Spring Cloud简介,为什么需要Spring Cloud?
一、为什么需要Spring Cloud?
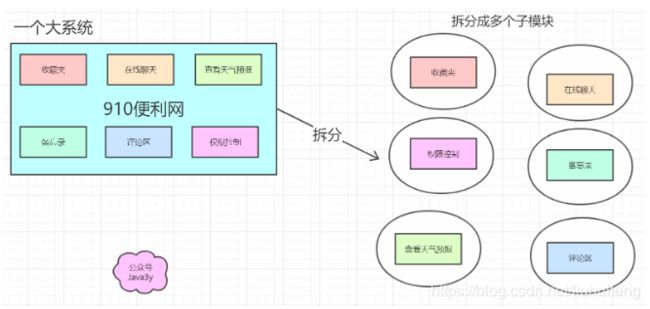
从分布式/微服务的角度而言,就是把我们一个大的项目分解成多个小的模块,这些小的模块组合起来,完成功能;而拆分出多个模块以后,就会出现各种各样的问题,而Spring Cloud提供了一整套的解决方案。
Spring cloud是一个基于Spring boot实现的云原生应用开发工具,它为基于JVM的云原生应用开发中涉及的配置管理、服务发现、熔断器、智能路由、微代理、控制总线、分布式会话和集群状态管理等操作提供了一种简单的开发方式。
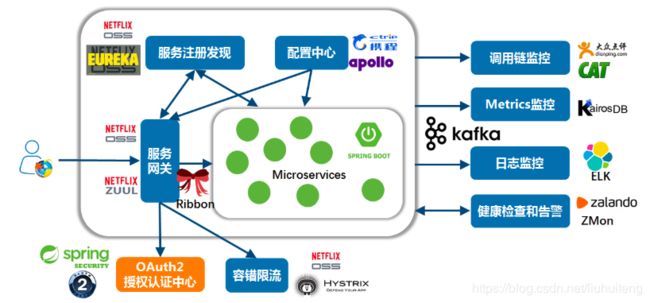
Spring Cloud的基础功能(核心组件):
(1)、服务治理:Spring cloud Eureka
(2)、客户端负载均衡:Spring cloud Ribbon
(3)、服务容错保护:SPring cloud Hystrix
(4)、声明式服务调用:Spring cloud Feign
(5)、API网关服务:Spring cloud Zuul
(6)、分布式配置中心:Spring cloud Config
(7)、消息总线:Spring cloud Bus
(8)、消息驱动的微服务:Spring cloud Stream
(9)、分布式服务跟踪:Spring cloud Sleuth
二、服务治理、注册与发现:Eureka
2.1、为什么需要服务治理:Eureka
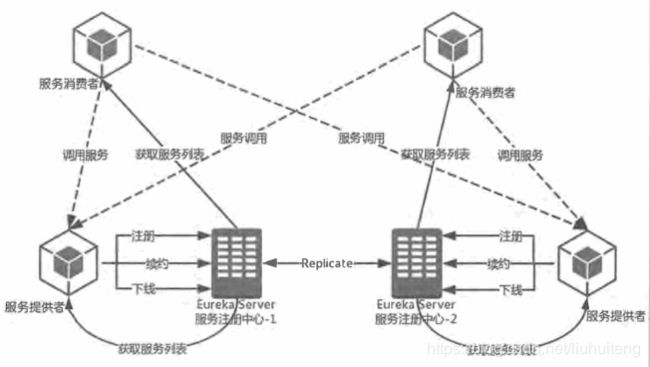
在服务众多的情况下,手动维护各服务的静态配置简直就是一个噩梦;为了解决微服务架构中的服务实例问题(IP地址),产生了 大量的服务治理框架和产品;这些框架和产品的实现都围绕着服务注册与服务发现机制来完成对微服务应用实例的自动化管理;而在Spring cloud中我们的服务治理框架一般使用的就是Eurake。
现在有A、B、C、D四个服务,它们之间会互相调用(而且IP地址很可能会发生变化),一旦某个服务的IP地址变了,那服务中的代码要跟着变,手动维护这些静态配置(IP)非常麻烦!
