Python数据分析实战——杭州租房数据统计分析
本案例将租房网站上的杭州地区的租房数据作为参考,运用所学到的数据分析知识来分析真实数据,并以图表的形式得到以下指标:
- 统计每个区域的房源总数量。
- 使用条形图分析哪种户型数量最多、更受欢迎。
- 统计每个区域的平均租金,并结合柱状图和拆线图分析各区域的房源数量和租金情况。
- 统计面积区间的市场占有率,并使用饼图绘制各区间所占的比例。
一 、数据来源
目前有很多的网络租房平台,如链家、房天下、安居客、贝壳等等,通过八爪鱼采集器,共爬取到贝壳网上列出的租房信息18828条(去重后),采集信息包括所属区域、面积、朝向、户型、价格。
将采集到的数据保存为 csv 格式(贝壳杭州总租房信息.csv),采集结束时间为2020年3月10日。

二、数据读取
(本文章所有代码均在 Anaconda下运行)
数据准备好后,使用Pandas读取保存在本地的CSV数据,并将其转换成DataFrame对象展示,方便后续操作这些数据。
import pandas as pd
import numpy as np
#读取链家杭州租房信息
file_path=open('C:/Users/AQQWVFBUKN/Desktop/贝壳杭州总租房信息.csv','r', encoding='UTF-8')
file_data=pd.read_csv(file_path)
file_data
三、数据预处理
尽管采集到的数据大部分是比较完整的,但或多或或少还会存在一些问题,不能直接用于数据分析。因此 , 在进行数据分析前需要进行一系列的检测与处理,包括重复值和缺失值的处理、统计数据类型等,以保证数据具有更多的完整性。
3.1 重复值和空值的处理
(由于已经在excel表格中对数据的重复值和缺失值进行了处理,所以以下的处理会看到数据的总数不变)
查看数据中是否存在重复值,可以通过Pandas中的duplicated() 方法完成 ,只要有重复的数据就会映射为True ,具体代码如下
# 重复值检测
file_data.duplicated()
0 False
1 False
2 False
3 False
4 False
...
18823 False
18824 False
18825 False
18826 False
18827 False
Length: 18828, dtype: bool
这里对于重复数据的处理是将其删除,接下来使用 drop_duplicates() 方法直接删除重复数据,具体代码如下
# 删除重复数据,并对file_data 重新赋值
file_data=file_data.drop_duplicates()
file_data
地区 面积 朝向 户型 价格
0 上城 18 南 7室2厅 1800
1 上城 18 南 4室1厅 1860
2 上城 18 北 5室1厅 2000
3 上城 11 南 2室1厅 2230
4 上城 15 南 3室1厅 1800
... ... ... ... ... ...
18823 余杭 116 南 3室2厅 2500
18824 余杭 101 南北 3室1厅 2500
18825 余杭 119 南 4室2厅 2000
18826 余杭 126 南 3室2厅 2000
18827 余杭 15 南 4室1厅 1530
18828 rows × 5 columns
对数据的重复值处理完成后,便开始检测缺失值,这里可以使用 dropna() 方法检测缺失值并将检测到的缺失数据删除。
# 删除缺失数据,并对file_data 重新赋值
file_data=file_data.dropna()
file_data
地区 面积 朝向 户型 价格
0 上城 18 南 7室2厅 1800
1 上城 18 南 4室1厅 1860
2 上城 18 北 5室1厅 2000
3 上城 11 南 2室1厅 2230
4 上城 15 南 3室1厅 1800
... ... ... ... ... ...
18823 余杭 116 南 3室2厅 2500
18824 余杭 101 南北 3室1厅 2500
18825 余杭 119 南 4室2厅 2000
18826 余杭 126 南 3室2厅 2000
18827 余杭 15 南 4室1厅 1530
18828 rows × 5 columns
3.2 数据类型转换
在这套租房数据中,“价格” 一列的数据中含有中文字符和回车符,说明这一列的数据都是字符串类型的。为了方便后面对价格数据进行数学运算,需要将 “价格” 一列的数据类型转换为数字类型,具体代码如下
list1=[]
for i in file_data['价格'].values:
list1.append("".join(filter(str.isdigit, i))) # 去除掉字符串中的非数字字符
numbers = [ int(x) for x in list1 ]# 字符串类型转换成 int 类型
# 用新的数据替换
file_data.loc[:,'价格']=numbers
file_data
地区 面积 朝向 户型 价格
0 上城 18 南 7室2厅 1800
1 上城 18 南 4室1厅 1860
2 上城 18 北 5室1厅 2000
3 上城 11 南 2室1厅 2230
4 上城 15 南 3室1厅 1800
... ... ... ... ... ...
