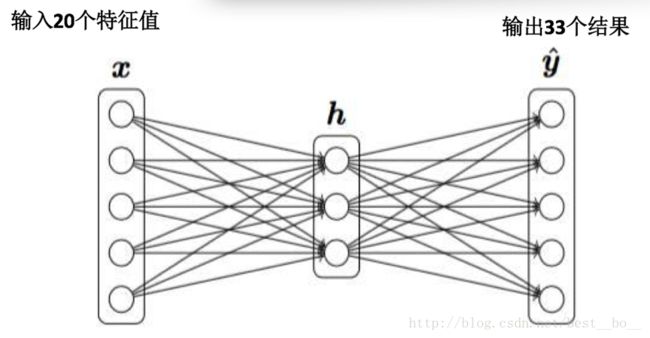
BP神经网络在车牌识别中的原理及应用
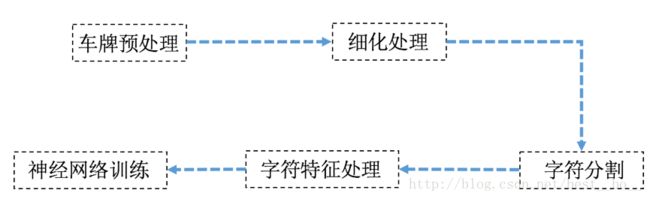
车牌识别流程图
l 图像预处理
l 为什么要进行图像预处理呢?
消除图像中无关的信息,恢复有用的真实信息,增强有关信息的可检测性和最大限度地简化数据,从而改进特征抽取、图像分割、匹配和识别的可靠性
l 为什么要进行灰度化、二值化呢
识别物体,最关键的因素是梯度,梯度意味着边缘,这是最本质的部分,而计算梯度,自然就用到灰度图像了。颜色本身,非常容易受到光照等因素的影响,同类的物体颜色有很多变化。所以颜色本身难以提供关键信息。
目标和背景分离,二值化可以简单切迅速处理图像特征。
l 灰度处理如何做?
红(R)、绿(G)、蓝(B)三个颜色通道的变化以及它们相互之间的叠加来得到各式各样的颜色的,RGB即是代表红、绿、蓝三个通道的颜色。
图片2
这里运用了加权平均法。根据重要性及其它指标,将三个分量以不同的权值进行加权平均。由于人眼对绿色的敏感最高,对蓝色敏感最低,因此,按下式对RGB三分量进行加权平均能得到较合理的灰度图像。
I = 0 .229 R+0.587 G+0.114 B
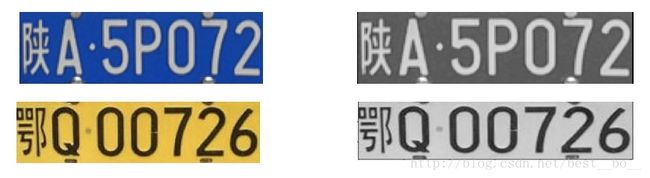
车牌灰度处理后的效果:
灰度处理源码:
import matplotlib.pyplot as plt
img=data.hubble_deep_field()
img_name="cp1.png"
img=io.imread(img_name,as_grey=False)
img_gray=color.rgb2gray(img)
plt.figure('cph')
plt.subplot(121)
plt.title('yuantu')
plt.imshow(img,plt.cm.gray)
plt.subplot(122)
plt.title('huiduhua')
plt.imshow(img_gray,plt.cm.gray)
plt.show()l 那么二值化怎么做呢?
