视觉SLAM十四讲-第十讲笔记
本讲开始进入后端模块。后端优化目前分为基于滤波器的方法和基于非线性优化的方法,本讲讲述以EKF为代表的滤波器法,以及稀疏性。
一、 后端优化概述
1. 后端模块的作用
前端估计得到:
- k k k时刻相机的位姿, x k x_k xk
- 地图中路标 j j j的世界坐标, y j y_j yj
前端估计只基于 k k k的前一时刻或前几时刻。后端优化所做的,则是根据到目前为止观测到的所有信息,优化之前的估计结果。
后端优化中,把位姿 x x x和路标 y y y都看做服从某种概率分布的随机变量。已知相机运动数据 u u u,观测数据 z z z,问题转化为确定其概率分布,进行最大似然估计。
后端优化主要有两种方法:
- 假设马尔科夫性, k k k时刻状态只与 k − 1 k-1 k−1时刻有关。即本讲的EKF法。
- 假设 k k k时刻状态与之前所有状态有关,为基于非线性优化的方法。将在下一讲详细阐释。
2. 问题描述
变量:
x k x_k xk: k k k时刻下所有未知量,包含相机和此时刻m个可见路标。
已知:
u 1 : k u_{1:k} u1:k:前 k k k帧的运动数据。
z 1 : k z_{1:k} z1:k:前 k k k帧的观测数据。
估计:
P ( x k ∣ x 0 , u 1 : k , z 1 : k ) P(x_k|x_0,u_{1:k},z_{1:k}) P(xk∣x0,u1:k,z1:k):根据所有已知,估计现在的位姿和路标的状态分布。
根据贝叶斯法则:
P ( x k ∣ x 0 , u 1 : k , z 1 : k ) ∝ P ( z k ∣ x k ) P ( x k ∣ x 0 , u 1 : k , z 1 : k − 1 ) P(x_k|x_0,u_{1:k},z_{1:k})∝P(z_k|x_k)P(x_k|x_0,u_{1:k},z_{1:k-1}) P(xk∣x0,u1:k,z1:k)∝P(zk∣xk)P(xk∣x0,u1:k,z1:k−1)
即:后验正比于似然乘先验。
其中,先验指前 k − 1 k-1 k−1帧的观测。根据马尔科夫假设,对先验展开得:
P ( x k ∣ x 0 , u 1 : k , z 1 : k − 1 ) = ∫ P ( x k ∣ x k − 1 , x 0 , u 1 : k , z 1 : k − 1 ) P ( x k − 1 ∣ x 0 , u 1 : k , z 1 : k − 1 ) d x k − 1 P(x_k|x_0,u_{1:k},z_{1:k-1})=\int P(x_k|x_{k-1},x_0,u_{1:k},z_{1:k-1})P(x_{k-1}|x_0,u_{1:k},z_{1:k-1})dx_{k-1} P(xk∣x0,u1:k,z1:k−1)=∫P(xk∣xk−1,x0,u1:k,z1:k−1)P(xk−1∣x0,u1:k,z1:k−1)dxk−1
即: x k x_k xk受 x k − 1 x_{k-1} xk−1影响,考虑所有 k − 1 k-1 k−1时刻的 x x x可能,对每一种可能,其概率是 x k − 1 x_{k-1} xk−1下 x k x_{k} xk的概率,乘以 x k − 1 x_{k-1} xk−1的概率。
问题的最终目标是:求状态变量的最大后验概率形式。
二、 卡尔曼滤波器
1. 线性系统和卡尔曼滤波器(KF)
根据马尔科夫性,当前时刻状态只和上一时刻有关。我们来化简先验概率部分,把这个公式挪下来:
P ( x k ∣ x 0 , u 1 : k , z 1 : k − 1 ) = ∫ P ( x k ∣ x k − 1 , x 0 , u 1 : k , z 1 : k − 1 ) P ( x k − 1 ∣ x 0 , u 1 : k , z 1 : k − 1 ) d x k − 1 P(x_k|x_0,u_{1:k},z_{1:k-1})=\int P(x_k|x_{k-1},x_0,u_{1:k},z_{1:k-1})P(x_{k-1}|x_0,u_{1:k},z_{1:k-1})dx_{k-1} P(xk∣x0,u1:k,z1:k−1)=∫P(xk∣xk−1,x0,u1:k,z1:k−1)P(xk−1∣x0,u1:k,z1:k−1)dxk−1
等式右边第一项可以化简为:
P ( x k ∣ x k − 1 , x 0 , u 1 : k , z 1 : k − 1 ) = P ( x k ∣ x k − 1 , u k ) P(x_k|x_{k-1},x_0,u_{1:k},z_{1:k-1})=P(x_k|x_{k-1},u_{k}) P(xk∣xk−1,x0,u1:k,z1:k−1)=P(xk∣xk−1,uk)
