前言
既然读书,就把它读薄。
在学习C语言的时候我读到过一句话,说C语言并不是个复杂的语言,因此介绍C语言的书没必要太长。我觉得很合心意,然后就喜欢上这个语言——谁会不喜欢简洁的设计呢?
但并非所有的设计都能做到这样,比如操作系统,它本身就是个庞大复杂的家伙,是许多人协作劳动的成果,充满了繁多的细节。幸运的是有一种人有提炼总结的特异功能,能像炼金术士一样把知识归纳总结重新浓缩提炼,再次呈现出来的时候不失原味又井井有条,所有的学习者都因为他们的智慧受益。W. Richard Stevens就是这样的炼金术士,他的《Advanced Programming in the Unix Environment》和《UNIX Network Programming》都是了不起的创造和作品。我崇拜这样的人。
可即便如此,《Advanced Programming in the Unix Environment》也有1000多页,这是因为本质上手册类的书籍需要面面俱到,容纳各种细节和特例。但作为学习者的普通人类显然是无法将所有知识都记忆的,当然也没有必要。好的学习者阅读一本书的过程应该是自己构建起知识索引,能够快速的定位、查阅并应用,所谓消化知识就是这个意思。
这里的把书读薄系列就是我阅读过程中试图建立的大脑索引,它抽取了一部书(或一个领域)中最重要的方面,将每一个方面通过一幅图或者文字脉络将重要的知识串起来,而舍弃掉细节和特例。当然既然你已经构建起了知识的全景,你自然知道去哪里找到这些细节和特例。
总而言之,这是个人的读书笔记。只不过我努力将它写的对阅读者友好,而不论阅读者是别人还是自己——就像程序注释那样。
提纲
简单说来,Unix环境给程序员提供的就是一系列的系统调用(System Call)和C库函数(C Library Function),程序员通过在程序中调用这两者来使用操作系统的服务。因此本质上学习《Advanced Programming in the Unix Environment》就是学习这些系统调用和C库函数。但如果认为《Advanced Programming in the Unix Environment》仅仅是一本接口手册,就有点儿买椟还珠了。这本书的经典之处在于它不仅把这些接口函数的讲解分门别类,还描绘了接口背后Unix系统的相关设计和原理,再辅以丰富的实例代码来展示怎样使用这些接口,与一般的手册可谓是云泥之别。
我认为Unix环境编程的知识最重要的就5个方面,这5个方面占了Unix环境编程知识中的80%以上,掌握之后基本认为对Unix系统胸有成竹了。它们是:
- 文件系统 (File System)
- 权限控制 (Permission Control)
- I/O (包括Unbuffered I/O 和 Buffered I/O)
- 进程和线程 (Process & Thread,包括进程控制,线程控制,进程间通信)
- 内存分配和管理 (Memory Allocation and Management)
除去上面5个方面,剩下的内容不多,可以很快扫尾,我统称为“其他”:
- 信号 (Signal)
- 时间 (Time)
- 错误处理 (Error Handle)
第1部分 : I/O
I/O 分为Unbuffered I/O和Buffered I/O两种。
Unbuffered I/O,即无缓存I/O,是通过一系列的系统调用提供的。这里的无缓存是相对于C标准库的I/O函数而言,文件的读写都是直接用的系统调用。而C库函数提供的I/O操作则是在系统调用之上又作了一层封装,加入了缓存逻辑,故称为Buffered I/O。
Unbuffered I/O
Unbuffered I/O的接口设计非常简洁容易理解,一共就7+3个系统调用。
- 7个基本I/O操作包括:open,close,lseek,分别用于打开文件,关闭文件,重定位文件读写偏移。还有2对读写函数,read和pread,write和pwrite。pread和pwrite是原子操作版的读写函数。
- 3个其他I/O操作是dup,sync,和fcntl。
而这7+3个系统调用都紧密的围绕在Unix系统维护的进程空间和内核空间的逻辑结构之上,可以用一幅图全部串联起来。
Fig 1.1 文件打开后进程空间和内核空间的逻辑结构
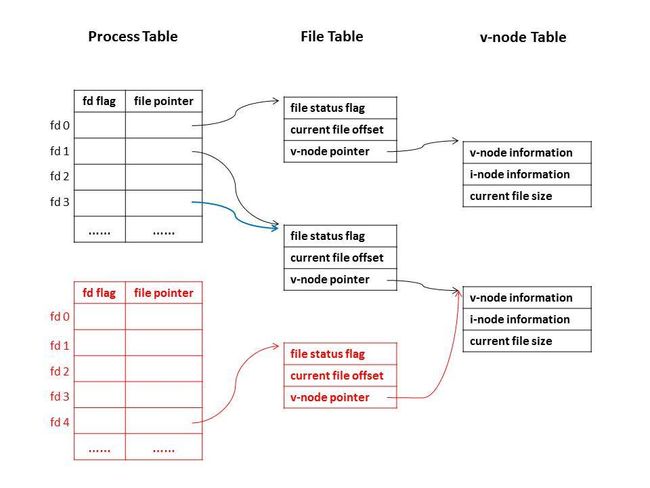
如Fig 1.1所示,Unbuffered I/O的系统调用背后,进程空间和内核空间维护着这样一幅逻辑结构——由Preocess Table(进程表),File Table(文件表),v-node Table(v节点表)三个数据结构组成。
我们先看图中的黑色部分:
假设进程a.out是通过shell命令a.out 启动得,相当于shell帮进程a.out在文件描述符0(标准输入)位置以打开了input.txt,在文件描述符1的位置打开了文件output.txt。那么此时
- 如图左侧所示,进程a.out在Process Table中拥有自己的条目,记录着它当前打开的所有文件描述符的相关信息——即它在文件描述符号0的位置打开了某个文件作为标准输入,在文件描述符1的位置打开了某文件作为标准输出。但具体文件打开的方式是什么,文件存在磁盘的什么位置,则要顺着Process Table中的file pointer字段去到File Table。
- 如图中部所示,File Table记录的是 (1)file status flag记录着文件的打开方式——比如input.txt就是以只读方式打开的,相应的file status flag字段即为O_RDONLY。output的file status flag字段应为(O_WRONLY | O_APPEND | O_CREAT) (2)当前文件偏移量current file offset,对于该文件的读写操作都会在current file offset指示的位置进行 (3)如果要得到具体文件的一些信息,比如文件的拥有者是谁,文件存储在磁盘的什么位置,则要顺着File Table中的v-node指针找到v-node Table
