1. 哈希表(Hash tables)
在Python中,字典是通过哈希表实现的。也就是说,字典是一个数组,而数组的索引是经过哈希函数处理后得到的。哈希函数的目的是使键均匀地分布在数组中。由于不同的键可能具有相同的哈希值,即可能出现冲突,高级的哈希函数能够使冲突数目最小化。Python中并不包含这样高级的哈希函数,几个重要(用于处理字符串和整数)的哈希函数通常情况下均是常规的类型:
>>> map(hash, (0, 1, 2, 3))
[0, 1, 2, 3]
>>> map(hash, ("namea", "nameb", "namec", "named"))
[-1658398457, -1658398460, -1658398459, -1658398462] 如果在Python中运行 hash('a') ,后台将执行 string_hash()函数,然后返回 12416037344 (这里我们假设采用的是64位的平台)。
如果用长度为 x 的数组存储键/值对,则我们需要用值为 x-1 的掩码计算槽(slot,存储键/值对的单元)在数组中的索引。这可使计算索引的过程变得非常迅速。字典结构调整长度的机制(以下会详细介绍)会使找到空槽的概率很高,也就意味着在多数情况下只需要进行简单的计算。假如字典中所用数组的长度是 8 ,那么键'a'的索引为:hash('a') & 7 = 0,同理'b'的索引为 3 ,'c'的索引为 2 , 而'z'的索引与'b'相同,也为 3 ,这就出现了冲突。
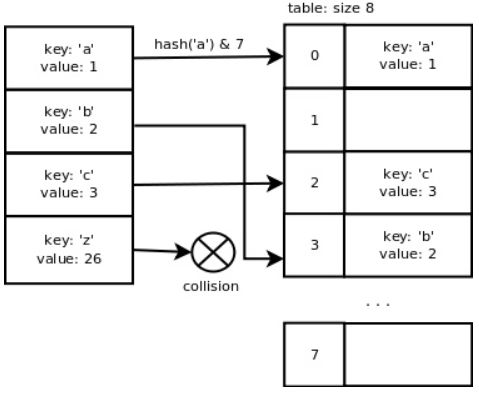
可以看出,Python的哈希函数在键彼此连续的时候表现得很理想,这主要是考虑到通常情况下处理的都是这类形式的数据。然而,一旦我们添加了键'z'就会出现冲突,因为这个键值并不毗邻其他键,且相距较远。当然,我们也可以用索引为键的哈希值的链表来存储键/值对,但会增加查找元素的时间,时间复杂度也不再是 O(1) 了。下一节将介绍Python的字典解决冲突所采用的方法。
2. dict与set的实现原理
dict与set实现原理是一样的,都是将实际的值放到list中。唯一不同的在于hash函数操作的对象,对于dict,hash函数操作的是其key,而对于set是直接操作的它的元素,假设操作内容为x,其作为因变量,放入hash函数,通过运算后取list的余数,转化为一个list的下标,此下标位置对于set而言用来放其本身,而对于dict则是创建了两个list,一个list该下表放此key,另一个list中该下标方对应的value。
其中,我们把实现set的方式叫做Hash Set,实现dict的方式叫做Hash Map/Table(注:map指的就是通过key来寻找value的过程)
3.hash碰撞及其解决方法
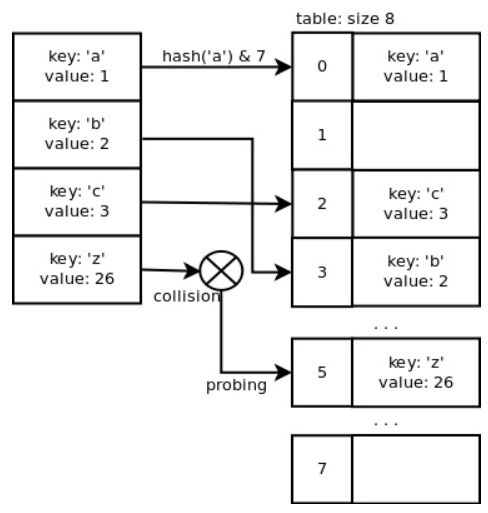
(1)开放寻址法(Open addressing)
开放寻址法是一种用探测手段处理冲突的方法。在上述键'z'冲突的例子中,索引 3 在数组中已经被占用了,因而需要探寻一个当前未被使用的索引。增加和搜寻键/值对需要的时间均为 O(1)。
![]()
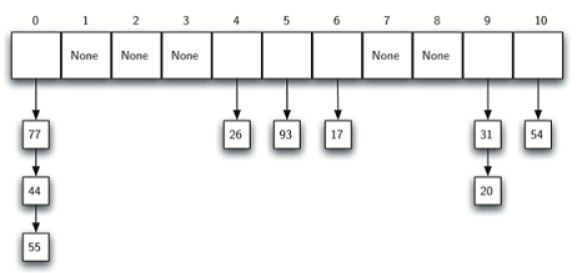
(2)拉链法
原理图如下,其实就是将发生有冲突的元素放到同一位置,然后通过“指针“来串联起来
参考文献:
【1】深入 Python 字典的内部实现
【2】python 下的数据结构与算法---8:哈希一下【dict与set的实现】