第二项化简为:
P ( x k − 1 ∣ x 0 , u 1 : k , z 1 : k − 1 ) = P ( x k − 1 ∣ x 0 , u 1 : k − 1 , z 1 : k − 1 ) P(x_{k-1}|x_0,u_{1:k},z_{1:k-1})=P(x_{k-1}|x_0,u_{1:k-1},z_{1:k-1}) P(xk−1∣x0,u1:k,z1:k−1)=P(xk−1∣x0,u1:k−1,z1:k−1)
我对这两个式子化简的理解是:第一个是在 k − 1 k-1 k−1时刻状态 x k − 1 x_{k-1} xk−1的条件下,得到 k k k时刻状态 x k x_k xk的概率。因为马尔可夫性,所以与 x 0 x_0 x0无关。但是去掉 z k − 1 z_{k-1} zk−1并不理解。是指它是基于状态的概率,因此与观测无关吗? 这可以看做运动方程。
第二个式子是 x k − 1 x_{k-1} xk−1的概率,不涉及马尔可夫性,如 x k − 2 x_{k-2} xk−2的条件,因此只讲发生在其后的 u k u_k uk去掉。这可以看做上一帧的状态分布。
因此所做的事情是,根据上一时刻的状态分布,根据运动方程,二者结合得到当前时刻的先验,进而得到这一时刻的状态分布(后验)。
1.1. 线性高斯系统
使用线性方程描述运动方程和观测方程:
x k = A k x k − 1 + u k + w k x_k=A_kx_{k-1}+u_k+w_k xk=Akxk−1+uk+wk
z k = C k x k + v k z_k=C_kx_k+v_k zk=Ckxk+vk
这个很好理解, A , C A,C A,C是转移矩阵, u , z u,z u,z是运动数据和观测数据, w , v w,v w,v是噪声。
输入是 x k − 1 x_{k-1} xk−1的后验,根据它求 x k x_k xk的先验,再求 x k x_k xk的后验,作为这一步的最终结果。
因为高斯分布,均值代表了其状态估计值,协方差代表了其不确定性。
使用 x k x_k xk表示待求的随机变量, x ^ k \hat x_k x^k为其后验, x ‾ k \overline x_k xk为其先验。
- 先验: N ( x ‾ k , P ‾ k ) N(\overline x_k,\overline P_k) N(xk,Pk)
- 似然: N ( C k x k , Q ) N(C_kx_k,Q) N(Ckxk,Q)
- 后验: N ( x ^ k , P ^ k ) N(\hat x_k,\hat P_k) N(x^k,P^k)
1.2. 卡尔曼滤波器(KF)
已知的是先验和似然的分布表示, N ( x ‾ k , P ‾ k ) N(\overline x_k,\overline P_k) N(xk,Pk)与 N ( C k x k , Q ) N(C_kx_k,Q) N(Ckxk,Q)。同时已知后验与先验、似然的关系: N ( x ^ k , P ^ k ) N(\hat x_k,\hat P_k) N(x^k,P^k)= N ( x ‾ k , P ‾ k ) × N ( C k x k , Q ) N(\overline x_k,\overline P_k) × N(C_kx_k,Q) N(xk,Pk)×N(Ckxk,Q),要求后验的概率分布表达式。
根据高斯分布指数项系数配方可求得。
KF分为以下几步,(ノ*・ω・)ノ可得:
- 预测
根据 k − 1 k-1 k−1时的 x x x的后验,计算 k k k时 x x x的先验和似然。
推导得到先验的均值和协方差:
x ‾ k = A k x ^ k − 1 + u k , P ‾ k = A k P ^ k − 1 A k T + R \overline x_k=A_k \hat x_{k-1}+u_k,\overline P_k=A_k \hat P_{k-1}A_k^T+R xk=Akx^k−1+uk,Pk=AkP^k−1AkT+R - 更新
求卡尔曼增益:
K = P ‾ k C k T ( C k P ‾ k C k T + Q ) − 1 K=\overline P_kC_k^T(C_k\overline P_kC_k^T+Q)^{-1} K=PkCkT(CkPkCkT+Q)−1
更新后验:
