Hadoop-模拟搭建用户行为日志采集系统分析
一. kafka应用流程示意
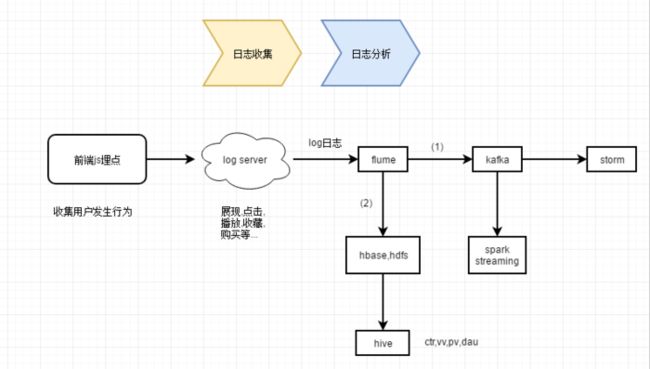
1. 前端js埋点,就是调用后端提供的对应接口.接口请求示例如下:
http://pingserver.com?itemid=111&userid=110&action=show&...为了保证轻量级,冰法度高,前端js埋点向后端异步发送的请求不需要关注返回状态,只负责调用即可
2. flume监听log日志,将实时增加的log日志通过flume管道注入kafka中,接下来可以有storm或spark streaming进行实时流处理;
3. 方向(1)中应用:storm,spark streaming更偏重于业务处理及数据挖掘;4. 方向(2)中应用:hbase,hive更偏重于行为日志分析,比如统计pv,uv,vv,ctr,dau等.
二. 搭建日志采集系统log server流程图
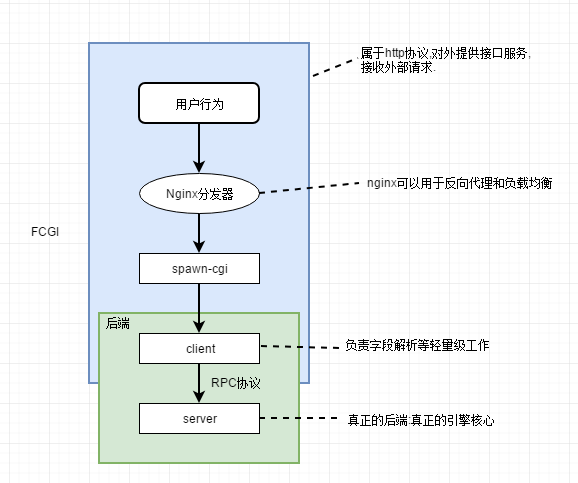
上图,就是一个Log Server实现的最简单的流程图.
1. Nginx分发器:上面提到了前端js埋点请求,要求速度要快,并发度要高,所以这里使用了Nginx分发器作为web server,实现反向代理与LB(负载均衡);
2. Spawn-cgi: 上图只是示例提供一个server服务的场景,同样也可以不同节点上,提供相同的服务,用nginx实现负载均衡,以能提供更快更高可用的服务.
Spawn-cgi的功能: 就是提供了一个网关接口,它可以轻松快速的实现对外暴露server服务的功能,并能使底层的服务变成一个守护进程;
它的请求走的fcgi协议,这种协议更加适合外部请求,因为http请求很容易受到攻击;
3. Thrift RPC: 在定义接口规范之后,能够帮助我们快速的生成client和server代码,并能帮助我们实现服务之间的解耦:
- client只负责字段的解析等轻量级的工作;
- server才是真正的引擎核心,我们可以在这里实现自己的业务处理逻辑.
使用Thrift RPC生成的client和server之间的通信,走的RPC协议,这种协议有如下好处:
- 跨语言,支持多种语言去生成client和server代码,c++,Python,java等;
- 保证数据的安全,相比http协议更不容易受到外部攻击;
- 速度快,性能好,比如用c++生成代码,实现效果性能更好,速度更快,更能应对高并发的处理请求;
RPC协议更加适合底层内部的请求,所以设计上后端一般都是使用RPC协议.
另外,RPC的两端client和server只要遵循RPC协议和定义的scheme接口通信规范,两端可以使用不同的开发语言.
4. 上面的client server中server,并不只是一种简单的服务,它可以由多个server通过RPC协议构成,比如下面搭建推荐系统,如下图所示:
三. 模拟日志收集系统的相关技术功能梳理
1. Thrift RPC:在定义接口通信规范后,可以用Thrift命令快速生成server和client代码,完成最基本的C/S架构;这种生成代码的方式,可以帮助我们实现服务之间的解耦,client只负责字段的解析等轻量级的工作,而server才是真正的处理引擎;
在server里面,我们可以实现自己的业务处理逻辑.通过glogs可以将收集到用户行为日志快速高效的写入log文件中.
2. Spawn-CGI: 通过cgi提供的网关接口,可以将自己用thrift rpc的server服务提供给外部.
简单的可以理解为提供了一种代理,可以在非应用程序所在的机器上操作应用程序.
3. Nginx分发器: 就是web server,用于分发用户的请求,实现反向代理与负载均衡;通过它可以将用户的js埋点请求分发给我们的server应用程序去处理;
--------------------上面的部分,基本就实现了模拟日志收集系统的搭建---------------------
5. Flume + Hbase/Hive : 用于用户行为日志分析;
6. Flume+Kafka+Storm/Spark Streaming :用于实时流处理的数据挖掘;