问题一:如何拆分含有多种分隔符的字符串?
问题内容:
我们要把某个字符串依据分隔符号拆分不同的字段,该字段包含多种不同的分隔符,例如:
s = 'ab;cd|efg|hi,jkl|mn\topq;rst,uvw\txyz'
其中的 , | ; \t 都是分隔符号,如何处理?
对于单一的分隔符:
In [4]: x = !ps aux
In [5]: s = x[-1]
In [6]: s
Out[6]: 'root 32487 0.0 0.0 0 0 ? S 09:44 0:01 [kworker/u24:0]'
In [7]: s.split?
Docstring:
S.split(sep=None, maxsplit=-1) -> list of strings
Return a list of the words in S, using sep as the
delimiter string. If maxsplit is given, at most maxsplit
splits are done. If sep is not specified or is None, any
whitespace string is a separator and empty strings are
removed from the result.
Type: builtin_function_or_method
In [8]: s.split()
Out[8]:
['root',
'32487',
'0.0',
'0.0',
'0',
'0',
'?',
'S',
'09:44',
'0:01',
'[kworker/u24:0]']
解决方案:
方法一:连续使用str.split()方法,每次处理一个分隔符号。
方法二:使用正则表达式的re.split()方法,一次性拆分字符串。
方法一:
In [9]: s = 'ab;cd|efg|hi,jkl|mn\topq;rst,uvw\txyz'
In [10]: s.split(';')
Out[10]: ['ab', 'cd|efg|hi,jkl|mn\topq', 'rst,uvw\txyz']
In [11]: res = s.split(';')
In [12]: map(lambda x: x.split('|'),res)
Out[12]: 根据上面的逻辑,我们可以写个函数
In [44]: def mySplit(s,ds):
...: res = [s]
...: for d in ds:
...: t = []
...: list(map(lambda x: t.extend(x.split(d)),res))
...: res = t
...: return res
...:
In [45]: s = 'ab;cd|efg|hi,jkl|mn\topq;rst,uvw\txyz'
In [46]: mySplit(s,';,|\t')
Out[46]: ['ab', 'cd', 'efg', 'hi', 'jkl', 'mn', 'opq', 'rst', 'uvw', 'xyz']
但是有两个分隔符连续的时候就会生成空的字符串
In [47]: s = 'ab;;cd|efg|hi,jkl|mn\topq;rst,uvw\txyz'
In [48]: mySplit(s,';,|\t')
Out[48]: ['ab', '', 'cd', 'efg', 'hi', 'jkl', 'mn', 'opq', 'rst', 'uvw', 'xyz']
我们修改函数,当字符串不为空的时候才返回
In [49]: def mySplit(s,ds):
...: res = [s]
...: for d in ds:
...: t = []
...: list(map(lambda x: t.extend(x.split(d)),res))
...: res = t
...: return [x for x in res if x ]
...:
...:
In [50]: s = 'ab;;cd|efg|hi,jkl|mn\topq;rst,uvw\txyz'
In [51]: mySplit(s,';,|\t')
Out[51]: ['ab', 'cd', 'efg', 'hi', 'jkl', 'mn', 'opq', 'rst', 'uvw', 'xyz']
方法二:
In [56]: import re
In [57]: re.split?
Signature: re.split(pattern, string, maxsplit=0, flags=0)
Docstring:
Split the source string by the occurrences of the pattern,
returning a list containing the resulting substrings. If
capturing parentheses are used in pattern, then the text of all
groups in the pattern are also returned as part of the resulting
list. If maxsplit is nonzero, at most maxsplit splits occur,
and the remainder of the string is returned as the final element
of the list.
File: /usr/local/lib/python3.5/re.py
Type: function
In [58]: re.split(r'[;,|\t]+',s)
Out[58]: ['ab', 'cd', 'efg', 'hi', 'jkl', 'mn', 'opq', 'rst', 'uvw', 'xyz']
问题二:如何判断字符串a是否以字符串b开头或结尾?
问题内容:
某文件系统目录下有一些列文件:
qudsn.rc
cadbh.py
ajcn.java
njasd.sh
wneacm.cpp
......
编写程序给其中所有 .sh文件和 .py文件加上用户可执行权限。
解决方案:
使用字符串的str.startswitch()和str.endswith()方法
注意:多个匹配时参数使用元组
In [1]: ls
a.py b.sh c.java d.h e.cpp f.c
In [2]: import os,stat
In [3]: os.listdir('.')