x ^ k = x ‾ k + K ( z k − C k x ‾ k ) , P ^ k = ( I − K C k ) P ‾ k \hat x_k=\overline x_k+K(z_k-C_k\overline x_k),\hat P_k=(I-KC_k)\overline P_k x^k=xk+K(zk−Ckxk),P^k=(I−KCk)Pk
卡尔曼滤波器依据线性系统,没有近似,是线性最优无偏估计。
2. 非线性系统和扩展卡尔曼滤波器(EKF)
实际SLAM系统存在问题:
- 运动方程和观测方程非线性
- 高斯分布经非线性变换后,不再是高斯分布
因此需要进行近似,将非高斯分布近似成高斯分布。 在非线性系统中的KF即为EKF。其做法是:在某个点附近考虑运动方程和观测方程的 一阶泰勒展开,即其线性部分,然后按照KF进行(ノ*・ω・)ノ。
2.1. 线性化
k时刻,把运动方程( f f f),观测方程( h h h),在 x ^ k − 1 , P ^ k − 1 \hat x_{k-1}, \hat P_{k-1} x^k−1,P^k−1处线性化,即求在此处的偏导。
得到:
F = ∂ f ∂ x k − 1 ∣ x ^ k − 1 F=\frac {\partial f}{\partial x_{k-1}}\bigg |_{\hat x_{k-1}} F=∂xk−1∂f∣∣∣∣x^k−1
H = ∂ h ∂ x k ∣ x ‾ k H=\frac {\partial h}{\partial x_{k}}\bigg |_{\overline x_{k}} H=∂xk∂h∣∣∣∣xk
2.2. 扩展卡尔曼滤波器(EKF)
同样,分为两步:
- 预测
根据 x ^ k − 1 \hat x_{k-1} x^k−1,即上时刻后验,求出此时刻先验的概率分布形式(均值和协方差)。
x ‾ k = f ( x ^ k − 1 , u k ) , P ‾ k = F P ^ k − 1 F T + R k \overline x_k=f(\hat x_{k-1},u_k),\overline P_k=F\hat P_{k-1}F^T+R_k xk=f(x^k−1,uk),Pk=FP^k−1FT+Rk - 更新
根据先验,求出卡尔曼增益,再求出后验。
K k = P ‾ k H T ( H P ‾ k H T + Q k ) − 1 K_k=\overline P_kH^T(H\overline P_kH^T+Q_k)^{-1} Kk=PkHT(HPkHT+Qk)−1
x ^ k = x ‾ k + K k ( z k − h ( x ‾ k ) ) , P ^ k = ( I − K k H ) P ‾ k \hat x_k=\overline x_k+K_k(z_k-h(\overline x_k)),\hat P_k=(I-K_kH)\overline P_k x^k=xk+Kk(zk−h(xk)),P^k=(I−KkH)Pk
与KF对比,EKF可以看做在其基础上的改动:
- 将转移矩阵对变量的操作( C k x k C_kx_k Ckxk),改为转移函数操作(h(x_k))。
- 将转移矩阵( A , C A, C A,C),改为转移函数的偏导值( F , H F, H F,H)。
EKF给出的是,非线性系统单次线性近似的最大后验估计。
3. 局限
- 马尔可夫性的局限
- 一阶近似的局限
- 需要存储均值和方差,因为路标量很大,因此协方差矩阵很大。
三、 BA与图优化
BA(Bundle Adjustment):通过重投影不断优化估计的参数。
由于其稀疏属性,能够实现在线运行。
1. 投影模型和BA代价函数

此流程图即相机投影模型,也是观测方程的过程。注意,一个位姿只能观测到部分路标点。
观测方程: z = h ( x , y ) z=h(x,y) z=h(x,y)
其中:
- z z z: 像素坐标 ( u s , v s ) T (u_s,v_s)^T (us,vs)T
- x x x: 相机位姿,外参 R , t R,t R,t,对应李代数 ϵ \epsilon ϵ
- y y y: 三维坐标点 p p p
误差定义为:
e = z − h ( ϵ , p ) e=z-h(\epsilon,p) e=z−h(ϵ,p)
代价函数:
1 2 ∑ i = 1 m ∑ j = 1 n ∥ e i , j ∥ 2 = 1 2 ∑ i = 1 m ∑ j = 1 n ∥ z − h ( ϵ , p ) ∥ 2 \frac {1}{2} \sum_{i=1}^m\sum_{j=1}^n\|e_{i,j}\|^2=\frac {1}{2} \sum_{i=1}^m\sum_{j=1}^n\|z-h(\epsilon,p)\|^2 21i=1∑mj=1∑n∥ei,j∥2=21i=1∑mj=1∑n∥z−h(ϵ,p)∥2
