pandas学习——第四次任务——变形
Task04:变形 理论部分
- 熟悉3个透视函数的区别与用法
- 理解stack和unstack状态
- 掌握变形函数的各类使用场合
- 了解哑变量和因子化的用法
练习部分
- 非法药物数据集的变形操作
- 某国地震数据集的变形操作
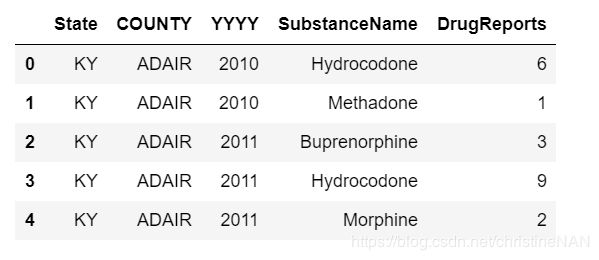
df = pd.read_csv('data/Drugs.csv',index_col=['State','COUNTY']).sort_index()
df.head()
【练习一】 继续使用上一章的药物数据集
- (a) 现在请你将数据表转化成如下形态,每行需要显示每种药物在每个地区的10年至17年的变化情况,且前三列需要排序:
df = pd.read_csv('data/Drugs.csv',index_col=['State','COUNTY']).sort_index()
df.head()

result = pd.pivot_table(df,index=['State','COUNTY','SubstanceName']
,columns='YYYY'
,values='DrugReports',fill_value='-').reset_index().rename_axis(columns={'YYYY':''})
result.head()

- (b) 现在请将(a)中的结果恢复到原数据表,并通过equal函数检验初始表与新的结果是否一致(返回True)
result_melted = result.melt(id_vars=result.columns[:3],value_vars=result.columns[-8:]
,var_name='YYYY',value_name='DrugReports').query('DrugReports != "-"')
result2 = result_melted.sort_values(by=['State','COUNTY','YYYY'
,'SubstanceName']).reset_index().drop(columns='index')
#下面其实无关紧要,只是交换两个列再改一下类型(因为‘-’所以type变成object了)
cols = list(result2.columns)
a, b = cols.index('SubstanceName'), cols.index('YYYY')
cols[b], cols[a] = cols[a], cols[b]
result2 = result2[cols].astype({'DrugReports':'int','YYYY':'int'})
result2.head()

df_tidy = df.reset_index().sort_values(by=result2.columns[:4].tolist()).reset_index().drop(columns='index')
df_tidy.head()
df_tidy.equals(result2)
![]()
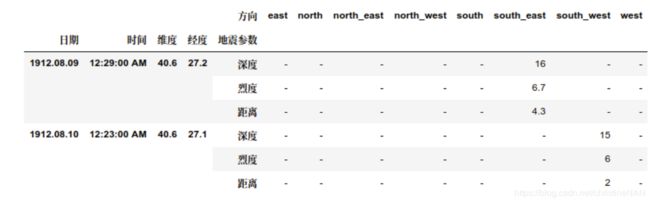
【练习二】 现有一份关于某地区地震情况的数据集,请解决如下问题:

- (a) 现在请你将数据表转化成如下形态,将方向列展开,并将距离、深度和烈度三个属性压缩:
df = pd.read_csv('data/Earthquake.csv')
df = df.sort_values(by=df.columns.tolist()[:3]).sort_index(axis=1).reset_index().drop(columns='index')
df.head()
result = pd.pivot_table(df,index=['日期','时间','维度','经度']
,columns='方向'
,values=['烈度','深度','距离'],fill_value='-').stack(level=0).rename_axis(index={None:'地震参数'})
result.head(6)
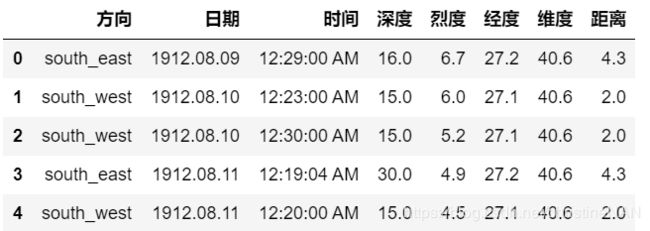

- (b) 现在请将(a)中的结果恢复到原数据表,并通过equal函数检验初始表与新的结果是否一致(返回True)
df_result = result.unstack().stack(0)[(~(result.unstack().stack(0)=='-')).any(1)].reset_index()
df_result.columns.name=None
df_result = df_result.sort_index(axis=1).astype({'深度':'float64','烈度':'float64','距离':'float64'})
df_result.head()

df_result.astype({'深度':'float64','烈度':'float64','距离':'float64'},copy=False).dtypes
df.equals(df_result)

![]()