Eureka是这样解决:
创建一个E服务,将A、B、C、D四个服务的信息都注册到E服务上,E服务维护这些已经注册进来的信息
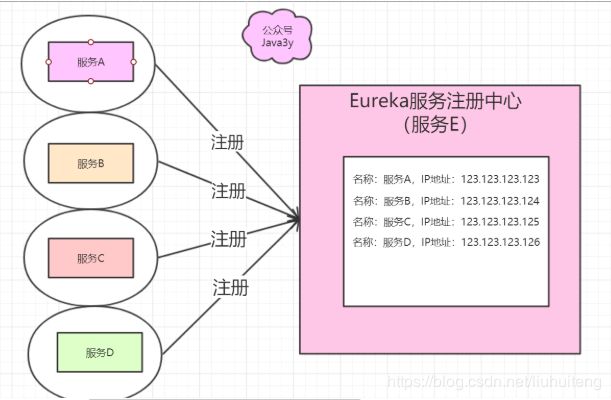
A、B、C、D四个服务都可以拿到Eureka(服务E)那份注册清单。A、B、C、D四个服务互相调用不再通过具体的IP地址,而是通过服务名来调用!
- 拿到注册清单--->注册清单上有服务名--->自然就能够拿到服务具体的位置了(IP)。
- 其实简单来说就是:代码中通过服务名找到对应的IP地址(IP地址会变,但服务名一般不会变)

2.2、服务治理Eureka实现原理
Eureka专门用于给其他服务注册的称为Eureka Server(服务注册中心),其余注册到Eureka Server的服务称为Eureka Client。
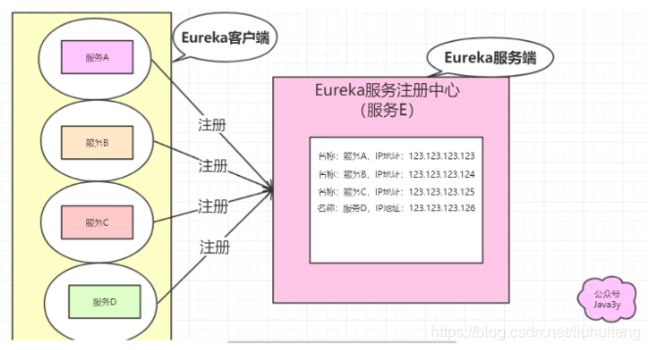
在Eureka Server一般我们会这样配置:
register-with-eureka: false #false表示不向注册中心注册自己。
fetch-registry: false #false表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务Eureka Client分为服务提供者和服务消费者。
- 但很可能,某服务既是服务提供者又是服务消费者。
如果在网上看到SpringCloud的某个服务配置没有"注册"到Eureka-Server也不用过于惊讶(但是它是可以获取Eureka服务清单的)
- 很可能只是作者把该服务认作为单纯的服务消费者,单纯的服务消费者无需对外提供服务,也就无须注册到Eureka中了
eureka:
client:
register-with-eureka: false # 当前微服务不注册到eureka中(消费端)
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/ 下面是Eureka的治理机制:
- 服务提供者
- 服务注册:启动的时候会通过发送REST请求的方式将自己注册到Eureka Server上,同时带上了自身服务的一些元数据信息。
- 服务续约:在注册完服务之后,服务提供者会维护一个心跳用来持续告诉Eureka Server: "我还活着 ” 、
- 服务下线:当服务实例进行正常的关闭操作时,它会触发一个服务下线的REST请求给Eureka Server, 告诉服务注册中心:“我要下线了 ”。
- 服务消费者
- 获取服务:当我们启动服务消费者的时候,它会发送一个REST请求给服务注册中心,来获取上面注册的服务清单
- 服务调用:服务消费者在获取服务清单后,通过服务名可以获得具体提供服务的实例名和该实例的元数据信息。在进行服务调用的时候,优先访问同处一个Zone中的服务提供方。
- Eureka Server(服务注册中心):
- 失效剔除:默认每隔一段时间(默认为60秒) 将当前清单中超时(默认为90秒)没有续约的服务剔除出去。
- 自我保护:。EurekaServer 在运行期间,会统计心跳失败的比例在15分钟之内是否低于85%(通常由于网络不稳定导致)。 Eureka Server会将当前的实例注册信息保护起来, 让这些实例不会过期,尽可能保护这些注册信息。
参考文章:
- Spring Cloud Eureka详解:https://blog.csdn.net/sunhuiliang85/article/details/76222517
- 《Spring Cloud Netflix》 -- 服务注册和服务发现-Eureka 的使用:https://zhuanlan.zhihu.com/p/26472547
- 微服务架构:Eureka参数配置项详解:https://www.cnblogs.com/fangfuhai/p/7070325.html
三、负载均衡:Ribbon
3.1、为什么使用RestTemplate和Ribbon?
