【Flink】Flink对于迟到数据的处理
代码地址:https://github.com/18113996630/flink-practice/blob/master/src/main/scala/com/hrong/flink/watermark/WaterMarkFunc02.scala
视频讲解:flink迟到数据处理视频讲解
waterMark和Window机制解决了流式数据的乱序问题,对于因为延迟而顺序有误的数据,可以根据eventTime进行业务处理,详情见上一篇博客:Flink的事件时间及watermark水印讲解-附代码实例
对于延迟的数据Flink也有自己的解决办法,主要的办法是给定一个允许延迟的时间,在该时间范围内仍可以接受处理延迟数据
设置允许延迟的时间是通过allowedLateness(lateness: Time)设置
保存延迟数据则是通过sideOutputLateData(outputTag: OutputTag[T])保存
获取延迟数据是通过DataStream.getSideOutput(tag: OutputTag[X])获取
下面先分别讲解这几个方法,再给出具体的实例加深理解
1、allowedLateness(lateness: Time)
def allowedLateness(lateness: Time): WindowedStream[T, K, W] = {
javaStream.allowedLateness(lateness)
this
}该方法传入一个Time值,设置允许数据迟到的时间,这个时间和waterMark中的时间概念不同。再来回顾一下,
waterMark=数据的事件时间-允许乱序时间值
随着新数据的到来,waterMark的值会更新为最新数据事件时间-允许乱序时间值,但是如果这时候来了一条历史数据,waterMark值则不会更新。总的来说,waterMark是为了能接收到尽可能多的乱序数据。
那这里的Time值呢?主要是为了等待迟到的数据,在一定时间范围内,如果属于该窗口的数据到来,仍会进行计算,后面会对计算方式仔细说明
注意:该方法只针对于基于event-time的窗口,如果是基于processing-time,并且指定了非零的time值则会抛出异常
2、sideOutputLateData(outputTag: OutputTag[T])
def sideOutputLateData(outputTag: OutputTag[T]): WindowedStream[T, K, W] = {
javaStream.sideOutputLateData(outputTag)
this
}该方法是将迟来的数据保存至给定的outputTag参数,而OutputTag则是用来标记延迟数据的一个对象。
3、DataStream.getSideOutput(tag: OutputTag[X])
通过window等操作返回的DataStream调用该方法,传入标记延迟数据的对象来获取延迟的数据
4、对延迟数据的理解
延迟数据是指:
在当前窗口【假设窗口范围为10-15】已经计算之后,又来了一个属于该窗口的数据【假设事件时间为13】,这时候仍会触发window操作,这种数据就称为延迟数据。
那么问题来了,延迟时间怎么计算呢?
假设窗口范围为10-15,延迟时间为2s,则只要waterMark<15+2,并且属于该窗口,就能触发window操作。而如果来了一条数据使得waterMark>=15+2,10-15这个窗口就不能再触发window操作,即使新来的数据的event-time<15+2+3
5、代码实例讲解
大概讲解一下代码的流程:
1、监听某主机的9000端口,读取socket数据(格式为 name:timestamp)
2、给当前进入flink程序的数据加上waterMark,值为eventTime-3s
3、根据name值进行分组,根据窗口大小为5s划分窗口,设置允许迟到时间为2s,依次统计窗口中各name值的数据
4、输出统计结果以及迟到数据
5、启动Job
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.scala.{DataStream, OutputTag, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import scala.collection.mutable.ArrayBuffer
/**
* 延迟测试
* 详细讲解博客地址:https://blog.csdn.net/hlp4207/article/details/90717905
*/
object WaterMarkFunc02 {
// 线程安全的时间格式化对象
val sdf: FastDateFormat = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss:SSS")
def main(args: Array[String]): Unit = {
val hostName = "s102"
val port = 9000
val delimiter = '\n'
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 将EventTime设置为流数据时间类型
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val streams: DataStream[String] = env.socketTextStream(hostName, port, delimiter)
import org.apache.flink.api.scala._
val data = streams.map(data => {
// 输入数据格式:name:时间戳
// flink:1559223685000
try {
val items = data.split(":")
(items(0), items(1).toLong)
} catch {
case _: Exception => println("输入数据不符合格式:" + data)
("0", 0L)
}
}).filter(data => !data._1.equals("0") && data._2 != 0L)
//为数据流中的元素分配时间戳,并定期创建水印以监控事件时间进度
val waterStream: DataStream[(String, Long)] = data.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(String, Long)] {
// 事件时间
var currentMaxTimestamp = 0L