Out[3]: ['a.py', 'b.sh', 'c.java', 'd.h', 'e.cpp', 'f.c']
In [4]: s = 'g.sh'
In [5]: s.endswith('.sh')
Out[5]: True
In [6]: s.endswith('.py')
Out[6]: False
当传入为元组的时候,只要有一个成立,就会返回True
In [7]: s.endswith(('.sh','.py'))
Out[7]: True
还有就是,传入的参数只能为元组,不能为列表
In [8]: s.endswith(['.sh','.py'])
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in ()
----> 1 s.endswith(['.sh','.py'])
TypeError: endswith first arg must be str or a tuple of str, not list
下面我们给指定文件授予权限:
In [9]: [ name for name in os.listdir('.') if name.endswith(('.sh','.py'))]
Out[9]: ['a.py', 'b.sh']
查看当前文件状态,其中的st_mode为状态码
In [11]: os.stat('a.py')
Out[11]: os.stat_result(st_mode=33188, st_ino=3678001, st_dev=2051, st_nlink=1, st_uid=0, st_gid=0, st_size=0, st_atime=1491533824, st_mtime=1491533824, st_ctime=1491533824)
In [12]: os.stat('a.py').st_mode
Out[12]: 33188
将状态码转为八进制,后三位就是我们平时看的777.
In [13]: oct(os.stat('a.py').st_mode)
Out[13]: '0o100644'
我们将状态码和stat.S_IXUSR 进行并集操作,X 代表执行,USR代表用户
In [17]: os.chmod('a.py',os.stat('a.py').st_mode | stat.S_IXUSR)
In [18]: os.stat('a.py').st_mode
Out[18]: 33252
文件被赋予执行权限
In [19]: ls -l
total 0
-rwxr--r-- 1 root root 0 Apr 7 10:57 a.py*
-rw-r--r-- 1 root root 0 Apr 7 10:57 b.sh
-rw-r--r-- 1 root root 0 Apr 7 10:57 c.java
-rw-r--r-- 1 root root 0 Apr 7 10:57 d.h
-rw-r--r-- 1 root root 0 Apr 7 10:57 e.cpp
-rw-r--r-- 1 root root 0 Apr 7 10:57 f.c
问题三:如何调整字符串中文本的格式?
问题内容:
某log文件,其中的日期格式为
......
t=2017-04-07T15:47:00+0800 lvl=eror msg="Metrics: GraphitePublisher: Failed to connect to [dial tcp [::1]:2003: getsockopt: connection refused]!"
t=2017-04-07T15:47:10+0800 lvl=eror msg="Metrics: GraphitePublisher: Failed to connect to [dial tcp [::1]:2003: getsockopt: connection refused]!"
t=2017-04-07T15:47:20+0800 lvl=eror msg="Metrics: GraphitePublisher: Failed to connect to [dial tcp [::1]:2003: getsockopt: connection refused]!"
t=2017-04-07T15:47:30+0800 lvl=eror msg="Metrics: GraphitePublisher: Failed to connect to [dial tcp [::1]:2003: getsockopt: connection refused]!"
......
我们想把其中的日期格式改为美国日期格式'mm/dd/yyyy','2017-04-07'=>'04/07/2017',该如何处理?
解决方案:
使用正则表达式re.sub()方法做字符串替换,利用正则表达式的捕获组,捕获每个部分内容,在替换字符串中调整各个捕获组的顺序。
In [8]: log = open('gdash.log').read()
In [9]: import re
In [10]: re.sub?
Signature: re.sub(pattern, repl, string, count=0, flags=0)
Docstring:
Return the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in string by the
replacement repl. repl can be either a string or a callable;
if a string, backslash escapes in it are processed. If it is
a callable, it's passed the match object and must return
a replacement string to be used.
File: /usr/local/lib/python3.5/re.py
Type: function
In [12]: re.sub('(\d{4})-(\d{2})-(\d{2})',r'\2/\3/\1',log)
其中的 \1 代表第一个组,我们还可以给组进行设置组名
In [14]: re.sub('(?P\d{4})-(?P\d{2})-(?P\d{2})',r'\g/\g/\g',log)
问题五:如何对字符串进行左,右,居中对齐?
某个字典存储了一系列属性值:
{
"lodDISt":1000.0,
"ejfmkd":0.01
"ajdmea":30.0
"jrfenim":322
}
在程序中,我们想以下面的工整的格式将其输出,如何处理?
lodDISt :1000.0,
ejfmkd :0.01
ajdmea :30.0
jrfenim :322
方法一:使用字符串的str.ljust(),str.rjust(),str.center()进行左,右,居中对齐。
方法二:使用format()方法,传递类似'<20','>20','^20'参数完成同样任务。
In [1]: s = 'abc'
查看方法的详解
In [2]: s.ljust?
Docstring:
S.ljust(width[, fillchar]) -> str
Return S left-justified in a Unicode string of length width. Padding is
done using the specified fill character (default is a space).
Type: builtin_function_or_method
In [3]: s.ljust(20)
Out[3]: 'abc '
传入的第二个参数为填充值
In [4]: s.ljust(20,'=')
Out[4]: 'abc================='
In [5]: s.rjust(20)
Out[5]: ' abc'
In [6]: len(s.rjust(20))
Out[6]: 20
In [7]: s.center(20)
Out[7]: ' abc '
使用format()方法
In [8]: format?