二值化就是让图像的像素点矩阵中的每个像素点的灰度值为0(黑色)或者255(白色),也就是让整个图像呈现只有黑和白的效果。在灰度化的图像中灰度值的范围为0~255,在二值化后的图像中的灰度值范围是0或者255。
图片4
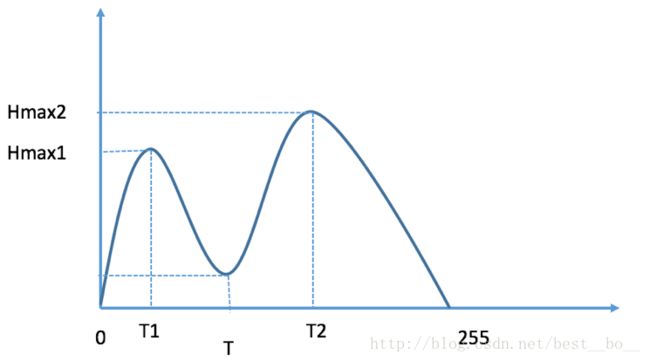
直方图中我们可以明显的看到两个山峰状的图像分布,山峰的顶点我们记为Hmax1和Hmax2,他们对应的灰度值分别为T1和T2,那么双峰法图像分割的思想就是找到图像两个山峰之间的谷地最低值,即在[T1,T2]的灰度范围内寻找阈值T,使其满足对应的像素数目最少,表现在图像上就是高度最低,用T对图像进行分割或二值化。
图片5

二值化处理:
from skimage import io,data,color
import matplotlib.pyplot as plt
img_name = "cphd2.png"
img = io.imread(img_name, as_grey=False)
img_gray=color.rgb2gray(img)
rows,cols=img_gray.shape
for i in range(rows):
for j in range(cols):
if (img_gray[i,j]<=0.5):
img_gray[i,j]=0
else:
img_gray[i,j]=1
plt.figure('cph')
plt.subplot(121)
plt.title('yuantu')
plt.imshow(img,plt.cm.gray)
plt.subplot(122)
plt.title('erzhihua')
plt.imshow(img_gray,plt.cm.gray)
plt.show()l 细化处理
为什么要进行细化处理呢?
对图像的喜欢过程实际是求图像骨架的过程。骨架是二维二值目标的重要描述,它指图像中央的骨骼部分,是描述图像几何及拓扑性质的重要特征之一。
用骨架来表示线划图像能够有效地减少数据量,减少图像的存储难度和识别难度。
细化是将图像的线条从多像素宽度减少到单位像素宽度过程的简称。
如何去细化处理呢?
判断一个点是否能去掉是以8个相邻点(八连通)的情况来作为判据的,具体判据为:
1,内部点不能删除
2,鼓励点不能删除
3,直线端点不能删除
4,如果P是边界点,去掉P后,如果连通分量不增加,则P可删除

第一个点不能去除,因为它是内部点
第二个点不能去除,它也是内部点
第三个点不能去除,删除后会使原来相连的部分断开
第四个点可以去除,这个点不是骨架
第五个点不可以去除,它是直线的端点
第六个点不可以去除,它是直线的端点
在这里举一个例子:horse
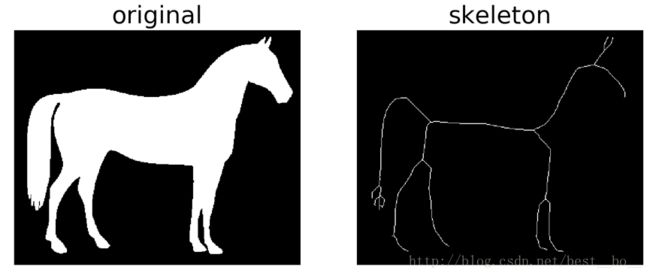
# coding=utf-8
# !/usr/bin/env python
from skimage import morphology,data,color
import matplotlib.pyplot as plt
image=color.rgb2gray(data.horse())
image=1-image #反相
skeleton =morphology.skeletonize(image)
#显示结果
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(8, 4))
ax1.imshow(image, cmap=plt.cm.gray)
ax1.axis('off')
ax1.set_title('original', fontsize=20)
ax2.imshow(skeleton, cmap=plt.cm.gray)
ax2.axis('off')
ax2.set_title('skeleton', fontsize=20)
fig.tight_layout()
plt.show()车牌进行细化处理的效果:
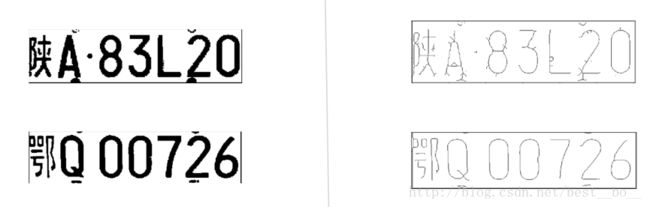
细化处理源码:
from skimage import io,data,color,morphology
import matplotlib.pyplot as plt
img_name = "cphd2.png"
img = io.imread(img_name, as_grey=False)
img_gray=color.rgb2gray(img)
rows,cols=img_gray.shape
for i in range(rows):
for j in range(cols):
if (img_gray[i,j]<=0.5):
img_gray[i,j]=0
else:
img_gray[i,j]=1
skeleton =morphology.skeletonize(1-img_gray)
plt.imshow(1-skeleton, cmap=plt.cm.gray)
plt.show()
l 字符分割
在车牌进行细化处理以后进行的下一步是字符分割
l 为什么要进行字符分割呢
由于车牌图像做了细化处理后,整个图形识别起来比较麻烦,所以需要将图像分割开来,对每个字符进行单独识别。
l 如何进行字符分割呢?