val maxOutOfOrderness = 3000L
var lastEmittedWatermark: Long = Long.MinValue
// Returns the current watermark
override def getCurrentWatermark: Watermark = {
// 允许延迟三秒
val potentialWM = currentMaxTimestamp - maxOutOfOrderness
// 保证水印能依次递增
if (potentialWM >= lastEmittedWatermark) {
lastEmittedWatermark = potentialWM
}
new Watermark(lastEmittedWatermark)
}
// Assigns a timestamp to an element, in milliseconds since the Epoch
override def extractTimestamp(element: (String, Long), previousElementTimestamp: Long): Long = {
// 将元素的时间字段值作为该数据的timestamp
val time = element._2
if (time > currentMaxTimestamp) {
currentMaxTimestamp = time
}
val outData = String.format("key: %s EventTime: %s waterMark: %s",
element._1,
sdf.format(time),
sdf.format(getCurrentWatermark.getTimestamp))
println(outData)
time
}
})
val lateData = new OutputTag[(String,Long)]("late")
val result: DataStream[String] = waterStream.keyBy(0)// 根据name值进行分组
.window(TumblingEventTimeWindows.of(Time.seconds(5L)))// 5s跨度的基于事件时间的翻滚窗口
/**
* 对于此窗口而言,允许2秒的迟到数据,即第一次触发是在watermark > end-of-window时
* 第二次(或多次)触发的条件是watermark < end-of-window + allowedLateness时间内,这个窗口有late数据到达
*/
.allowedLateness(Time.seconds(2L))
.sideOutputLateData(lateData)
.apply(new WindowFunction[(String, Long), String, Tuple, TimeWindow] {
override def apply(key: Tuple, window: TimeWindow, input: Iterable[(String, Long)], out: Collector[String]): Unit = {
val timeArr = ArrayBuffer[String]()
val iterator = input.iterator
while (iterator.hasNext) {
val tup2 = iterator.next()
timeArr.append(sdf.format(tup2._2))
}
val outData = String.format("key: %s data: %s startTime: %s endTime: %s",
key.toString,
timeArr.mkString("-"),
sdf.format(window.getStart),
sdf.format(window.getEnd))
out.collect(outData)
}
})
result.print("window计算结果:")
val late = result.getSideOutput(lateData)
late.print("迟到的数据:")
env.execute(this.getClass.getName)
}
}接下来开始输入数据进行测试验证:

 可以看到window范围为【15-20】,这时候我们再输入几条属于该范围的数据:
可以看到window范围为【15-20】,这时候我们再输入几条属于该范围的数据:
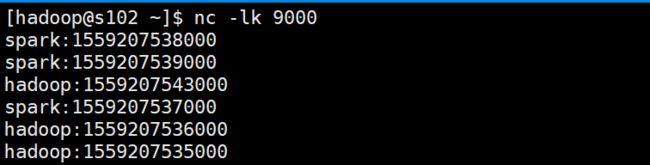
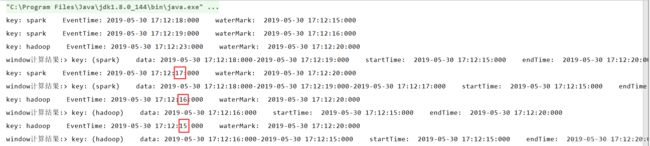
输入了事件时间为17、16、15三条数据,都触发了window操作,那我们试着输入一下窗口范围为【10-15】的数据:
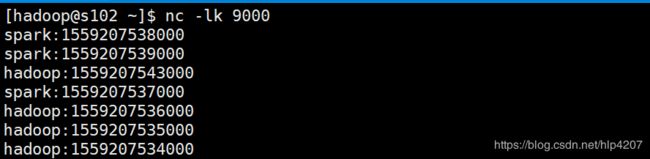

窗口范围为【10-15】的数据则属于迟到的数据,已经超过了最大等待时间,我们可以来试着计算一下允许上个窗口迟到数据的waterMark值
窗口结束时间+延迟时间=最大waterMark值
15 + 2 = 17
当前的waterMark值为20,大于17,所以窗口范围为10-15的数据已经是迟到的数据了
再来计算一下窗口时间范围为15-20的临界值:
20 + 2 = 22
即当waterMark上涨到22,15-20窗口范围内的数据就属于迟到数据,不能再参与计算了
记住我们算出的临界值22,继续输入数据测试:
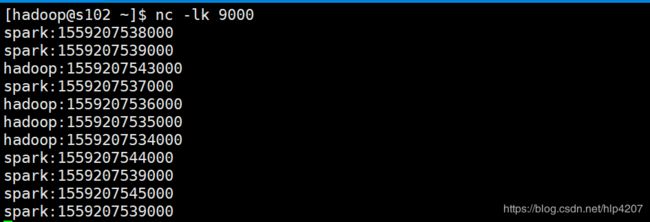
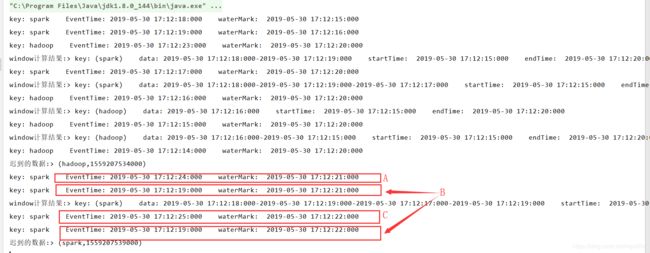
输入数据A时,waterMark上涨至21,此时输入属于15-20窗口范围内的数据B,依然能触发窗口操作;
输入数据C,waterMark上涨至22,等于刚才我们算出来的临界值,此时输入,数据B,则已不能触发窗口操作,属于迟到的数据。
最后,总结一下flink对于延迟数据的处理:
如果延迟的数据有业务需要,则设置好允许延迟的时间,每个窗口都有属于自己的最大等待延迟数据的时间限制:
窗口结束时间+延迟时间=最大waterMark值
即当waterMark值大于的上述计算出的最大waterMark值,该窗口内的数据就属于迟到的数据,无法参与window计算
代码地址:https://github.com/18113996630/flink-practice/blob/master/src/main/scala/com/hrong/flink/watermark/WaterMarkFunc02.scala
视频讲解:flink迟到数据处理视频讲解