用两阶段聚合法解决Flink keyBy()算子倾斜
这是上周出现的问题了,简单做个记录。
有一个按平台类型实时统计用户活跃的程序,代码框架如下。
DataStream sourceStream = env
.addSource(new FlinkKafkaConsumer011<>(
// ...
));
DataStream watermarkedStream = sourceStream
.map(message -> JSON.parseObject(message, UserActionRecord.class))
.assignTimestampsAndWatermarks(
// ...
);
WindowedStream windowedStream = watermarkedStream
.keyBy("platform")
.window(TumblingEventTimeWindows.of(Time.minutes(1)));
DataStream minutelyPartialAggStream = windowedStream
.aggregate(new ViewAggregateFunc(), new ViewSumWindowFunc());
minutelyPartialAggStream
.keyBy("windowEndTimestamp")
.process(new OutputPvUvProcessFunc(), TypeInformation.of(OutputPvUvResult.class))
.addSink(new RedisSink<>(jedisPoolConfig, new PvUvStringRedisMapper()))
.setParallelism(1);
就是水印→开窗→聚合→输出的经典套路。程序正常运行一段时间之后,连续报检查点超时和back pressure。
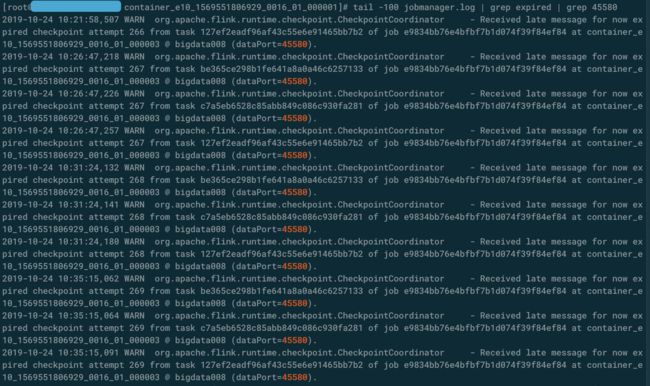

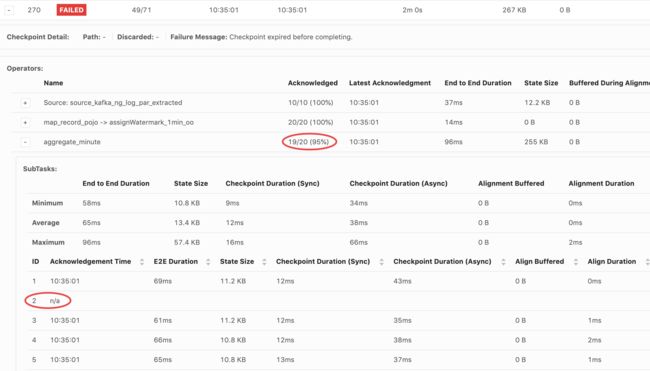

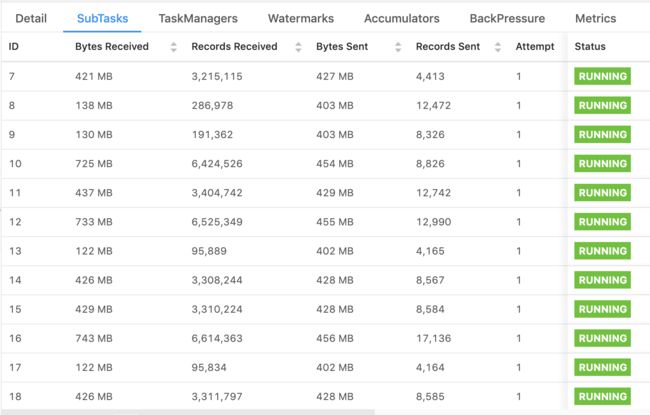
通过上面的截图,容易看出是keyBy("platform")导致大部分数据集中在了一个SubTask上,处理不过来了。由于该程序只涉及聚合,没有join,因此用两阶段聚合法很合适。在之前编写Spark程序时,我们也经常这样解决数据倾斜的问题,示例思路如下图所示。
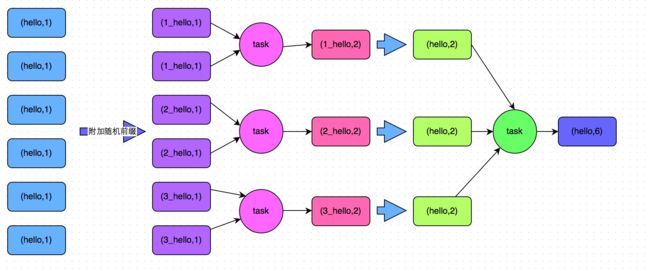
图来自美团技术团队的博客:https://tech.meituan.com/2016/05/12/spark-tuning-pro.html
接下来修改代码,先为platform字段增加一个随机后缀(前缀后缀无所谓)。
sourceStream
.map(message -> {
UserActionRecord record = JSON.parseObject(message, UserActionRecord.class);
String platform = record.getPlatform();
record.setPlatform(platform + "@" + ThreadLocalRandom.current().nextInt(20));
return record;
})
这里用ThreadLocalRandom来产生随机数,后面会写文章来唠唠它。
聚合函数的写法如下:
public static final class ViewAggregateFunc
implements AggregateFunction {
private static final long serialVersionUID = 1L;
@Override
public ViewAccumulator createAccumulator() {
return new ViewAccumulator();
}
@Override
public ViewAccumulator add(UserActionRecord record, ViewAccumulator acc) {
if (acc.getKey().isEmpty()) {
acc.setKey(record.getPlatform());
}
acc.addCount(1);
acc.addUserId(record.getUserId());
return acc;
}
@Override
public ViewAccumulator getResult(ViewAccumulator acc) {
return acc;
}
@Override
public ViewAccumulator merge(ViewAccumulator acc1, ViewAccumulator acc2) {
if (acc1.getKey().isEmpty()) {
acc1.setKey(acc2.getKey());
}
acc1.addCount(acc2.getCount());
acc1.addUserIds(acc2.getUserIds());
return acc1;
}
}
累加器类ViewAccumulator的写法如下:
public class ViewAccumulator extends Tuple3> {
private static final long serialVersionUID = 1L;
public ViewAccumulator() { super("", 0, new HashSet<>(2048)); }
public ViewAccumulator(String key, int count, Set userIds) { super(key, count, userIds); }
public String getKey() { return this.f0; }
public void setKey(String key) { this.f0 = key; }