即对所有的位姿和路标点组合下的观测误差求最小二乘。
对此最小二乘求解,相当于对位姿和路标同时调整,即BA。
2. BA的求解
自变量 x x x是所有待优化的变量,包括所有位姿和所有路标点(为了方便把位姿的李代数记成 e e e)。
x = [ e 1 , . . . , e m , p 1 , . . . , p n ] T = [ x c , x p ] x=[e_1,...,e_m,p1,...,p_n]^T=[x_c,x_p] x=[e1,...,em,p1,...,pn]T=[xc,xp]
x c = [ e 1 , . . . , e m ] T , 六 自 由 度 x_c=[e_1,...,e_m]T,六自由度 xc=[e1,...,em]T,六自由度
x p = [ p 1 , . . . , p n ] T , 三 自 由 度 x_p=[p_1,...,p_n]T,三自由度 xp=[p1,...,pn]T,三自由度
根据非线性优化,从初值开始,不断找增量 δ x \delta x δx,使最小二乘误差下降。
目标函数:
1 2 ∑ i = 1 m ∑ j = 1 n ∥ f ( x + δ x ) ∥ 2 = 1 2 ∑ i = 1 m ∑ j = 1 n ∥ e i , j + F i , j δ e i + E i , j δ p j ∥ 2 \frac {1}{2} \sum_{i=1}^m\sum_{j=1}^n\|f(x+\delta x)\|^2=\frac {1}{2} \sum_{i=1}^m\sum_{j=1}^n\|e_{i,j}+F_{i,j}\delta e_i+E_{i,j}\delta p_j\|^2 21i=1∑mj=1∑n∥f(x+δx)∥2=21i=1∑mj=1∑n∥ei,j+Fi,jδei+Ei,jδpj∥2
其中 F i , j F_{i,j} Fi,j是代价函数在当前状态下对相机姿态的偏导, E i , j E_{i,j} Ei,j是代价函数在当前状态下对路标位姿的偏导。
雅克比矩阵由这两者构成:
J = [ F E ] J=[F E] J=[FE]
在G-N方法下, H H H矩阵为:
H = J T J = [ F T F F T E E T F E T E ] = [ H 1 , 1 H 1 , 2 H 2 , 1 H 2 , 2 ] H=J^TJ=\bigg [\begin{matrix} F^TF & F^TE \\ E^TF & E^TE \end{matrix} \bigg ]=\bigg [\begin{matrix} H_{1,1} & H_{1,2} \\ H_{2,1} & H_{2,2} \end{matrix} \bigg ] H=JTJ=[FTFETFFTEETE]=[H1,1H2,1H1,2H2,2]
3. 稀疏性
考虑 e i , j e_{i,j} ei,j,为相机位姿 e i e_i ei下看到的路标 p j p_j pj的误差,其雅克比为:
J i , j ( x ) = ( 0 2 ∗ 6 , . . . , 0 2 ∗ 6 , ∂ e i , j ∂ e i , 0 2 ∗ 6 , . . . , 0 2 ∗ 3 , . . . , 0 2 ∗ 3 , ∂ e i , j ∂ p j , 0 2 ∗ 6 , . . . , 0 2 ∗ 6 ) = J_{i,j}(x)=\big (0_{2*6},...,0_{2*6},\frac {\partial e_{i,j}}{\partial e_i},0_{2*6},...,0_{2*3},...,0_{2*3},\frac {\partial e_{i,j}}{\partial p_j},0_{2*6},...,0_{2*6} \big )= Ji,j(x)=(02∗6,...,02∗6,∂ei∂ei,j,02∗6,...,02∗3,...,02∗3,∂pj∂ei,j,02∗6,...,02∗6)=
可见,这个 J i , j J_{i,j} Ji,j是由好多2x6和2x3的块组成的,并且只有第 i i i个2x6的块,和第 j j j个2*3的块是不为零的。它们对应着相机位姿 e i e_i ei和路标 p j p_j pj的偏导。
对应到 H H H,只有 ( i , i ) , ( i , j ) , ( j , i ) , ( j , j ) (i,i),(i,j),(j,i),(j,j) (i,i),(i,j),(j,i),(j,j)四个位置的块不为零。

