机器学习算法:多元高斯模型
本文结构如下:
- 1:多元正态分布及可视化
- 2:双高斯独立分布可视化
- 3:从零开始推导多元高斯分布
- 4:多元正态分布性质
- 5:高斯判别分析模型
- 6:高斯判别分析模型Demo
1: 多元正态分布及可视化
多元正态分布也叫多元高斯分布,这个分布的两个参数分别是平均向量 和一个协方差矩阵
其中: ,且是对称、半正定的。
若 ,则其概率密度是:
下面用python进行可视化多元正态分布:
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
import matplotlib as mpl
num = 200
l = np.linspace(-5,5,num)
X, Y = np.meshgrid(l, l) #meshgrid的作用适用于生成网格型数据,可以接受两个一维数组生成两个二维矩阵
#np.expand_dims增加一个维度(下面是增加第三维)
pos = np.concatenate((np.expand_dims(X,axis=2),np.expand_dims(Y,axis=2)),axis=2)
def plot_multi_normal(u,sigma):
fig = plt.figure(figsize=(12,7))
ax = Axes3D(fig)
a = (pos-u).dot(np.linalg.inv(sigma)) #np.linalg.inv()矩阵求逆
b = np.expand_dims(pos-u,axis=3)
Z = np.zeros((num,num), dtype=np.float32)
for i in range(num):
Z[i] = [np.dot(a[i,j],b[i,j]) for j in range(num)]
Z = np.exp(Z*(-0.5))/(2*np.pi*(np.linalg.det(sigma))**(0.5)) #np.linalg.det()矩阵求行列式
ax.plot_surface(X, Y, Z, rstride=5, cstride=5, alpha=0.4, cmap=mpl.cm.bwr)
cset = ax.contour(X,Y,Z, zdir='z',offset=0,cmap=cm.coolwarm,alpha=0.8) #contour画等高线
cset = ax.contour(X, Y, Z, zdir='x', offset=-5,cmap=mpl.cm.winter,alpha=0.8)
cset = ax.contour(X, Y, Z, zdir='y', offset= 5,cmap= mpl.cm.winter,alpha=0.8)
ax.set_zlim([0,0.3])
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('Z')
plt.show()
u = np.array([0, 0])
sigma = np.array([[1, 0],[0, 1]])
plot_multi_normal(u,sigma)

u = np.array([0, 0])
sigma = np.array([[0.8, 0],[0, 0.8]])
plot_multi_normal(u,sigma)
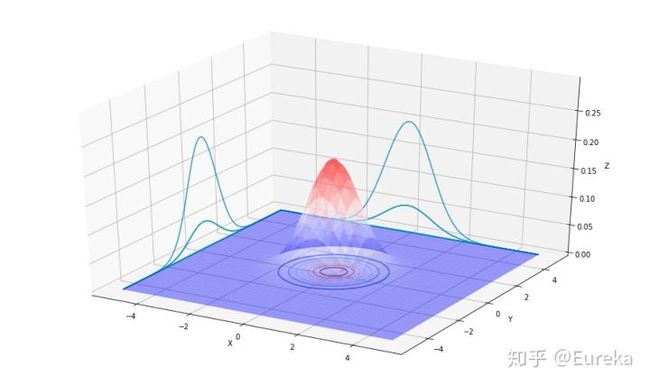
u = np.array([0, 0])
sigma = np.array([[1.5, 0],[0, 1.5]])
plot_multi_normal(u,sigma)
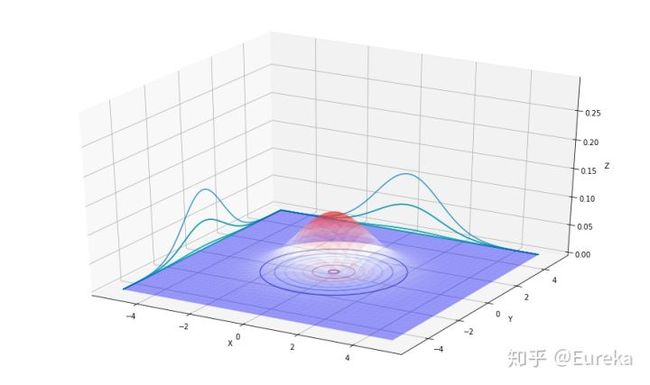
第一幅图像展现的二维高斯分布的均值是零向量(2x1的零向量),协方差矩阵,像这样以零向量为均值以单位阵为协方差的多维高斯分布称为标准正态分布,第二幅图像以零向量为均值, ;第三幅图像中 ,观察发现当 越大时,高斯分布越“铺开”,当 越小时,高斯分布越“收缩”。
让我们继续更换 的值看看图像如何变换:
u = np.array([0, 0])
sigma = np.array([[1, 0],[0, 1]])
plot_multi_normal(u,sigma)
u = np.array([0, 0])
sigma = np.array([[1, 0.4],[0.4, 1]])
plot_multi_normal(u,sigma)
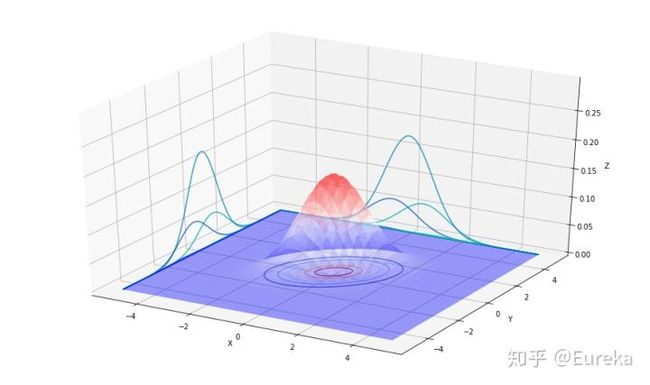
u = np.array([0, 0])
sigma = np.array([[1, 0.8],[0.8, 1]])
plot_multi_normal(u,sigma)

