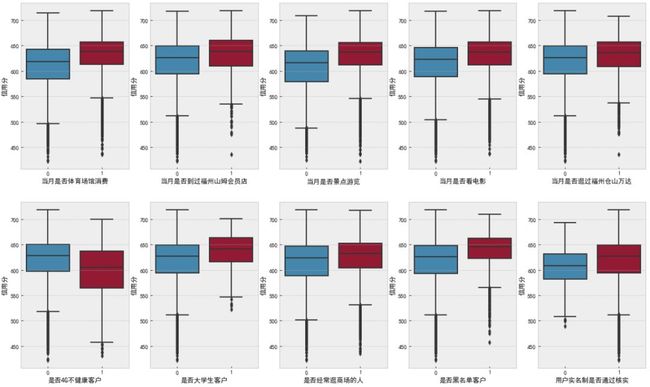
f, ax = plt.subplots(figsize=(10, 6))
sns.boxplot(data=df_data, x='用户话费敏感度', y='信用分', ax=ax)
plt.show()
数据预处理涉及的内容很多,也包括特征工程,是任务量最大的一部分。为了让大家更清晰的阅读,以下先列出处理部分大致要用到的一些方法。

最终确定的初级探索工程代码:
"""
为什么只取消一个特征的拖尾,其它特征拖尾为什么保留,即使线下提高分数也要
保留,这是因为在线下中比如逛商场拖尾的数据真实场景下可能为保安,在
训练集中可能只有一个保安,所以去掉以后线下验证会提高,但是在测试集
中也存在一个保安,如果失去拖尾最终会导致测试集保安信用分精度下降
"""
df_data.drop(df_data[df_data['当月通话交往圈人数'] > 1750].index, inplace=True)
df_data.reset_index(drop=True, inplace=True)
""" 0替换np.nan,通过线下验证发现数据实际情况缺失值数量大于0值数量,np.nan能更好的还原数据真实性 """
na_list = ['用户年龄', '缴费用户最近一次缴费金额(元)', '用户近6个月平均消费值(元)','用户账单当月总费用(元)']
for na_fea in na_list:
df_data[na_fea].replace(0, np.nan, inplace=True)
""" 话费敏感度0替换,通过线下验证发现替换为中位数能比np.nan更好的还原数据真实性 """
df_data['用户话费敏感度'].replace(0, df_data['用户话费敏感度'].mode()[0], inplace=True)结论:通过多次观察离散型特征,让我们对于数据的理解加深,比如用户话费敏感度特征并不是用户在现实世界中直接产生,而是由中国移动特定的关联模型通过计算产生,能够在很大程度上反应用户对于信用的关联程度。在箱型图中,用户敏感度呈现出高斯分布结果,符合我们对于业务场景的猜想。
中级特征探索(数据预工程)
通过初级的特征探索能够让我们加深对数据的理解并且实现初步的数据预处理, 接下来我们开始分析特征与特征之间对于信用分的影响、开展相关的中级特征探索。中级特征探索一般都是基于业务场景,但是作为新手在竞赛中可以简单的凭借感觉来关联特征进行分析。
f, ax = plt.subplots(figsize=(20, 6))
sns.boxenplot(data=df_data, x='当月是否逛过福州仓山万达', y='信用分', hue='当月是否到过福州山姆会员店', ax=ax)
plt.show()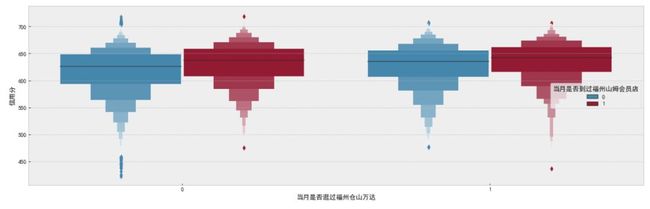
""" 离散型探索 """
f, [ax0, ax1, ax2, ax3, ax4] = plt.subplots(1, 5, figsize=(20, 6))
sns.boxplot(data=df_data, x='当月是否逛过福州仓山万达', y='信用分', hue='是否经常逛商场的人', ax=ax0)
sns.boxplot(data=df_data, x='当月是否到过福州山姆会员店', y='信用分', hue='是否经常逛商场的人', ax=ax1)
sns.boxplot(data=df_data, x='当月是否看电影', y='信用分', hue='是否经常逛商场的人', ax=ax2)
sns.boxplot(data=df_data, x='当月是否景点游览', y='信用分', hue='是否经常逛商场的人', ax=ax3)
sns.boxplot(data=df_data, x='当月是否体育场馆消费', y='信用分', hue='是否经常逛商场的人', ax=ax4)
plt.show()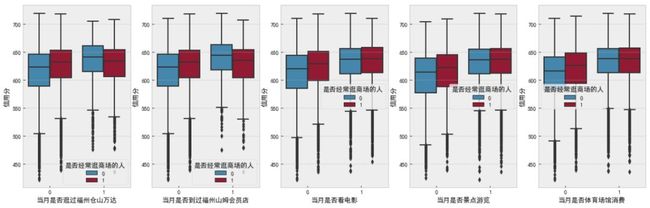
""" 连续型探索 """
f, ax = plt.subplots(1, 2, figsize=(20, 6))
sns.scatterplot(data=df_data, x='用户账单当月总费用(元)', y='信用分', color='b', ax=ax[0])
sns.scatterplot(data=df_data, x='用户当月账户余额(元)', y='信用分', color='r', ax=ax[1])
plt.show()
f, ax = plt.subplots(1, 2, figsize=(20, 6))
sns.scatterplot(data=df_data, x='用户账单当月总费用(元)', y='信用分', color='b', ax=ax[0])
sns.scatterplot(data=df_data, x='用户近6个月平均消费值(元)', y='信用分', color='r', ax=ax[1])
plt.show()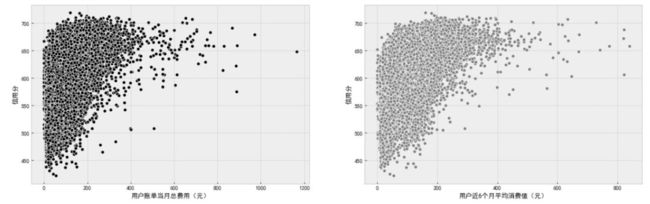
