0x01 简陋代码是,获取(.*?)的字符串
#coding:utf-8
from requests import *
import re
headers = { "accept":"text/html,application/xhtml+xml,application/xml;",
"accept-encoding":"gzip",
"accept-language":"zh-cn,zh;q=0.8",
"referer":"Mozilla/5.0(compatible;Baiduspider/2.0;+http://www.baidu.com/search/spider.html)",
"connection":"keep-alive",
"user-agent":"mozilla/5.0(windows NT 6.1;wow64) applewebkit/537.36 (khtml,like gecko)chrome/42.0.2311.90 safari/537.36"
}
url="https://www.xicidaili.com/wn/"
html=get(url,timeout=3,headers=headers).text
iplist = re.findall('(.*?) ',html)
print(iplist)
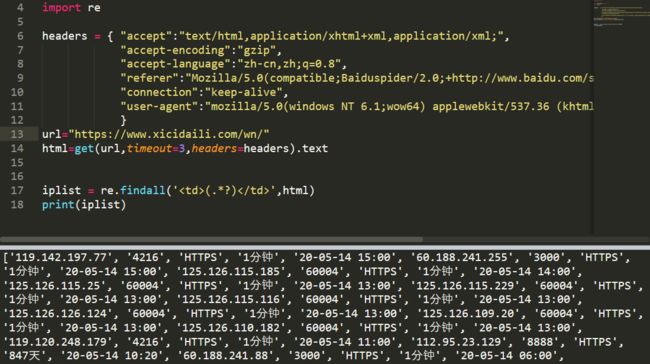
0x02 只爬取IP与端口,findall带两个(.*?),则两个为一组
#coding:utf-8
from requests import *
import re
headers = { "accept":"text/html,application/xhtml+xml,application/xml;",
"accept-encoding":"gzip",
"accept-language":"zh-cn,zh;q=0.8",
"referer":"Mozilla/5.0(compatible;Baiduspider/2.0;+http://www.baidu.com/search/spider.html)",
"connection":"keep-alive",
"user-agent":"mozilla/5.0(windows NT 6.1;wow64) applewebkit/537.36 (khtml,like gecko)chrome/42.0.2311.90 safari/537.36"
}
url="https://www.xicidaili.com/wn/"
html=get(url,timeout=3,headers=headers).text
pattern = re.compile('.*?.*?(.*?) .*?(.*?) .*? ', re.S)
iplist = re.findall(pattern,html)
print(iplist)

这样就简单多了,直接for循环把每个元组提取出来,且元组支持切片,[0]获取每个ip,[1]获取每个端口
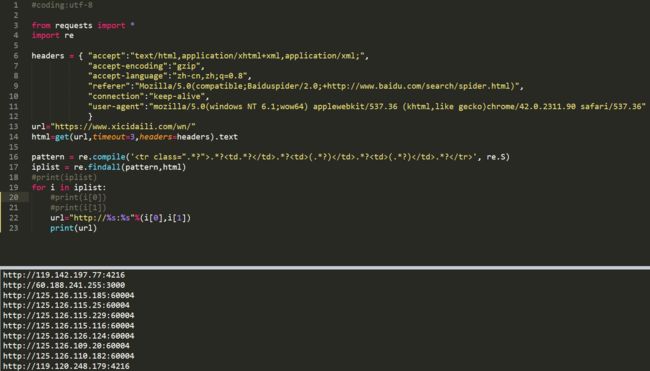
0x03 最终输出格式如下
#coding:utf-8
from requests import *
import re
headers = { "accept":"text/html,application/xhtml+xml,application/xml;",
"accept-encoding":"gzip",
"accept-language":"zh-cn,zh;q=0.8",
"referer":"Mozilla/5.0(compatible;Baiduspider/2.0;+http://www.baidu.com/search/spider.html)",
"connection":"keep-alive",
"user-agent":"mozilla/5.0(windows NT 6.1;wow64) applewebkit/537.36 (khtml,like gecko)chrome/42.0.2311.90 safari/537.36"
}
url="https://www.xicidaili.com/wn/"
html=get(url,timeout=3,headers=headers).text
pattern = re.compile('.*?.*?(.*?) .*?(.*?) .*? ', re.S)
iplist = re.findall(pattern,html)
#print(iplist)
for i in iplist:
#print(i[0])
#print(i[1])
url="http://%s:%s"%(i[0],i[1])
print(url)