上图中展示的三个高斯分布对应的均值均为零向量,协方差矩阵分别对应与下面三个 ; ;
最第一幅图像是标准二维正态分布,当我们增加 的非主对角元素时,概率密度图像沿着45°线 “收缩”,从对应的等高线轮廓图可以跟清楚的看到这一点:
最后我们再改变下不同的 看看:
u = np.array([0, 0])
sigma = np.array([[1, -0.5],[-0.5, 1]])
plot_multi_normal(u,sigma)

u = np.array([0, 0])
sigma = np.array([[1, -0.8],[-0.8, 1]])
plot_multi_normal(u,sigma)

u = np.array([0, 0])
sigma = np.array([[3, -0.8],[-0.8, 1]])
plot_multi_normal(u,sigma)

上图中展示的三个高斯分布对应的均值均为零向量,协方差矩阵分别对应与下面三个 ; ;
通过对比发现,通过改变非主对角元素的符号时,概率密度收缩方向会改变;对比第二和第三幅发现,通过减少主对角元素可以让概率密度图像变得“收缩”。
最后,我们固定 ,变动 ,从而可以移动概率密度图像的均值。
u = np.array([1, 0])
sigma = np.array([[1, 0],[0, 1]])
plot_multi_normal(u,sigma)

u = np.array([-0.5, 0])
sigma = np.array([[1, 0],[0, 1]])
plot_multi_normal(u,sigma)

u = np.array([-1, -1.5])
sigma = np.array([[1, 0],[0, 1]])
plot_multi_normal(u,sigma)