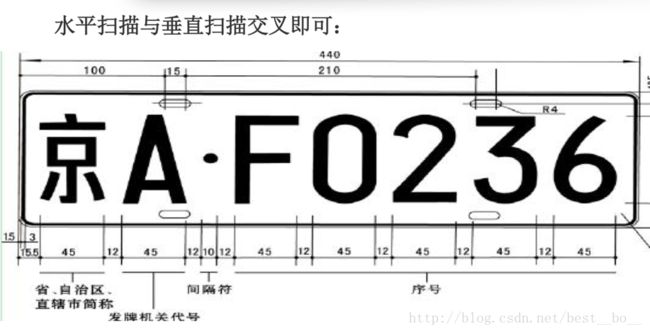
根据车牌的特征,先将车牌图像进行水平扫描跳跃点,即水平相邻的两个像素,如果不相同则认为有一个跳跃点,记录次数加1,由于车牌上面有时候会有两个白点,所以通过判断跳跃点的个数,可以将上面的两个白点去掉。

统计结果:4 4 4 0 0 14 14 16 20 24 24 24 24 22 20 24 26 28 28 30 26 26 24 2020 22 22 22 26 20 20 22 24 20 20 20 20 2 0 4 4 6 4。扫描结果数量个数为的车牌高度的个数。扫描结果数量个数为从上往下查找,根据实验结果,设置当水平跳跃点超过10个的时候,作为车牌字符截取的上限。当从下往上查找,当跳跃点超过8个的时候可以作为车牌字符截取的下限。通过上面的过程,基本可以确定车牌的上部和下部。
同样,分割车牌字符左右边界时,通过垂直扫描过程,由于数字和字母具有连通性,所以分割数字和字母比较容易。通过垂直扫描过程,统计黑色像素点的个数,由于两个字符之间没有黑像素,所以可以作为字符分割的界限。

这样看起来更加直观:
l 特征提取
一般特征提取过程都是自动提取,为了能更好的体会这个过程我做了如何手动提取:
(1)笔画斜率累积特征提取
笔画是字符的一个非常具有代表性的特征,不同字符在笔画数量,笔画长短,笔画形态上是不同的。
这种方法可以较好 地表显出特征字符的骨架笔画形态和笔画长短的特性。
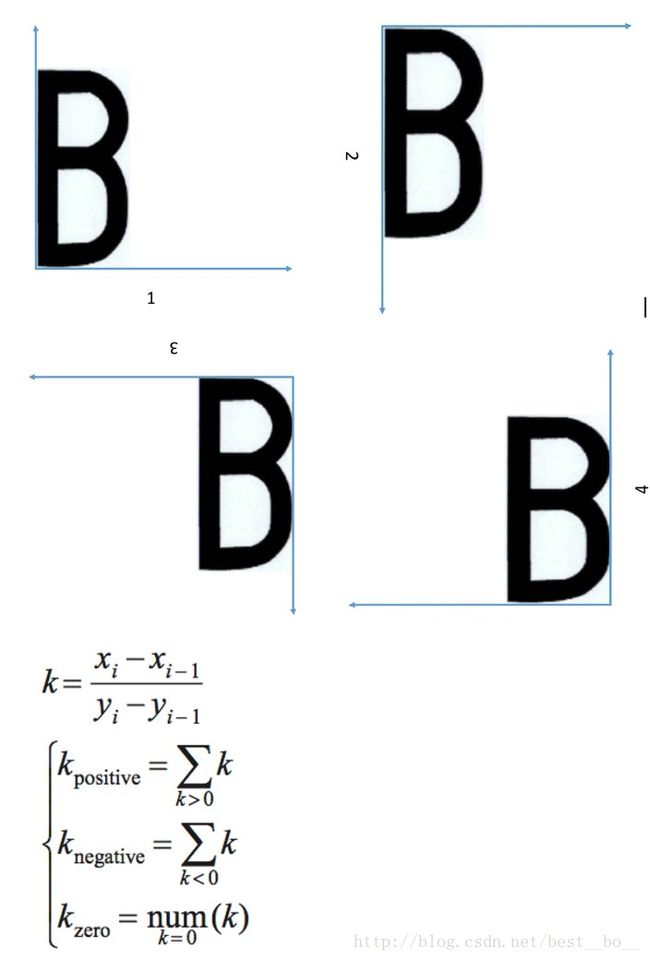
首先定义笔画斜率特征统计点,当且仅当当前扫描点为像素点并且前一扫描行检测到像素点,则当前扫描点为斜率特征统计点,见上图。假设当前扫描点pi(xiyi) 为斜率统计点,前一扫描行检测到的像素点是pi-1(xi-1yi-1),那么点pi的斜率k 计算由式(1)得到。正负斜率累积值或零斜率点数量满足式。分别提取了字符4个侧面的笔画斜率累积特征,可以获得了12 个特征向量。