18823 余杭 116 南 3室2厅 2500
18824 余杭 101 南北 3室1厅 2500
18825 余杭 119 南 4室2厅 2000
18826 余杭 126 南 3室2厅 2000
18827 余杭 15 南 4室1厅 1530
18828 rows × 5 columns
四、图表分析
数据经过预处理之后便可以用它来进行分析了,为了更加直观地看到数据的变化,这里采用图表的方式进行辅助分析。
4.1、房源数量分析
为了统计杭州各个区域的房源数量,这里只需要展示 ”地区” 与 “数量” 两列的数据即可。因此先创建一个DataFrame 对象,然后将各个区域计算的总房源数量作为该对象的数据进行展示,具体代码如下
# 创建一个dataframe 对象,该对象只有两列数据 :区域和数量
new_df=pd.DataFrame({'地区':file_data['地区'].unique(),
'数量':[0]*len(file_data['地区'].unique())})
new_df
地区 数量
0 上城 0
1 滨江 0
2 萧山 0
3 富阳 0
4 临安 0
5 钱塘新区 0
6 西湖 0
7 下城 0
8 拱墅 0
9 江干 0
10 余杭 0
接下来通过 Pandas的groupby() 方法将 file_data 对象按照 “地区” 一列进行分组,并用 count() 方法统计每个分组的数量
# 按”区域“列将file_data分组,并统计每个分组的数量
groupy_area=file_data.groupby(by='地区').count()
new_df['数量']=groupy_area.values
new_df
地区 数量
0 上城 1618
1 滨江 2405
2 萧山 466
3 富阳 1992
4 临安 481
5 钱塘新区 2324
6 西湖 2224
7 下城 679
8 拱墅 2210
9 江干 2381
10 余杭 2048
通过 sort_values() 方法对 new_df 对象进行排序,并按照从大到小的顺序进行排列,具体代码如下
# 按“数量”一列从大到小排列
new_df.sort_values(by=['数量'],ascending=False)
地区 数量
1 滨江 2405
9 江干 2381
5 钱塘新区 2324
6 西湖 2224
8 拱墅 2210
10 余杭 2048
3 富阳 1992
0 上城 1618
7 下城 679
4 临安 481
2 萧山 466
通过输出的排序结果可以看出,杭州租房房源数据位于前三的地区分别是滨江区、江干区、钱塘新区。
4.2、户型数量分析
接下来我们分析下户型,统计出租房市场中哪种户型的房源数量比较多,并筛选出数量大于50的户型。
首先,定义一个函数来计算各种户型的数量。
# 定义函数,用来计算各户型数量
def all_house(arr):
arr=np.array(arr)
key=np.unique(arr)
result={}
for k in key:
mask=(arr==k)
arr_new=arr[mask]
v=arr_new.size
result[k]=v
return result
# 获取户型数据
house_array=file_data['户型']
house_info=all_house(house_array)
house_info
{'1室0厅': 1087,
'1室1厅': 2920,
'1室2厅': 81,
'1室4厅': 1,
'2室0厅': 133,
'2室1厅': 3506,
'2室2厅': 1269,
'2室3厅': 1,
'3室0厅': 75,
'3室1厅': 2701,
'3室2厅': 2324,
'3室3厅': 6,
'4室0厅': 129,
'4室1厅': 2561,
'4室2厅': 710,
'4室3厅': 7,
'5室0厅': 118,
'5室1厅': 1016,
'5室2厅': 118,
'5室3厅': 26,
'5室4厅': 1,
'5室5厅': 1,
'6室0厅': 2,
'6室1厅': 3,
'6室2厅': 14,
'6室3厅': 4,
'6室4厅': 3,
'7室0厅': 1,
'7室1厅': 1,
'7室2厅': 2,
'7室3厅': 2,
'8室1厅': 1,
'8室2厅': 3,
'9室2厅': 1}
程序输出了一个字典,其中,字典的键表示户型的各类,值表示该户型的数量。
现在使用字典推导式将户型数量大于50的户型筛选出来,并将筛选后的结果转换成DataFrame 对象,具体代码如下
# 使用字典推导式
house_type=dict((key,value) for key,value in house_info.items() if value>50)
show_houses=pd.DataFrame({'户型':[x for x in house_type.keys()],
'数量':[x for x in house_type.values()]})
show_houses
户型 数量
0 1室0厅 1087
1 1室1厅 2920
2 1室2厅 81
3 2室0厅 133
4 2室1厅 3506
5 2室2厅 1269
6 3室0厅 75
7 3室1厅 2701
8 3室2厅 2324
9 4室0厅 129
10 4室1厅 2561
11 4室2厅 710
12 5室0厅 118
13 5室1厅 1016