f, [ax0, ax1, ax2, ax3] = plt.subplots(1, 4, figsize=(20, 6))
sns.scatterplot(data=df_data, x='当月网购类应用使用次数', y='信用分', hue='是否经常逛商场的人', ax=ax0)
sns.scatterplot(data=df_data, x='当月物流快递类应用使用次数', y='信用分', hue='是否经常逛商场的人', ax=ax1)
sns.scatterplot(data=df_data, x='当月金融理财类应用使用总次数', y='信用分', hue='是否经常逛商场的人', ax=ax2)
sns.scatterplot(data=df_data, x='当月视频播放类应用使用次数', y='信用分', hue='是否经常逛商场的人', ax=ax3)
plt.show()
f, [ax0, ax1, ax2, ax3] = plt.subplots(1, 4, figsize=(20, 6))
sns.scatterplot(data=df_data, x='当月飞机类应用使用次数', y='信用分', hue='是否经常逛商场的人', ax=ax0)
sns.scatterplot(data=df_data, x='当月火车类应用使用次数', y='信用分', hue='是否经常逛商场的人', ax=ax1)
sns.scatterplot(data=df_data, x='当月旅游资讯类应用使用次数', y='信用分', hue='是否经常逛商场的人', ax=ax2)
sns.scatterplot(data=df_data, x='上网次数', y='信用分', hue='是否经常逛商场的人', ax=ax3)
plt.show()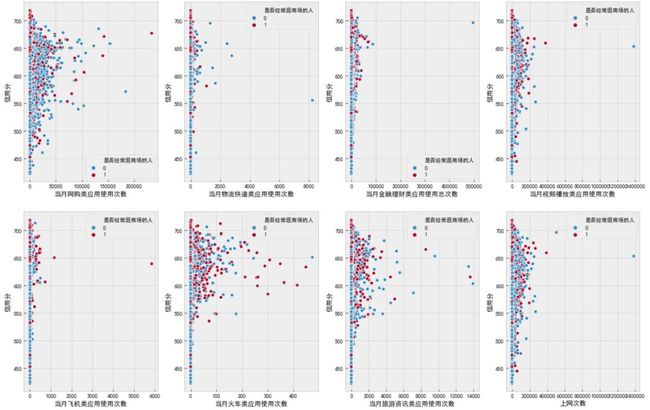
最终确定的中级探索工程代码:
""" x / (y + 1) 避免无穷值Inf,采用高斯平滑 + 1 """
df_data['话费稳定'] = df_data['用户账单当月总费用(元)'] / (df_data['用户当月账户余额(元)'] + 1)
df_data['相比稳定'] = df_data['用户账单当月总费用(元)'] / (df_data['用户近6个月平均消费值(元)'] + 1)
df_data['缴费稳定'] = df_data['缴费用户最近一次缴费金额(元)'] / (df_data['用户近6个月平均消费值(元)'] + 1)
df_data['当月是否去过豪华商场'] = (df_data['当月是否逛过福州仓山万达'] + df_data['当月是否到过福州山姆会员店']).map(lambda x: 1 if x > 0 else 0)
df_data['应用总使用次数'] = df_data['当月网购类应用使用次数'] + df_data['当月物流快递类应用使用次数'] + df_data['当月金融理财类应用使用总次数'] + df_data['当月视频播放类应用使用次数'] + df_data['当月飞机类应用使用次数'] + df_data['当月火车类应用使用次数'] + df_data['当月旅游资讯类应用使用次数']结论:通过大量的中级探索能够让我们加深对于数据之间的关联性更深刻,在进行中级探索的时候应该结合模型进行线下稳定的验证测试,在一些结构化竞赛中通过大量的中级探索就能够在竞赛中进入10%。
高级特征探索(数据真场景)
在数据竞赛中,想要获得高名次甚至拿下奖牌,除了需要扎实的特征工程基础,还需要对数据有着深刻的业务理解,能够将数据隐藏的信息进行挖掘提取,下面我将对该赛题进行高级特征探索。
1、对特征本身进行业务角度解读,提取出关键信息
通过对特征出处的挖掘,我们对缴费用户最近一次缴费金额(元)特征进行业务角度观察,发现该特征具有重要的隐藏含义,如有些用户没有缴费金额信息,也有些缴费金额存在个位数存在金额时缴费用户可能是通过互联网、自动缴费机等手段进行缴费,最终我们根据以上分析提取了用户缴费方式特征。

df_data['缴费方式'] = 0
df_data.loc[(df_data['缴费用户最近一次缴费金额(元)'] != 0) & (df_data['缴费用户最近一次缴费金额(元)'] % 10 == 0), '缴费方式'] = 1
df_dataf.loc[(df_data['缴费用户最近一次缴费金额(元)'] != 0) & (df_data['缴费用户最近一次缴费金额(元)'] % 10 > 0), '缴费方式'] = 2
f, ax = plt.subplots(figsize=(20, 6))
sns.boxplot(data=df_data, x='缴费方式', y='信用分', ax=ax)
plt.show()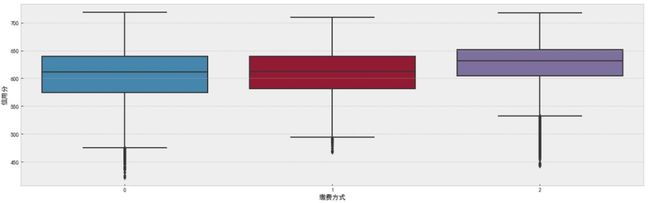
df['信用资格'] = df['用户网龄(月)'].apply(lambda x: 1 if x > 12 else 0)
f, ax = plt.subplots(figsize=(10, 6))
sns.boxenplot(data=df, x='信用资格', y='信用分', ax=ax)