通过Eureka服务治理框架,我们可以通过服务名来获取具体的服务实例的位置了(IP)。一般在使用SpringCloud的时候可以使用Spring封装好的RestTemplate工具类,不需要自己手动创建HttpClient来进行远程调用。
// 传统的方式,直接显示写死IP是不好的!
//private static final String REST_URL_PREFIX = "http://localhost:8001";
// 服务实例名
private static final String REST_URL_PREFIX = "http://MICROSERVICECLOUD-DEPT";
/**
* 使用 使用restTemplate访问restful接口非常的简单粗暴无脑。 (url, requestMap,
* ResponseBean.class)这三个参数分别代表 REST请求地址、请求参数、HTTP响应转换被转换成的对象类型。
*/
@Autowired
private RestTemplate restTemplate;
@RequestMapping(value = "/consumer/dept/add")
public boolean add(Dept dept) {
return restTemplate.postForObject(REST_URL_PREFIX + "/dept/add", dept, Boolean.class);
}为了实现服务的高可用,我们可以将服务提供者集群。比如说,现在一个秒杀系统设计出来了,准备上线了。在11月11号时为了能够支持高并发,我们开多台机器来支持并发量。
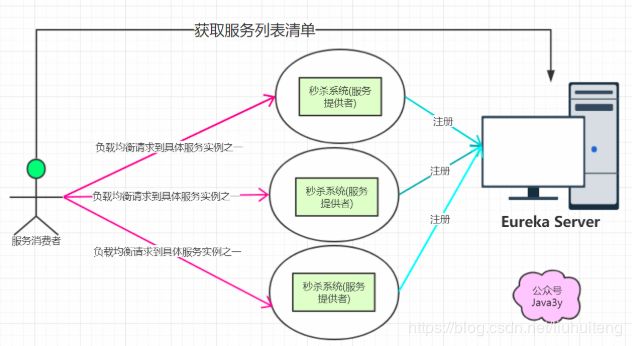
现在想要这三个秒杀系统合理摊分用户的请求(专业来说就是负载均衡),可能你会想到nginx。
其实SpringCloud也支持的负载均衡功能,只不过它是客户端的负载均衡,这个功能实现就是Ribbon!
负载均衡又区分了两种类型:
- 客户端负载均衡(Ribbon)
- 服务实例的清单在客户端,客户端进行负载均衡算法分配。
- (从上面的知识我们已经知道了:客户端可以从Eureka Server中得到一份服务清单,在发送请求时通过负载均衡算法,在多个服务器之间选择一个进行访问)
- 服务端负载均衡(Nginx)
- 服务实例的清单在服务端,服务器进行负载均衡算法分配
3.2、负载均衡Ribbon实现原理
Ribbon是支持负载均衡,默认的负载均衡策略是轮询,我们也是可以根据自己实际的需求自定义负载均衡策略的。
@Configuration
public class MySelfRule
{
@Bean
public IRule myRule()
{
//return new RandomRule();// Ribbon默认是轮询,我自定义为随机
//return new RoundRobinRule();// Ribbon默认是轮询,我自定义为随机
return new RandomRule_ZY();// 我自定义为每台机器5次
}
}
实现起来也很简单:继承AbstractLoadBalancerRule类,重写public Server choose(ILoadBalancer lb, Object key)即可。
SpringCloud 在CAP理论是选择了AP的,在Ribbon中还可以配置重试机制的
参考文章:
- 撸一撸Spring Cloud Ribbon的原理-负载均衡策略:https://www.cnblogs.com/kongxianghai/p/8477781.html
四、服务熔断保护:Hystrix
4.1、为什么需要服务熔断保护Hystrix?