Signature: format(value, format_spec='', /)
Docstring:
Return value.__format__(format_spec)
format_spec defaults to the empty string
Type: builtin_function_or_method
左对齐:
In [9]: format(s,'<20')
Out[9]: 'abc '
右对齐:
In [10]: format(s,'>20')
Out[10]: ' abc'
居中:
In [11]: format(s,'^20')
Out[11]: ' abc '
我们看下问题内容:
In [14]: d
Out[14]: {'ajdmea': 30.0, 'ejfmkd': 0.01, 'jrfenim': 322, 'lodDISt': 1000.0}
In [15]: d.keys()
Out[15]: dict_keys(['lodDISt', 'jrfenim', 'ajdmea', 'ejfmkd'])
获得键长的列表
In [16]: map(len,d.keys())
Out[16]: 问题六:如何去掉字符串中不需要的字符
问题内容:
1,过滤掉用户输入中的前后多余的空白字符
2,过滤某windows下编辑文本中的'\r'
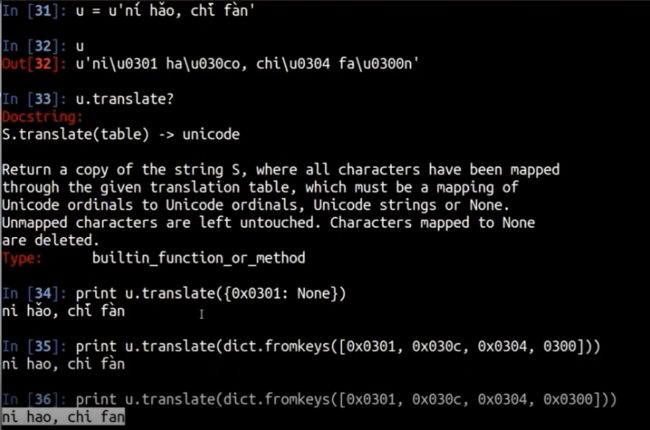
3,去掉文本中的unicode组合符号(音调)
解决方案:
方法一:字符串strip(),lstrip(),rstrip()方法去掉字符串两端字符
方法二:删除单个固定位置的字符,可以使用切片 + 拼接的方式
方法三:字符串的replace()方法或正则表达式re.sub()删除任一位置字符
方法四:字符串translate()方法,可以同事删除多种不同字符
去除前后的空白
In [21]: s = ' abc 123 '
In [22]: s.strip?
Docstring:
S.strip([chars]) -> str
Return a copy of the string S with leading and trailing
whitespace removed.
If chars is given and not None, remove characters in chars instead.
Type: builtin_function_or_method
当为指定字符时,默认去除空白字符
In [23]: s.strip()
Out[23]: 'abc 123'
In [24]: s.lstrip()
Out[24]: 'abc 123 '
In [25]: s.rstrip()
Out[25]: ' abc 123'
In [26]: s = '---abc+++'
当指定去除字符的时候
In [27]: s.strip('-+')
Out[27]: 'abc'
In [28]: s.lstrip('-')
Out[28]: 'abc+++'
In [29]: s.rstrip('+')
Out[29]: '---abc'
删除固定位置的字符:
In [30]: s = 'abc:123'
去除字符串中的 :
In [31]: s[:3] + s[4:]
Out[31]: 'abc123'
使用替换方法:
In [32]: s = '\tabc\t123\t'
In [33]: s.replace('\t','')
Out[33]: 'abc123'
但是replace()方法只能替换单一的字符,当有多种字符的时候,可以使用正则表达式的sub()方法。
In [34]: s = '\tabc\t123\txyz\ropq\r'
In [35]: import re
In [36]: re.sub('[\t\r]','',s)
Out[36]: 'abc123xyzopq'
使用tanslate()方法
我们看下translate方法的选项,第一个是映射表,第二个是要删除的字符
In [37]: str.translate?
Docstring:
S.translate(table) -> str
Return a copy of the string S in which each character has been mapped
through the given translation table. The table must implement
lookup/indexing via __getitem__, for instance a dictionary or list,
mapping Unicode ordinals to Unicode ordinals, strings, or None. If
this operation raises LookupError, the character is left untouched.
Characters mapped to None are deleted.
Type: method_descriptor
In [38]: s = 'abc123456xyz'
In [42]: tal = str.maketrans('abcxyz','xyzabc')
In [43]: s.translate(tal)
Out[43]: 'xyz123456abc'
注意:在python3中,这两种方法被包含到str类的方法中,就是说不用import string就可以直接用两种方法。
使用translate()方法删除指定字符
In [54]: s = 'abc\refg\n234\t'
首先设置映射表
In [55]: map = str.maketrans('','','\r\t\n')
In [56]: s.translate(map)
Out[56]: 'abcefg234'
使用translate()方法,看截图