plt.show()
data['敏度占比'] = data['用户话费敏感度'].map({1:1, 2:3, 3:3, 4:4, 5:8})
f, ax = plt.subplots(1, 2, figsize=(20, 6))
sns.boxenplot(data=df_data, x='敏度占比', y='信用分', ax=ax[0])
sns.boxenplot(data=df_data, x='用户话费敏感度', y='信用分', ax=ax[1])
plt.show()
""" 模型参数为作者祖传参数 """
lgb_param_l1 = {
'learning_rate': 0.01,
'boosting_type': 'gbdt',
'objective': 'regression_l1',
'metric': 'mae',
'min_child_samples': 46,
'min_child_weight': 0.01,
'feature_fraction': 0.6,
'bagging_fraction': 0.8,
'bagging_freq': 2,
'num_leaves': 31,
'max_depth': 5,
'lambda_l2': 1,
'lambda_l1': 0,
'n_jobs': -1,
'seed': 4590,
}
n_fold = 5
y_counts = 0
y_scores = np.zeros(5)
y_pred_l1 = np.zeros([5, X_pred.shape[0]])
y_pred_all_l1 = np.zeros(X_pred.shape[0])
for n in range(1):
kfold = KFold(n_splits=n_fold, shuffle=True, random_state=2019 + n)
kf = kfold.split(X, y)
for i, (train_iloc, test_iloc) in enumerate(kf):
print("{}、".format(i + 1), end='')
X_train, X_test, y_train, y_test = X.iloc[train_iloc, :], X.iloc[test_iloc, :], y[train_iloc], y[test_iloc]
lgb_train = lgb.Dataset(X_train, y_train)
lgb_valid = lgb.Dataset(X_test, y_test, reference=lgb_train)
lgb_model = lgb.train(train_set=lgb_train, valid_sets=lgb_valid, fev
params=lgb_param_l1, num_boost_round=6000, verbose_eval=-1, early_stopping_rounds=100)
y_scores[y_counts] = lgb_model.best_score['valid_0']['acc_score']
y_pred_l1[y_counts] = lgb_model.predict(X_pred, num_iteration=lgb_model.best_iteration)
y_pred_all_l1 += y_pred_l1[y_counts]
y_counts += 1
y_pred_all_l1 /= y_counts
print(y_scores, y_scores.mean())
def feval_lgb(y_pred, train_data):
y_true = train_data.get_label()
y_pred = np.argmax(y_pred.reshape(7, -1), axis=0)
score = 1 / (1 + mean_absolute_error(y_true, y_pred))
return 'acc_score', score, True
lgb_param_l1 = {
'learning_rate': 0.01,
'boosting_type': 'gbdt',
'objective': 'regression_l1',
'metric': 'None',
'min_child_samples': 46,
'min_child_weight': 0.01,
'feature_fraction': 0.6,
'bagging_fraction': 0.8,
'bagging_freq': 2,
'num_leaves': 31,
'max_depth': 5,
'lambda_l2': 1,
'lambda_l1': 0,
'n_jobs': -1,
'seed': 4590,
}
n_fold = 5
y_counts = 0
y_scores = np.zeros(5)
y_pred_l1 = np.zeros([5, X_pred.shape[0]])
y_pred_all_l1 = np.zeros(X_pred.shape[0])
for n in range(1):