到目前为止,我们的服务看起来好像挺好的了:能够根据服务名来远程调用其他的服务,可以实现客户端的负载均衡。
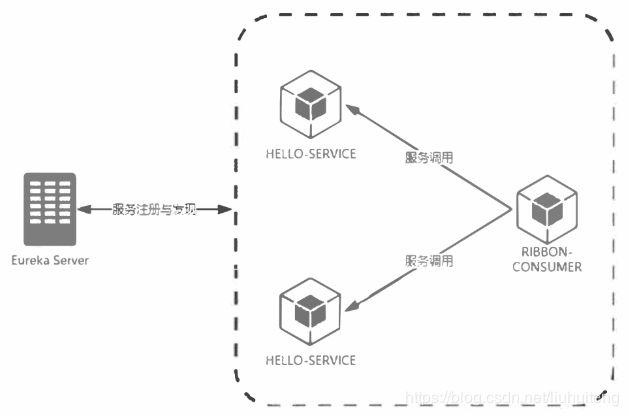
但是,如果我们在调用多个远程服务时,某个服务出现延迟,会怎么样?
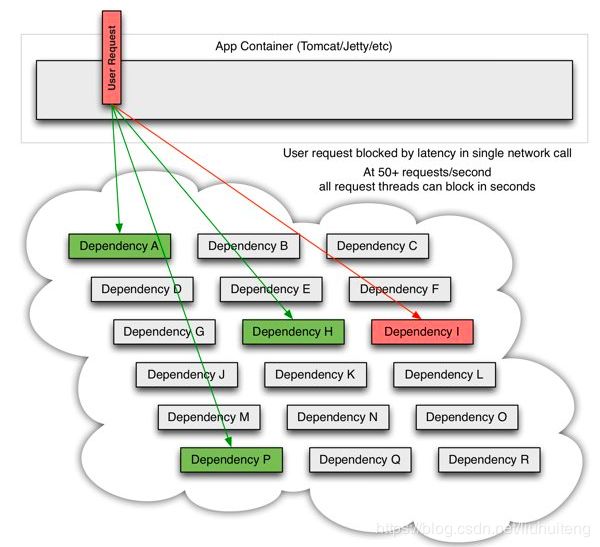
在高并发的情况下,由于单个服务的延迟,可能导致所有的请求都处于延迟状态,甚至在几秒钟就使服务处于负载饱和的状态,资源耗尽,直到不可用,最终导致这个分布式系统都不可用,这就是“雪崩”。
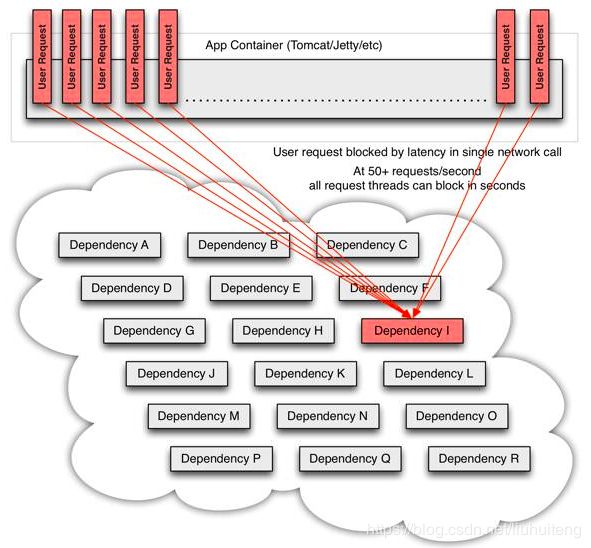
针对上述问题, Spring Cloud Hystrix实现了断路器、线程隔离等一系列服务保护功能。
- Fallback(失败快速返回):当某个服务单元发生故障(类似用电器发生短路)之后,通过断路器的故障监控(类似熔断保险丝), 向调用方返回一个错误响应, 而不是长时间的等待。这样就不会使得线程因调用故障服务被长时间占用不释放,避免了故障在分布式系统中的蔓延。
- 资源/依赖隔离(线程池隔离):它会为每一个依赖服务创建一个独立的线程池,这样就算某个依赖服务出现延迟过高的情况,也只是对该依赖服务的调用产生影响, 而不会拖慢其他的依赖服务。
Hystrix提供几个熔断关键参数:滑动窗口大小(20)、熔断器开关间隔(5s)、错误率(50%)
- 每当20个请求中,有50%失败时,熔断器就会打开,此时再调用此服务,将会直接返回失败,不再调远程服务。
- 直到5s钟之后,重新检测该触发条件,判断是否把熔断器关闭,或者继续打开。
4.2、服务熔断Hystrix实现原理
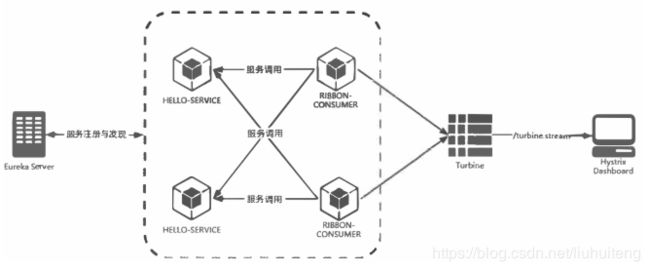
Hystrix仪表盘:它主要用来实时监控Hystrix的各项指标信息。通过Hystrix Dashboard反馈的实时信息,可以帮助我们快速发现系统中存在的问题,从而及时地采取应对措施。
启动时的页面:

监控单服务的页面:
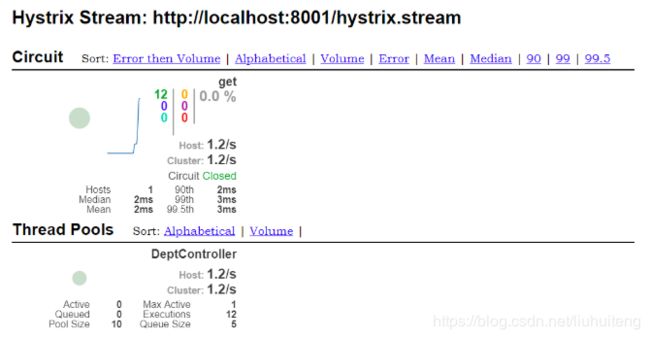
我们现在的服务(监控单服务)是这样的:
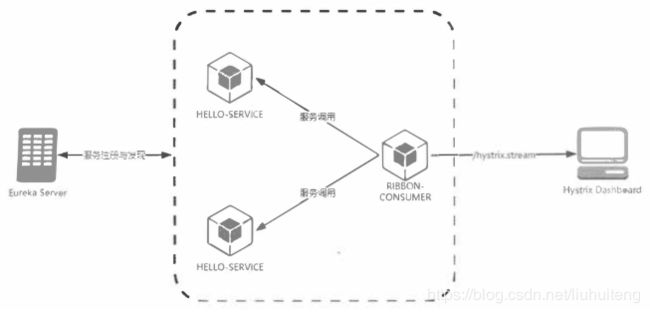
