Scala之窗口函数排序
scala窗口函数这排序rank,重复排序和不重复排序
1、引入包
import org.apache.spark.sql.expressions.Window
import spark.implicits._
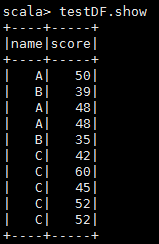
2.创建测试的df,可以直接粘贴测试。
val testDF =Seq(
("A", 50),
("B", 39),
("A", 48),
("A", 48),
("B", 35),
("C", 42),
("C", 60),
("C", 45),
("C", 52),
("C", 52)).toDF("name","score")
3.选择按name分组,按score排序,且倒序。
val byNameScoreDesc = Window.partitionBy("name").orderBy(col("score").desc)
![]()
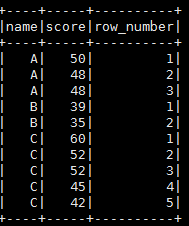
4.将序号新增一列到测试的testDF。这里使用了不重复排序。
testDF.withColumn("row_number",row_number.over(byNameScoreDesc)).show()
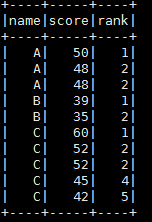
5.将序号新增一列到测试的testDF。这里使用了并列排序。
testDF.withColumn("rank",rank().over(byNameScoreDesc)).show()
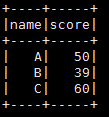
6.只选取唯一name的记录。
testDF.withColumn("row_number",row_number.over(byNameScoreDesc)).filter("row_number=1").drop("row_number").show()
参考链接:https://stackoverflow.com/questions/56776690/unable-to-recognise-windowing-function-in-intellij
https://sparkbyexamples.com/spark/spark-sql-window-functions/#ranking-functions