1.2 双高斯独立分布可视化
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
import matplotlib as mpl
num = 200
l = np.linspace(-5,5,num)
X, Y =np.meshgrid(l, l)
pos = np.concatenate((np.expand_dims(X,axis=2),np.expand_dims(Y,axis=2)),axis=2)
def plot_two_gaussian(u1,sigma1,u2,sigma2):
fig = plt.figure(figsize=(12,7))
ax = Axes3D(fig)
a1 = (pos-u1).dot(np.linalg.inv(sigma1))
b1 = np.expand_dims(pos-u1,axis=3)
Z1 = np.zeros((num,num), dtype=np.float32)
a2 = (pos-u2).dot(np.linalg.inv(sigma2))
b2 = np.expand_dims(pos-u2,axis=3)
Z2 = np.zeros((num,num), dtype=np.float32)
for i in range(num):
Z1[i] = [np.dot(a1[i,j],b1[i,j]) for j in range(num)]
Z2[i] = [np.dot(a2[i,j],b2[i,j]) for j in range(num)]
Z1 = np.exp(Z1*(-0.5))/(2*np.pi*(np.linalg.det(sigma1))**0.5)
Z2 = np.exp(Z2*(-0.5))/(2*np.pi*(np.linalg.det(sigma2))**0.5)
Z = Z1 + Z2
ax.plot_surface(X, Y, Z, rstride=5, cstride=5, alpha=0.4, cmap=mpl.cm.bwr)
cset = ax.contour(X,Y,Z, zdir='z',offset=0,cmap=cm.coolwarm,alpha=0.8) #contour画等高线
cset = ax.contour(X, Y, Z, zdir='x', offset=-5,cmap=mpl.cm.winter,alpha=0.8)
cset = ax.contour(X, Y, Z, zdir='y', offset= 5,cmap= mpl.cm.winter,alpha=0.8)
ax.set_zlim([0,0.3])
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('Z')
plt.show()
u1 = np.array([1.3, 1.3])
sigma1 = np.array([[1, 0],[0, 1]])
u2 = np.array([-1.3, -1.3])
sigma2 = np.array([[1, 0],[0, 1]])
plot_two_gaussian(u1,sigma1,u2,sigma2)

1.3 从零开始推导多元高斯分布
这部分推导搬运的这篇文章:从零开始推导多元高斯分布 因原文在符号上有些错误,因此做了些修正。
我们已经非常熟悉一元正态分布,我们先假设均值为0,方差为1,其密度函数如下: 。
当均值为 ,方差为 时,我们先标准化一下: ,标准化之后方差变为1。标准化的意义在于将数据点$x$到均值$\mu$的距离转化为数据点$x$到均值的距离等于多少个总体的标准差 ,这样,就消除了数据分布差异和量纲对概率计算的影响,此时的概率密度函数为:
可见,高斯分布的概率密度计算核心在于计算数据点到中心的距离,并且除以标准差将这个绝对距离转化为相对距离,然后通过距离平方的指数衰减计算概率密度。
回到多元正态分布,先从独立的多元正态分布入手,数据点通过 维的列向量描述 ,各个维度的均值方差分别为 来描述,高斯概率密度函数可以表示为:
下面用矩阵表示:
,由于假设了各个维度之间不相关,因此协方差矩阵只有在对角线的位置有值,代表不同变量的方差大小。
则:
那么假如维度之间互相关的多元高斯分布中,如何计算相对距离呢?在吴恩达机器学习视频里有这样一个例子:这是一个二维正态分布,memory use和CPU load之间存在明显的正相关关系,如果按照之前维度不相关的计算方法,图中的绿色异常点就会被视作是正常的(真实分布是倾斜的椭圆)。