除了可以开启单个实例的监控页面之外,还有一个监控端点 /turbine.stream是对集群使用的。 从端点的命名中,可以引入Turbine, 通过它来汇集监控信息,并将聚合后的信息提供给 HystrixDashboard 来集中展示和监控。
参考文章:
- Hystrix ,为什么说它是每个系统不可或缺的开源框架?https://zhuanlan.zhihu.com/p/34304136
- 深入理解Hystrix之文档翻译:https://zhuanlan.zhihu.com/p/28523060
- 谈谈我对服务熔断、服务降级的理解:https://blog.csdn.net/guwei9111986/article/details/51649240
- Hystrix几篇文章《青芒》:https://segmentfault.com/u/yedge/articles
五、声明式服务调用:Feign
5.1、为什么使用声明式服务调用Feign
上面已经介绍了Ribbon和Hystrix了,可以发现的是:他俩作为基础工具类框架广泛地应用在各个微服务的实现中。我们会发现对这两个框架的使用几乎是同时出现的。
为了简化我们的开发,Spring Cloud Feign出现了!它基于 Netflix Feign 实现,整合了 Spring Cloud Ribbon 与 Spring Cloud Hystrix, 除了整合这两者的强大功能之外,它还提供了声明式的服务调用(不再通过RestTemplate)。
Feign是一种声明式、模板化的HTTP客户端。在Spring Cloud中使用Feign, 我们可以做到使用HTTP请求远程服务时能与调用本地方法一样的编码体验,开发者完全感知不到这是远程方法,更感知不到这是个HTTP请求。
5.2、声明式服务调用Feign使用
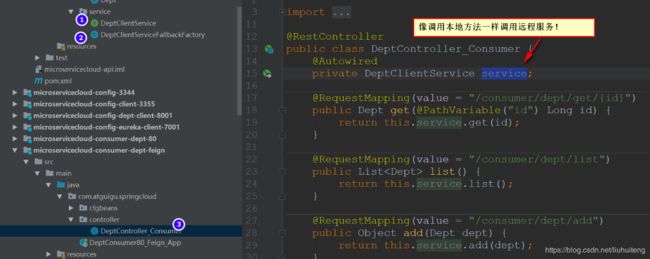
服务绑定:
// value --->指定调用哪个服务
// fallbackFactory--->熔断器的降级提示
@FeignClient(value = "MICROSERVICECLOUD-DEPT", fallbackFactory = DeptClientServiceFallbackFactory.class)
public interface DeptClientService {
// 采用Feign我们可以使用SpringMVC的注解来对服务进行绑定!