(2)拐点幅度累积特征提取
在字符识别中,字符拐点含有非常丰富的特征信息,拐点的数量和位置与字符结构形状有着紧密的联系。为了弥补上述笔画斜率累积特征无法全面地表征字符骨骼的结构信息的不足,引入了拐点幅度累积特征提取。
为什么不计算拐点的个数呢?
拐点的定义:假设当前斜率统计点 pi(xiyi) 和前一斜率统计点pi对 应的斜率ki和ki - 1 数值符号不同时,则定义pi为一个拐点。因为数字字母之间拐点个数大部分都相同。作为拐点k值很大,不是拐点则k值越小。
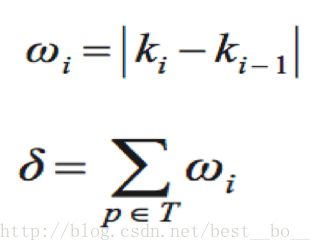
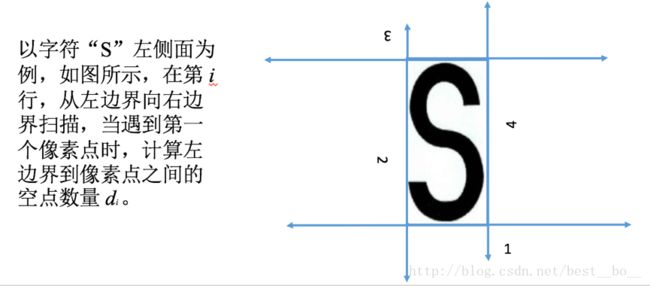
(3)侧面轮廓深度特征提取
不同字符在轮廓上存在明显的差异,如字符“S”和“C”,字符“ S ”在左 右 侧 面 具 有 明 显 的 凹 特 征 ,顶 部 和 底 部 都 比 较 平 缓;而字符“C”的顶部有明显的凹特征。
l 神经网络训练
处理后的车牌都可以用1和0来表示,识别的算法有很多,包括分类器算法,模板匹配算法,基于概率统计的Bayes分类器算法,聚类分析算法等。
用神经网络训练,将提取的特征值,输入层为20个特征,隐含层为80个特征,输出层为34个特征。这里去除字母“I”和“O”。字符0-9,24个字母一共34个输出。说明:由于有34个输出,所以这里理想情况下输出结果为33个0和一个1.只是1在第i个输出。i对应的数字编号如0则对应0,1对应1,9对应9,字符“A”对应10,字符“B”对应11,依次类推,字符“Z”对应33。