- 如图右侧所示,v-node Table记录着文件类型,文件的拥有者,文件大小,文件内容存储的磁盘block地址等信息。
值得注意的是,同一时刻无论有多少个进程打开了同一个文件,v-node Table都只有一个表项。而File Table则不同,若某个进程多次打开同一文件,或者多个进程打开了同一文件,则File Table中会有多项。这非常好理解,因为每次打开的方式,还有偏移量可能不同。比如如图Fig 1.1红色部分所示,此时有另外一个进程也打开了output.txt(在文件描述符4的位置),则该进程会在File Table中有单独的一个表项记录该进程的文件打开方式和偏移量,但v-node指针指向的v-node表项与a.out进程指向的是同一个。
int open(const char *pathname, int oflag, ... /* mode_t mode */ );
open函数是Unbuffered I/O的第一步,它以指定的方式打开指定文件,成功打开之后返回相应的文件描述符,其他I/O操作都需要这个文件描述符来指定当前是对哪个文件作操作。open打开文件前会作相应的权限检查,然后在当前未被使用的最小的文件描述符处打开文件并返回该描述符。
int close(int filedes);
close函数关闭某文件描述符。若某进程没有显式关闭它所打开的文件,则当进程结束时它所打开的所有文件都会被自动被关闭。
off_t lseek(int filedes, off_t offset, int whence);
lseek函数重定位File Table的current file offset字段——read或write会在current file offset处进行。
ssize_t read(int filedes, void *buf, size_t nbytes);
ssize_t pread(int filedes, void *buf, size_t nbytes, off_t offset);
read函数从一个打开的文件的current file offset位置读取数据。成功读取nbyte的数据后current file offset会加上nbyte。
pread是多个进程共享某文件时应该采用的读函数,它的作用时每次lseek到指定位置然后read文件,且这两个操作是不可中断的原子操作(atomic operation)。
ssize_t write(int filedes, const void *buf, size_t nbytes);
ssize_t pwrite(int filedes, const void *buf, size_t nbytes, off_t offset);
write函数从一个打开的文件的current file offset位置写入数据,除非文件是以O_APPEND方式打开的,则每次写前都会重置current file offset到文件尾。成功写入nbyte后current file offset也会加上nbyte。
pwrite函数是多个进程共享某文件时应该采用的写函数,它的作用时每次lseek到指定位置然后write文件,且这两个操作是不可中断的原子操作(atomic operation)。
int dup(int filedes);
int dup2(int filedes, int filedes2);
dup, dup2函数的作用是复制文件描述符。
dup函数会自动在当前最小的空闲描述符处复制描述符号filedes。比如a.out的程序中若有语句dup(1);,而当前没有被使用的描述符最小的是3(这里假定文件描述符2已被标准错误占用),那么就会在文件描述符3的位置复制文件描述符1,结果就会如图Fig 1.1的蓝线所示,文件描述符1和3都指向同一个File Table表项。
dup2则是可以指定在文件描述符filedes2处复制文件描述符filedes,如果filedes2已经被打开了,则dup2会先关闭它然后进行复制。(dup2函数可以用于输入输出重定向,比如某个进程在描述符3的位置打开了一个文件,然后调用dup2(3, STDOUT_FILENO),就相当于将标准输出重定向到了该文件)
void sync(void);
int fsync(int filedes);
int fdatasync(int filedes);
sync函数:Unix系统中,当对文件进行写操作时采用了“延迟写”策略,即等够一定的时间或者积攒一定数量的写操作之后再真正将数据写到磁盘上,这样可以减少磁盘I/O次数。调用sync函数相当于告诉操作系统立即将“延迟写”的数据写到磁盘。但它不等待磁盘写操作完成即返。fsync函数与sync函数类似,只不过是对某个对特定的文件操作并会等待真正的磁盘写操作完成才返回。fdatasy与fsync类似,但不像fsync函数那样写的时候也同时更新文件的属性。
int fcntl(int filedes, int cmd, ... /* int arg */ );
fcntl函数是一个多功能的函数,可以用来包括复制文件描述符,获取或修改Process Table中的fd flags,获取或修改File Table中的file status flags等,一共9种功能通过参数来控制。
(如果你觉得这篇文章有帮助,敬请期待Buffered I/O部分)