@RequestMapping(value = "/dept/get/{id}", method = RequestMethod.GET)
public Dept get(@PathVariable("id") long id);
@RequestMapping(value = "/dept/list", method = RequestMethod.GET)
public List list();
@RequestMapping(value = "/dept/add", method = RequestMethod.POST)
public boolean add(Dept dept);
} Feign中使用熔断器:
/**
* Feign中使用断路器
* 这里主要是处理异常出错的情况(降级/熔断时服务不可用,fallback就会找到这里来)
*/
@Component // 不要忘记添加,不要忘记添加
public class DeptClientServiceFallbackFactory implements FallbackFactory {
@Override
public DeptClientService create(Throwable throwable) {
return new DeptClientService() {
@Override
public Dept get(long id) {
return new Dept().setDeptno(id).setDname("该ID:" + id + "没有没有对应的信息,Consumer客户端提供的降级信息,此刻服务Provider已经关闭")
.setDb_source("no this database in MySQL");
}
@Override
public List list() {
return null;
}
@Override
public boolean add(Dept dept) {
return false;
}
};
}
} 调用:
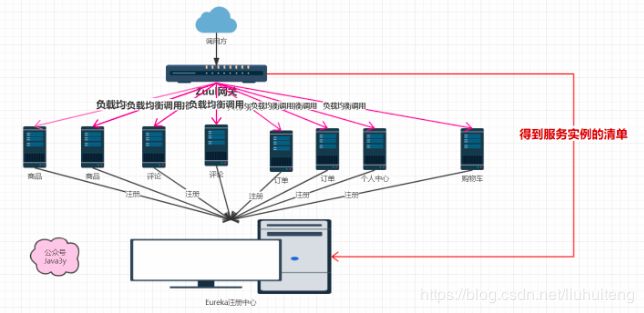
六、服务网关:Zuul
6.1、为什么需要服务网关Zuul
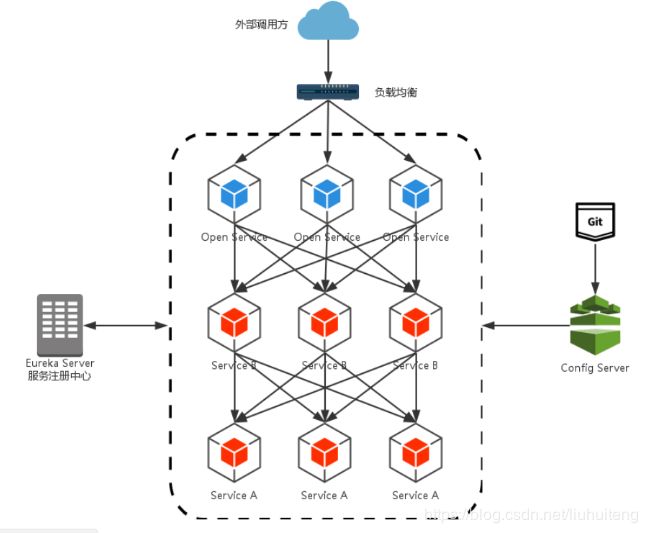
基于上面的学习,我们现在的架构很可能会设计成这样:
这样的架构会有两个比较麻烦的问题:
- 路由规则与服务实例的维护间题:外层的负载均衡(nginx)需要维护所有的服务实例清单(图上的OpenService)
- 签名校验、 登录校验冗余问题:为了保证对外服务的安全性, 我们在服务端实现的微服务接口,往往都会有一定的权限校验机制,但我们的服务是独立的,我们不得不在这些应用中都实现这样一套校验逻辑,这就会造成校验逻辑的冗余。
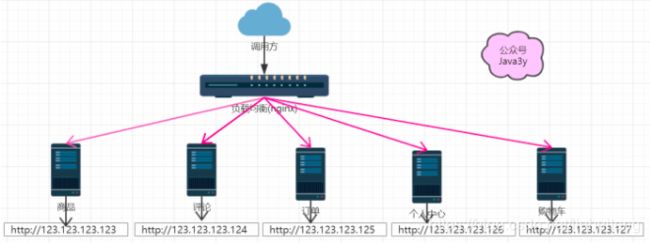
每个服务都有自己的IP地址,Nginx想要正确请求转发到服务上,就必须维护着每个服务实例的地址!
- 更是灾难的是:这些服务实例的IP地址还有可能会变,服务之间的划分也很可能会变。
http://123.123.123.123
http://123.123.123.124
http://123.123.123.125
http://123.123.123.126
http://123.123.123.127
购物车和订单模块都需要用户登录了才可以正常访问,基于现在的架构,只能在购物车和订单模块都编写校验逻辑,这无疑是冗余的代码。
为了解决上面这些常见的架构问题,API网关的概念应运而生。在SpringCloud中了提供了基于Netfl ix Zuul实现的API网关组件Spring Cloud Zuul。
Spring Cloud Zuul是这样解决上述两个问题的:
- SpringCloud Zuul通过与SpringCloud Eureka进行整合,将自身注册为Eureka服务治理下的应用,同时从Eureka中获得了所有其他微服务的实例信息。外层调用都必须通过API网关,使得将维护服务实例的工作交给了服务治理框架自动完成。
- 在API网关服务上进行统一调用来对微服务接口做前置过滤,以实现对微服务接口的拦截和校验。
Zuul天生就拥有线程隔离和断路器的自我保护功能,以及对服务调用的客户端负载均衡功能。也就是说:Zuul也是支持Hystrix和Ribbon。
关于Zuul还有很多知识点:
- 路由匹配(动态路由)
- 过滤器实现(动态过滤器)
- 默认会过滤掉Cookie与敏感的HTTP头信息(额外配置)
6.2、服务网关Zuul原理
Zuul支持Ribbon和Hystrix,也能够实现客户端的负载均衡。我们的Feign不也是实现客户端的负载均衡和Hystrix的吗?既然Zuul已经能够实现了,那我们的Feign还有必要吗?