因此整个 H H H可以分块,并拥有以下性质:
- H 1 , 1 H_{1,1} H1,1是对角阵,在 H i , i H_{i,i} Hi,i处是非零块。
- H 2 , 2 H_{2,2} H2,2是对角阵,在 H j , j H_{j,j} Hj,j处是非零块。
- H 1 , 2 H_{1,2} H1,2和 H 2 , 1 H_{2,1} H2,1的稀疏性不确定。
下面是一个更加直观表示其形状的图:
对于如下的位姿和路标关系:
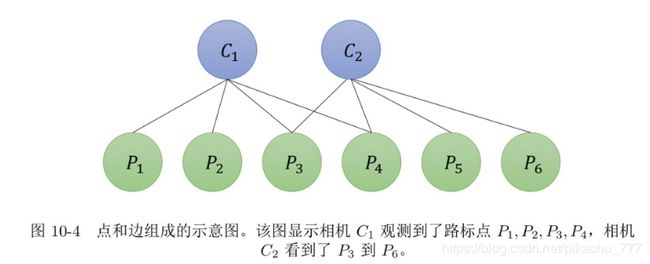
其 J , H J,H J,H形状为:

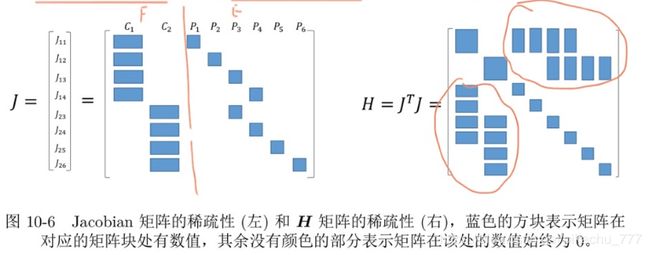
可见, H 1 , 2 H_{1,2} H1,2, H 2 , 1 H_{2,1} H2,1两部分的分布,和位姿与路标的邻接矩阵分布一致。

H矩阵的稀疏性质
其稀疏性可总结如下:
- 左上角 B B B为对角块矩阵,每个对角块元素维度与相机位姿维度相等(一般为6)。
- 右下角 C C C也是对角块矩阵,每个对角块元素维度与路标点维度相等(一般为3)。
- 左下 E E E和右上 E T E^T ET两块,结构与观测数据相关。
- 当路标点数量很大时, B B B很小, C C C很大, E E E和 E T E^T ET零散分布。

4. 边缘化
拥有 H H H后,目标是求解 H δ x = g H\delta x=g Hδx=g。
[ B E E T C ] [ δ x c δ x p ] = [ v w ] \bigg [\begin{matrix} B & E \\ E^T & C \end{matrix} \bigg ]\bigg [\begin{matrix} \delta x_c \\ \delta x_p \end{matrix} \bigg ]=\bigg [\begin{matrix} v \\ w \end{matrix} \bigg ] [BETEC][δxcδxp]=[vw]
使用边缘化方法消元:
- 消去 E E E,这样 H H H矩阵的第一行就与 E E E无关
- 进而第一行乘后的结果,与 δ x p \delta x_p δxp无关,这样就可以解出 δ x c \delta x_c δxc。
- 把 δ x c \delta x_c δxc带入,解出 δ x p \delta x_p δxp。
其中,主要计算两在于第二步。第三步中,由于 C C C是对角块,其逆易求,因此在计算过程中计算量减少。
此外,第二步消元后的方程系数记做 S S S,其稀疏性的意义为:非对角线上的非零矩阵块,表示了该出对应的两个相机变量之间存在着共同观测的路标点,称为共视。
从概率角度看,边缘化的意义是,先求了 x c x_c xc的边缘概率。
P ( x c , x p ) = P ( x c ) P ( x p ∣ x c ) P(x_c,x_p)=P(x_c)P(x_p|x_c) P(xc,xp)=P(xc)P(xp∣xc)
四、代码解读
1. g2o
g2o_bundle.cpp
包含程序入口,图的创建,优化参数的设置和优化流程。
SolveProblem流程:
BundleParams params(argc,argv)读入并解析command参数。BALProblem bal_problem(filename)读入数据,包括:
- 相机、路标、观测数
- 观测数据(相机-路标对,还有两个参数不知道是啥)
- 相机和路标的初始值
WriteToPLYFile存储原点云模型- 对初值添加噪声
- 建立优化问题具体形式,包括:
SetSolverOptionsFromFlags根据参数选择优化方法BuildProblem创建节点,包括相机位姿节点和路标节点BuildProblem创建边,为观测
- 进行优化
WriteToBALProblem存储优化后的新数据WriteToPLYFile存储优化后的点云模型
BALProblem
定义优化问题和图的参数,存储数据,实现了数据噪声添加、数据存储的功能。
g2o_bal_class.h
重写边和节点。包含:
- 9自由度的相机节点
- 3自由度的路标节点
- 边,定义代价函数、J矩阵。
2. ceres
和g2o流程一致,只是在solver部分不同,自己定义了损失函数。
另外代码有bug,直接运行存储的点云名字是final_ply…,应该改成final.ply