信息检索导论读书笔记(三):词典及容错式检索(通配符查询、拼写校正)
假设给定倒排索引及查询,首先应确定查询词项是否在词汇表中,如果在应该返回词项对应的倒排记录表的指针。查找操作通常采用词典的经典数据结构。实现这种数据结构有两种方式:哈希表及搜索树。关于两者的定义在此不再赘述。哈希表除了需要解决哈希冲突的问题,在查询词存在轻微变形时也无法进行查询,并且由于词汇表往往是不断增长的,为当前需求设计的哈希函数可能过一段时间就不再适用。因此通常使用搜索树的查询方式。
搜索树也有很多种,词典搜索中普遍使用B树,B树的定义建议翻看数据结构教材了解其增删改查的方法。
通配符查询:
通配符查询是一种容错方式,当用户不确定一个词正确拼写形式,可以使用通配符 * 代替某些字符。
单个通配符查询:
对于只在词项末尾出现的通配符查询,可以使用B树进行查询,并返回所有匹配到通配符之前的词项对应的倒排记录表。对于只在词项开头出现通配符的词项,可以使用反向B树进行查询。通过将B树和反向B树结合起来使用可以处理只有一个通配符并存在于词项中间的查询,分别对通配符之前和之后的字符串使用B树和反向B树查询之后求交集即可。
一般通配符查询:
对于一般的通配符查询,需要对原本的倒排索引进行改进,这里有两种改进方式:轮排索引和 k-gram 索引。
轮排索引:
每个词项结尾引入一个符号$,用于表示此项结束,然后构建一个轮排索引,对每个扩展词项的旋转结果都构造一个指针来指向原始词项,例如下图解释了对hello的构造方法。
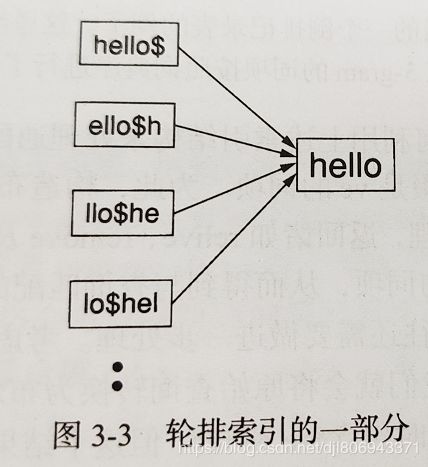
其具体使用方式,比如查询 m*n ,实际查询为 m*n$,可以转为查询 n$m* 对应的倒排索引表;查询 fi*mo*er,实际查询为 fi*mo*er$,则可以转为查询 er$fi* ,查询时可以采用B树,再从查询结果中排除不包含mo的词项即可。轮排索引的缺点就是会使词典变得非常大,因为它需要保存每个词项所有的旋转结果。
k-gram索引:
在每个单词开头和结尾引入一个符号$,一个k-gram代表由k个字符组成的序列,比如对castle建立3-gram索引,应该包含$ca、cas、ast、stl、tle、le$,将这些所有k-gram构成词项词典。
具体使用时,比如查询re*ve,实际查询$re和ve$,结果取交集。但这样查询结果可能有问题,比如red*(实际查询$re与red),根据上述步骤查询时retired也会被作为结果返回,但实际不符合用户查询要求,因此还须引入一个后过滤步骤,进行与查询词的字符串比对。
对于上述这些搜索功能,很多搜索引擎都提供了支持,但是往往会将这些功能隐藏在一个大部分用户从不访问的截面(如高级搜索)。如果把这些功能暴露在一般搜索界面,用户常常会受到诱导而使用这些功能,即便在他们不是特别需要的时候(比如输入a*进行查询),这样会大大增加搜索引擎的负担。
拼写校正:
拼写校正也是一种容错方式,比如当用户输入carot时,实际可能想返回包含carrot的文档。对于大多数拼写校正算法,存在以下两个基本原则:
- 对于一个拼写错误的查询,在其可能的正确拼写中,选择距离“最近”的那个,这就要求对查询结果有距离或者邻近度的概念。
- 当两个正确拼写查询邻近度相等或相近时,选择更常见的那个。对于更常见的定义可以是在文档中出现频率更高,也可以是对所有用户查询统计查询频率更高。
具体的拼写校正思路有两种:一种是词项独立(isolated-term)的校正,两一种是上下文敏感(context-sensitive)的校正。从字面意思也可以知道,词项独立校正只对单个查询词校正,所有查询词的校正是相互独立的。而上下文敏感则是根据上下文对词项进行校正。
词项独立校正:
两种词项独立校正方法:编辑距离方法、k-gram重合度法
编辑距离:
对于两个字符串s1与s2,两者编辑距离定义为:将s1转换成s2的最小编辑操作数,这些操作包含三种:将一个字符插入字符串、从字符串中删除一个字符、将字符串中的一个字符替换成另外一个字符。实际上还可以进一步推广,为三种不同操作设置不同的权重。
我们知道, 可以在O(|s1|×|s2|)的时间复杂度内计算两个字符串s1、s2之间的编辑距离(也是一个非常经典的动态规划算法题,LeetCode72题,建议自己去看下,难度是hard)。
上述求两个字符串编辑距离只是拼写校正中的基础,我们需要从给定字符串集合V中找到与查询字符串q编辑距离最小的字符串,如果使用穷举的搜索方法计算q与V中每个字符串的编辑距离开销很大,因此实践中使用启发式方法提高查找效率。
最简单的启发式方法是将搜索限制在与查询词具有相同首字母的字符串上,即希望查询的拼写错误不会出现在第一个字符上。更复杂的做法是结合轮排索引,将字符串 q 的所有旋转结果集合都通过遍历B树访问轮排索引进行查找。
k-gram重合度法:
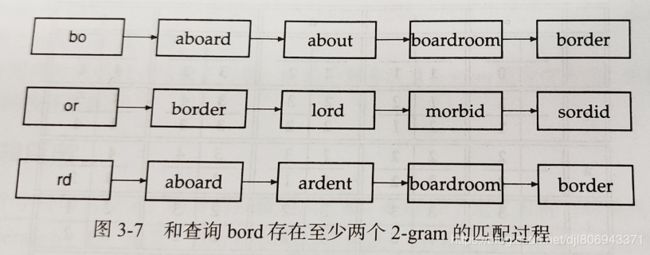
k-gram重合度法是借助k-gram索引返回与q具有较小编辑距离的词项。利用k-gram索引查找与查询词具有很多公共k-gram的词项。只要对“具有很多公共k-gram”进行合理定义,就可以对查询词进行校正。上述查找实际上是对查询字符串q中k-gram的倒排记录表进行单遍扫描的过程,这种通过线性扫描并立即合并倒排记录表的做法十分简单,只要待匹配词包含查询词q中固定数目的k-gram即可。如下图查询bord时,如果设定至少匹配两个2-gram则可以返回aboard boardroom border。
上述算法还是存在缺陷,比如boardroom这种不可能是bord的正确拼写形式的词也会被返回,因此需要对返回此项与查询词q之间更精细的重叠度进行计算以修正算法的结果。比如Jaccard系数法。Jaccard系数计算公式为![]() ,这样可以对返回结果快速计算该系数,只有Jaccard系数超过设定的阈值才会被返回。其中分子是查询时就可以得到的,分母则只需要知道词项的长度就可以计算:查询词 k-gram 个数 + 词项 k-gram 个数(根据长度计算)- 分子即可。
,这样可以对返回结果快速计算该系数,只有Jaccard系数超过设定的阈值才会被返回。其中分子是查询时就可以得到的,分母则只需要知道词项的长度就可以计算:查询词 k-gram 个数 + 词项 k-gram 个数(根据长度计算)- 分子即可。
基于发音的矫正:
还存在一种拼写错误的原因在于用户输入了一个和目标词项发音相似的查询,尤其是涉及人名查找。针对这种拼写错误,基本思路是:对每个词项进行一个语音哈希操作,发音相似的词项被映射为同一值。这一类通过语音哈希的方法通常称为 soundex算法。其构建步骤如下:
- 将所有词项转变为四字符的简化形式,基于这些简化形式建立原始词项的倒排索引,该倒排索引被称为soundex索引
- 对查询词进行同样操作
- 在soundex索引中进行匹配搜索
不难看出,上述算法构建过程中,最核心的部分是对词项进行四字符形式简化。一种普遍使用的转换方法如下:
- 保留词项首字母
- 将后续所有的A、E、I、O、U、H、W 及 Y 转换为 0
- B、F、P、V 转换为1;C、G、J、K、Q、S、X、Z 转换为2;D、T转换为3;L转换为4;M、N转换为5;R转换为6
- 将连续出现的两个同一字符转换为一个字符直至不存在这种情况
- 在结果字符串中剔除0,结尾补足0,然后返回前四个字符
通过这种方式转换得到的四字符由首字母和三个数字组成。