kfold = KFold(n_splits=n_fold, shuffle=True, random_state=2019 + n)
kf = kfold.split(X, y)
for i, (train_iloc, test_iloc) in enumerate(kf):
print("{}、".format(i + 1), end='')
X_train, X_test, y_train, y_test = X.iloc[train_iloc, :], X.iloc[test_iloc, :], y[train_iloc], y[test_iloc]
lgb_train = lgb.Dataset(X_train, y_train)
lgb_valid = lgb.Dataset(X_test, y_test, reference=lgb_train)
lgb_model = lgb.train(train_set=lgb_train, valid_sets=lgb_valid, feval=feval_lgb,
params=lgb_param_l1, num_boost_round=6000, verbose_eval=-1, early_stopping_rounds=100)
y_scores[y_counts] = lgb_model.best_score['valid_0']['acc_score']
y_pred_l1[y_counts] = lgb_model.predict(X_pred, num_iteration=lgb_model.best_iteration)
y_pred_all_l1 += y_pred_l1[y_counts]
y_counts += 1
y_pred_all_l1 /= y_counts
print(y_scores, y_scores.mean())
lgb_param_l1 = {
'learning_rate': 0.01,
'boosting_type': 'gbdt',
'objective': 'regression_l1',
'metric': 'None',
'min_child_samples': 46,
'min_child_weight': 0.01,
'feature_fraction': 0.6,
'bagging_fraction': 0.8,
'bagging_freq': 2,
'num_leaves': 31,
'max_depth': 5,
'lambda_l2': 1,
'lambda_l1': 0,
'n_jobs': -1,
'seed': 4590,
}
lgb_param_l2 = {
'learning_rate': 0.01,
'boosting_type': 'gbdt',
'objective': 'regression_l2',
'metric': 'None',
'feature_fraction': 0.6,
'bagging_fraction': 0.8,
'bagging_freq': 2,
'num_leaves': 40,
'max_depth': 7,
'lambda_l2': 1,
'lambda_l1': 0,
'n_jobs': -1,
}
submit = pd.DataFrame()
submit['id'] = data[data['信用分'].isnull()]['用户编码']
submit['score1'] = y_pred_all_l1
submit['score2'] = y_pred_all_l2
submit = submit.sort_values('score1')
submit['rank'] = np.arange(submit.shape[0])
min_rank = 100
max_rank = 50000 - min_rank
l1_ext_rate = 1
l2_ext_rate = 1 - l1_ext_rateil_ext = (submit['rank'] <= min_rank) | (submit['rank'] >= max_rank)
l1_not_ext_rate = 0.5
l2_not_ext_rate = 1 - l1_not_ext_rate
il_not_ext = (submit['rank'] > min_rank) & (submit['rank'] < max_rank)
submit['score'] = 0
submit.loc[il_ext, 'score'] = (submit[il_ext]['score1'] * l1_ext_rate + submit[il_ext]['score2'] * l2_ext_rate + 1 + 0.25)
submit.loc[il_not_ext, 'score'] = submit[il_not_ext]['score1'] * l1_not_ext_rate + submit[il_not_ext]['score2'] * l2_not_ext_rate + 0.25
""" 输出文件 """
submit[['id', 'score']].to_csv('submit.csv')