一个直观上的思想是用化归的思想,将相关变成不相关。在这个例子中,直觉的做法是找到倾斜的椭圆分布的长轴方向 和短轴方向 ,计算数据点在这两个轴上的坐标(变换到这两个方向之后,新的维度之间显然是不相关的),以长轴为$x$轴,短轴为$y$轴建立新的坐标系;经过这样的变换后相当于将倾斜的椭圆放平,此时数据的各个维度之间不相关(其实就是PCA),就可以用前面各维度不相关的高斯分布解了。如下图所示:
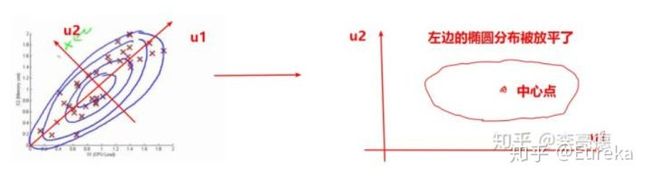
如果变换的方向 和 用列向量 ,那么数据的投影长度可以用点积来计算为: 。投影长度代表了数据点在 方向上的坐标。
这个过程可以用矩阵变换表示为:
需要注意的是 , 都是单位向量,而且相互垂直,所以 是一个正交矩阵
现在数据的各个维度已经去相关,那么我们可以用前面的各维度独立的多元正态分布来计算了。在计算之前还需要将数据标准化一下,消除一下量纲的影响:
这里
上面公式可以简单如下图表示:
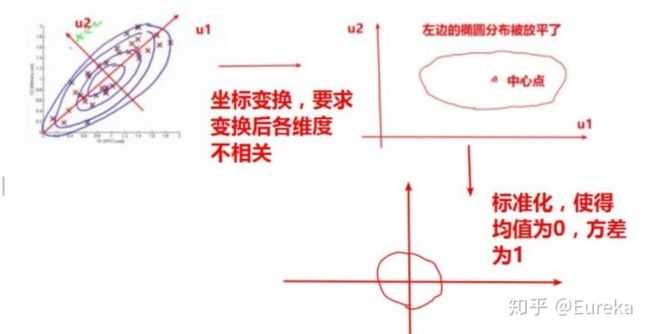
后面的推导核心在于构建变换前后协方差矩阵的关系,发现将变换前协方差矩阵对角化之后就得到了变换后的协方差矩阵。
$d^{2}
将 带入:
将 带入:
是去相关性后数据的协方差矩阵,因为是对角,所以逆等于对角元素的倒数。
对于这个方程我们需找出变换的方向,再算出变换后的方差,很麻烦。但是有个定义可以让我们更简单的得到:变换后数据各维度不相关,也就是说变换后的协方差矩阵是对角阵,即: 。
从定义出发:
由上面推导知:
代入得:
注意:我们在计算的过程中,得到的最终零均值,方差为1的 ,相当于对原坐标 做了一次变换:
使 成为去相关的零均值,方差为1的正态分布,因此概率密度函数在源空间做全空间积分的时候需要做换元变换,整体减小了 (雅可比),因为 ,所以 。
所以为了保证概率密度函数全空间积分为1,需要乘上 ,还需要除以
这一项是在计算 的积分时引入的,每个维度都会有,所以是 次方
因此整体的概率密度函数:
补充一点,上面的推导过程中,是基于二元正态分布推导的,但这个推导过程对于任意的 维向量都是适用的,所以在最后的表达式里面,写成了 维了。
总结:这里主要思想是通过线性变换,将数据的各维度去相关,再将去相关后的数据标准化,但是在推导概率分布过程中,可以消去这个变换,只需要求源空间的协方差矩阵就可以了。其实,这个过程跟主成分分析的过程很相似的,不过主成分分析的过程是在对数据去相关之后,取前面K个方差最大(保留信息)的方向。这样来说,实现主成分分析也是很简单的,根据 ,你只需要用大一的线代知识将 对角化就可以了(特征值分解)!得到的 就是变化的方向!变换后的新坐标: 就是数学建模同学老是挂在嘴边的主成分得分。
1.3 多元正态分布性质
当 进行分块: ,第一部分大小为 ,第二部分大小为 ,对应的期望: ;也对 做同样的分解: .
则我们定义 (Schur补)有: ; ;
定理: 假如 ,则
(1) ; ;
(2) 与 独立
(3) 条件分布
证明:
上式等价于做如下变换:
用矩阵表示:
,可得雅可比值 。
记 ,得 ,将此带入概率密度函数(简单化假设期望为零):
其中 :
对于行列式:
代入密度函就得:
第一条和第二条即证毕。
对于上述证明,需记住:
(1) ,其中 是 的Schur补;
(2)当 正定,只有当 和 分别正定;
此外我们定义:
可以得: ;
现在我们假设: ,
我们可以组合成矩阵: ,下面求 的分布
此为矩阵元正态分布(Matrix-Variable Normal Distribution)
1.4 高斯判别分析模型
高斯判别算法是一个典型的生成学习算法,在这个算法中,我们假设 服从多元正态分布。
当我们处理输入特征是连续随机变量 时的分类问题时,我们可以使用高斯判别分析模型(GDA),用多元正态分布模型来描述 ,模型的具体数学表达式是这样的:
写出他们的概率分布为:
现在我们模型有4个参数: ,这里我们假设对不同的 ,期望不同,协方差一样。下面极大似然函数来估计四个参数:
通过最大化似然函数l可以得到上面四个参数的估计值:
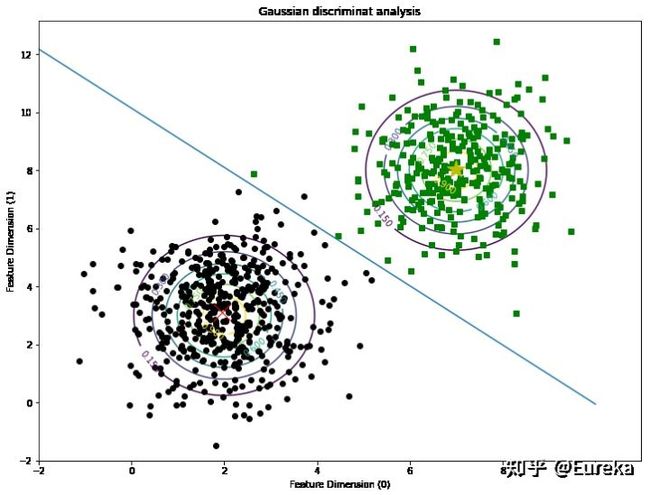
1.6 高斯判别分析模型Demo
这部分参考:高斯判别分析模型
import matplotlib.pyplot as plt
import numpy as np
#随机从高斯分布中生成两个数据集
mean0=[2,3]
cov=np.mat([[1,0],[0,2]])
x0=np.random.multivariate_normal(mean0,cov,500).T
y0=np.zeros(x0.shape[1]) #第一类,标签为0
mean1=[7,8]
cov=np.mat([[1,0],[0,2]])
x1=np.random.multivariate_normal(mean1,cov,300).T
y1=np.ones(x1.shape[1]) #第二类类,标签为1
x=np.concatenate((x0,x1),axis=1)
y=np.concatenate((y0,y1),axis=0)
m=x.shape[1]
#根据公式计算参数:\phi,\u0,\u1,\Sigma
phi=(1.0/m)*len(y1)
u0=np.mean(x0,axis=1)
u1=np.mean(x1,axis=1)
#将原先数据保存,进行画图
xplot0=x0
xplot1=x1
x0=x0.T
x1=x1.T
x=x.T
x0_sub_u0=x0-u0
x1_sub_u1=x1-u1
x_sub_u=np.concatenate([x0_sub_u0,x1_sub_u1])
x_sub_u=np.mat(x_sub_u)
sigma=(1.0/m)*(x_sub_u.T*x_sub_u)
#使用u0_u1中点画决策边界
midPoint=[(u0[0]+u1[0])/2.0,(u0[1]+u1[1])/2.0]
k=(u1[1]-u0[1])/(u1[0]-u0[0])
x=range(-2,11)
y=[(-1.0/k)*(i-midPoint[0])+midPoint[1] for i in x]
#画高斯判别的contour
def gaussian_2d(x, y, x0, y0, sigmaMatrix):
return np.exp(-0.5*((x-x0)**2+0.5*(y-y0)**2))
delta = 0.025
xgrid0=np.arange(-2, 6, delta)
ygrid0=np.arange(-2, 6, delta)
xgrid1=np.arange(3,11,delta)
ygrid1=np.arange(3,11,delta)
X0,Y0=np.meshgrid(xgrid0, ygrid0) #generate the grid
X1,Y1=np.meshgrid(xgrid1,ygrid1)
Z0=gaussian_2d(X0,Y0,2,3,cov)
Z1=gaussian_2d(X1,Y1,7,8,cov)
plt.figure(figsize=(12,9))
plt.clf()
plt.plot(xplot0[0],xplot0[1],'ko')
plt.plot(xplot1[0],xplot1[1],'gs')
plt.plot(u0[0],u0[1],'rx',markersize=20)
plt.plot(u1[0],u1[1],'y*',markersize=20)
plt.plot(x,y)
CS0=plt.contour(X0, Y0, Z0)
plt.clabel(CS0, inline=1, fontsize=10)
CS1=plt.contour(X1,Y1,Z1)
plt.clabel(CS1, inline=1, fontsize=10)
plt.title("Gaussian discriminat analysis")
plt.xlabel('Feature Dimension (0)')
plt.ylabel('Feature Dimension (1)')
plt.show()