14 5室2厅 118
为了能够更加直观地看到户型数量间的差异,可以使用条形图进行展示。
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif']=['SimHei']
matplotlib.rcParams['axes.unicode_minus']=False
house_type=show_houses['户型']
house_type_num=show_houses['数量']
plt.barh(range(15),house_type_num,height=0.7,color='steelblue',alpha=0.8)
plt.yticks(range(15),house_type)
plt.xlim(0,3800)
plt.xlabel('数量')
plt.ylabel('户型种类')
plt.title('杭州地区各户型房屋数量')
for x,y in enumerate(house_type_num):
plt.text(y+0.2,x-0.1,'%s'%y)
plt.show()
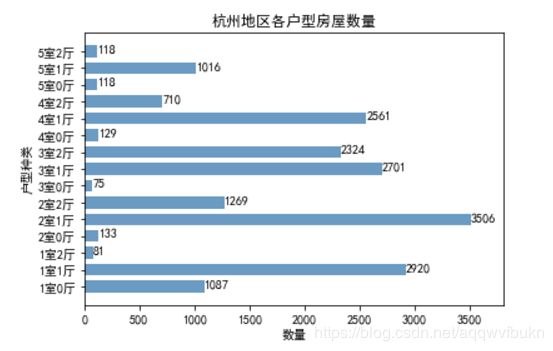
可以清晰地看出,整个租房市场中户型数量较多分别为 “2室1厅”、“1室1厅”、“3室1厅”。“2室1厅”户型的房屋是整个租房市场中数量最多的。
4.3、平均租金分析
为了进一步剖析房屋的情况,接下来分析各地区目前的平均租金情况。计算各地区房租的平均价格与计算各地区的户型数量的方法差不多,具体代码如下:
# 创建一个dataframe 对象,
df_all=pd.DataFrame({'地区':file_data['地区'].unique(),
'房租总金额':[0]*len(file_data['地区'].unique()),
'总面积':[0]*len(file_data['地区'].unique())
})
df_all
地区 房租总金额 总面积
0 上城 0 0
1 滨江 0 0
2 萧山 0 0
3 富阳 0 0
4 临安 0 0
5 钱塘新区 0 0
6 西湖 0 0
7 下城 0 0
8 拱墅 0 0
9 江干 0 0
10 余杭 0 0
按照 ”地区“ 一列进行分组,然后调用sum() 方法分别对价格和面积执行求和运算
# 求总金额和总面积
sum_price=file_data['价格'].groupby(file_data['地区']).sum()
sum_area=file_data['面积'].groupby(file_data['地区']).sum()
df_all['房租总金额']=sum_price.values
df_all['总面积']=sum_area.values
df_all
地区 房租总金额 总面积
0 上城 8721856 187774
1 滨江 10100330 139402
2 萧山 1110950 51465
3 富阳 3559163 126435
4 临安 1241946 47447
5 钱塘新区 9233878 142617
6 西湖 9054939 136073
7 下城 2483328 30072
8 拱墅 6522415 138026
9 江干 8185825 134994
10 余杭 6827318 146827
计算出各地区房租总金额和总面积之后,便可以对每平方米的租金进行计算。在 df_all 对的基础上增加一列 ”每平方米租金“,数据为求得的每平方米的平均价格。
# 计算各区域每平方米房租价格,并保留两位小数
df_all['每平方米租金']=round(df_all['房租总金额']/df_all['总面积'],2)
df_all
地区 房租总金额 总面积 每平方米租金
0 上城 8721856 187774 46.45
1 滨江 10100330 139402 72.45
2 萧山 1110950 51465 21.59
3 富阳 3559163 126435 28.15
4 临安 1241946 47447 26.18
5 钱塘新区 9233878 142617 64.75
6 西湖 9054939 136073 66.54
7 下城 2483328 30072 82.58
8 拱墅 6522415 138026 47.25
9 江干 8185825 134994 60.64
10 余杭 6827318 146827 46.50
为了更加全面地了解到各个区域的租房数量和平均租金,这里将之前创建 的 new_df对象(各地区房源数量)与 df_all 对象进行合并,通过 merge() 函数来实现。
# 合并new_df与df_all
df_merge=pd.merge(new_df,df_all)
df_merge
地区 数量 房租总金额 总面积 每平方米租金
0 上城 1618 8721856 187774 46.45
1 滨江 2405 10100330 139402 72.45
2 萧山 466 1110950 51465 21.59
3 富阳 1992 3559163 126435 28.15
4 临安 481 1241946 47447 26.18
5 钱塘新区 2324 9233878 142617 64.75
6 西湖 2224 9054939 136073 66.54
7 下城 679 2483328 30072 82.58
8 拱墅 2210 6522415 138026 47.25