或者可以这样理解:
- zuul是对外暴露的唯一接口相当于路由的是controller的请求,而Ribbonhe和Fegin路由了service的请求
- zuul做最外层请求的负载均衡 ,而Ribbon和Fegin做的是系统内部各个微服务的service的调用的负载均衡
有了Zuul,还需要Nginx吗?他俩可以一起使用吗?
- 我的理解:Zuul和Nginx是可以一起使用的(毕竟我们的Zuul也是可以搭成集群来实现高可用的),要不要一起使用得看架构的复杂度了(业务)~~~
参考文章:
- 微服务与API网关(上): 为什么需要API网关?:http://blog.didispace.com/hzf-ms-apigateway-1/
- 谈谈 API 网关:https://www.jianshu.com/p/b52a2773e75f
- 谈谈微服务中的 API 网关(API Gateway):https://www.cnblogs.com/savorboard/p/api-gateway.html
- API网关性能比较:NGINX vs. ZUUL vs. Spring Cloud Gateway :http://www.360doc.com/content/18/0208/05/46368139_728502763.shtml
- 谈API网关的背景、架构以及落地方案:http://www.infoq.com/cn/news/2016/07/API-background-architecture-floo
- zuul和nginx:https://zhuanlan.zhihu.com/p/37385481
七、分布式配置中心Config
7.1、为什么需要配置中心Config
随着业务的扩展,我们的服务会越来越多,越来越多。每个服务都有自己的配置文件。
既然是配置文件,给我们配置的东西,那难免会有些改动的。
比如我们的Demo中,每个服务都写上相同的配置文件。万一我们有一天,配置文件中的密码需要更换了,那就得三个都要重新更改。
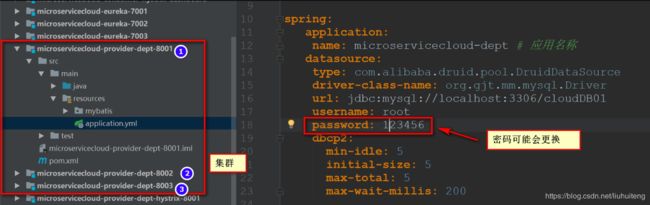
注意:在分布式系统中,某一个基础服务信息变更,都很可能会引起一系列的更新和重启
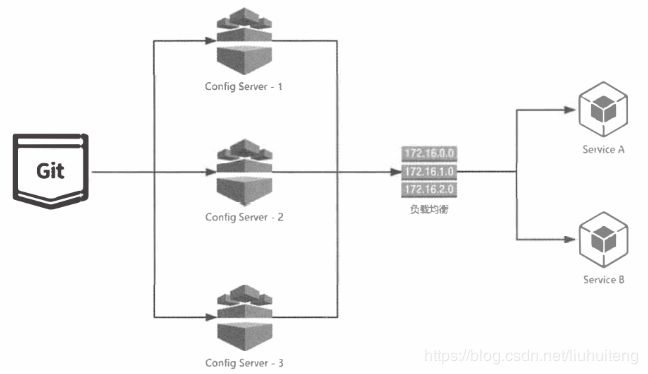
Spring Cloud Config项目是一个解决分布式系统的配置管理方案。它包含了Client和Server两个部分,server提供配置文件的存储、以接口的形式将配置文件的内容提供出去,client通过接口获取数据、并依据此数据初始化自己的应用。
- 简单来说,使用Spring Cloud Config就是将配置文件放到统一的位置管理(比如GitHub),客户端通过接口去获取这些配置文件。
- 在GitHub上修改了某个配置文件,应用加载的就是修改后的配置文件。
SpringCloud Config其他的知识:
- 在SpringCloud Config的服务端, 对于配置仓库的默认实现采用了Git,我们也可以配置SVN。
- 配置文件内的信息加密和解密
- 修改了配置文件,希望不用重启来动态刷新配置,配合Spring Cloud Bus 使用
其他文章:Spring Cloud 微服务架构学习笔记与示例