public int getCount() { return this.f1; }
public void addCount(int count) { this.f1 += count; }
public Set getUserIds() { return this.f2; }
public void addUserId(String userId) { this.f2.add(userId); }
public void addUserIds(Set userIds) { this.f2.addAll(userIds); }
}
因为是按分钟统计UV,所以用较大的HashSet还是没有瓶颈的。如果窗口更长或者数据量非常大,就要考虑HyperLogLog了。
接下来在WindowFunction输出窗口结果时,把后缀去掉。
public static final class ViewSumWindowFunc
implements WindowFunction {
private static final long serialVersionUID = 1L;
@Override
public void apply(
Tuple key,
TimeWindow window,
Iterable accs,
Collector out) throws Exception {
ViewAccumulator acc = accs.iterator().next();
String type = acc.getKey();
out.collect(new WindowedViewSum(
type.substring(0, type.indexOf("@")),
window.getStart(),
window.getEnd(),
acc.getCount(),
acc.getUserIds()
));
}
}
最后的ProcessFunction输出最终结果时,将各条记录中的PV简单相加,UV则是将各个用户ID的集合拼在一起并计数得到。状态的存储可以用AggregatingState,但是它的文档基本为0,不想冒这个险,所以我们还是选择了传统的ListState,并自己做聚合。代码如下。
public static final class OutputPvUvProcessFunc
extends KeyedProcessFunction {
private static final long serialVersionUID = 1L;
private static final String TIME_MINUTE_FORMAT = "yyyy-MM-dd HH:mm";
private ListState state;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
state = this.getRuntimeContext().getListState(new ListStateDescriptor<>(
"state_windowed_pvuv_sum",
WindowedViewSum.class
));
}
@Override
public void processElement(WindowedViewSum input, Context ctx, Collector out) throws Exception {
state.add(input);
ctx.timerService().registerEventTimeTimer(input.getWindowEndTimestamp() + 1);
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector out) throws Exception {
Map>> result = new HashMap<>();
String timeInMinute = "";
for (WindowedViewSum viewSum : state.get()) {
if (timeInMinute.isEmpty()) {
timeInMinute = new LocalDateTime(viewSum.getWindowStartTimestamp()).toString(TIME_MINUTE_FORMAT);
}
String key = viewSum.getKey();
if (!result.containsKey(key)) {
result.put(key, new Tuple2<>(0, new HashSet<>(2048)));
}
Tuple2> puv = result.get(key);
puv.f0 += viewSum.getPv();
puv.f1.addAll(viewSum.getUserIds());
}
JSONObject json = new JSONObject();
for (Entry>> entry : result.entrySet()) {
String key = entry.getKey();
Tuple2> value = entry.getValue();
json.put(key.concat("_pv"), value.f0);
json.put(key.concat("_uv"), value.f1.size());
}
json.put("time", timeInMinute.substring(11));
state.clear();
out.collect(new OutputPvUvResult(
timeInMinute.substring(0, 10),
timeInMinute.substring(11),
json.toJSONString()
));
}
}
这样处理之后,程序再也没有出过问题。查看Web UI,虽然数据在SubTask之间的分布仍然不太均匀(因为keyBy()算子是通过key的hash code来分发的),但是完全在可接受的范围内了。