9 江干 2381 8185825 134994 60.64
10 余杭 2048 6827318 146827 46.50
数据合并完成后,借用图表来展示各地区的房屋信息,房源数量可以用柱状图表示,每平方米租金可以用拆线图来表示,具体代码如下
import matplotlib.ticker as mtick
from matplotlib.font_manager import FontProperties
num=df_merge['数量']
price=df_merge['每平方米租金']
l =[i for i in range(11)]
plt.rcParams['font.sans-serif']=['SimHei']
lx=df_merge['地区']
fig=plt.figure()
ax1=fig.add_subplot(111)
ax1.plot(l,price,'or-',label='价格')
for i,(_x,_y) in enumerate(zip(l,price)):
plt.text(_x,_y,price[i],color='black',fontsize=10)
ax1.set_ylim([0,200])
ax1.set_ylabel("价格")
plt.legend(prop={'family':'SimHei','size':8},loc='upper left')
ax2=ax1.twinx()
plt.bar(l,num,alpha=0.3,color='red',label='数量')
ax2.set_ylabel('数量')
ax2.set_ylim([0,2800])
plt.legend(prop={'family':'SimHei','size':8},loc='upper right')
plt.xticks(l,lx)
plt.show()
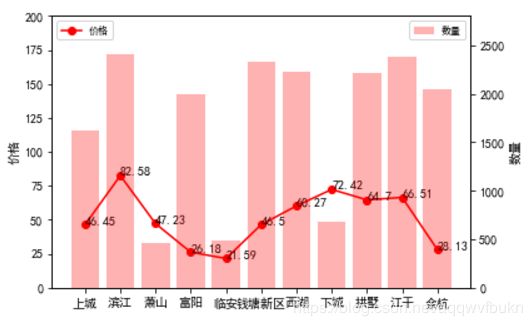
从图中可以看出,滨江区、下城区、江干区、拱墅区的房租价格相对较高,这主要是因为滨江区、拱墅区和下城区聚集了大量的新兴互联网公司,而江干区又是学区房火热的地带,这里包含了几十所高校,俗称大学城,因此这四个区域的房租相对其他区域较高。
4.4、面积区间分析
下面将房屋的面积数据按照一定的规则划分为多个区间,看看这面积 区间的占比情况,便于分析要租房市场中哪种房屋类型更好出租,哪个面积区间的租房人数最多。
首先使用max() 和 min() 方法计算出面积的最大值和最小值,
# 查看房屋的最大面积和最小面积
print("房屋最大面积是 %d 平方米"%(file_data['面积'].max()))
print("房屋最小面积是 %d 平方米"%(file_data['面积'].min()))
# 查看房租的最高价和最低价
print("房租最高价为每月 %d 元"%(file_data['价格'].max()))
print("房租最低价为每月 %d 元"%(file_data['价格'].min()))
房屋最大面积是 44185 平方米
房屋最小面积是 5 平方米
房租最高价为每月 66000 元
房租最低价为每月 500 元
使用Pandas中的 cut() 方法将房屋面积划分为5个区间,然后使用 describe() 方法显示各个区间出现的次数(counts)和频率(freqs)具体代码如下
# 面积划分
area_divide=[0,30,60,100,150]
area_cut=pd.cut(list(file_data['面积']),area_divide)
area_cut_data=area_cut.describe()
area_cut_data
counts freqs
categories
(0.0, 30.0] 5330 0.283089
(30.0, 60.0] 5373 0.285373
(60.0, 100.0] 5149 0.273476
(100.0, 150.0] 2420 0.128532
NaN 556 0.029530
接着,使用饼图来展示 各面积区间的分布情况
import numpy as np
area_percentage=(area_cut_data['freqs'].values)*100
#保留两位小数
np.set_printoptions(precision=2)
labels=['30平方米以下','30-60平方米','60-100平方米','100-150平方米','150平方米以上']
# 设置图片大小
plt.figure(figsize = (6,7))
plt.axes(aspect=1)
plt.pie(x=area_percentage,labels=labels,autopct='%.2f %%',
#shadow=True,
labeldistance=1.2,
startangle=90,
pctdistance=0.8)
#plt.legend(loc='upper right')
plt.show()

从图中可以看出,市场占有率前三的分别是30~60平方米、30平方米以下、60 ~100平方米。总体来看,租客主要以100平方米以下的房屋为租住对象,其中30 ~60平方米的房屋更受欢迎。
小结
本文章运用所学的知识,开发了一个相对比较完整的数据分析项目,旨在通过本次的学习,能够更加熟练地掌握的数据分析工具的使用,让自己所学知识有个输出。