Online Tracking by Learning Discriminative Saliency Map with Convolutional Neural Network
《Online Tracking by Learning Discriminative Saliency Map with Convolutional Neural Network》
本文提出了一个通过用CNN学习可区分性的显著图的在线视觉跟踪算法。给定一个在大规模图片数据集上在线下预训练的CNN,本文的算法将网络的隐含层的输出当做是特征描述子,因为他们在各种各样的视觉识别问题上表现出非常好的表达能力。这些特征通过使用一个在线SVM被用来学习一个可区分性的目标外观模型。此外,作者构想了一个特定目标的显著图,通过在SVM的指导下反向传播CNN特征,最后得到每一帧的最终的跟踪结果,它是基于外观模型和显著图谱生成和构造的。因为显著图谱能够有效地可视化目标的空间结构,所以他提高了目标定位的精度,并且使我们能够实现像素级的目标的语义分割。
本文作者提出一种新的跟踪算法,它是基于一个预训练的CNN来表达目标,这个CNN网络他最初是为了大规模图像分类任务而训练的。在CNN的隐含层的顶端,作者添加了一个额外层,这一层是一个在线的SVM,它是用来学习目标对象的外观,以便很好的将它从背景中区分开来。这个通过SVM学习的模型被用来计算一个特定目标的显著图谱,是
通过反向传播和目标对象相关的信息到输入层来完成的。
然后利用特定目标的显著图谱来得到生成目标外观的模型(滤波器),通过理解目标对象的空间结构来进行跟踪。
本文的几点贡献:
1、尽管目前基于CNN的跟踪算法都试图用一个在线的方式来学习网络,但是我们的算法采用了一个预训练的CNN来表达目标对象的一般特征,并且取得了非常出色的效果。
2、作者提出了一种构造特定目标显著图的技术,在训练CNN的反向传播误差的时候,它是通过反向传播只和目标对象相关的特征,这种做法克服了现有方法的一些缺陷(限制),只是可视化和预定义类别相一致的显著图。这个技术也是我们能够获得像素级的目标分割。
3、我们在线学习了一个简单的特定目标外观的滤波器,并且将它运用到显著图中,这个策略提高了目标的定位性能,这跟CNN特征的平移不变性的性能是一样的。
Overview of Our Algorithm:
本文的跟踪算法采用了一个预训练的CNN来表示目标。对于每一帧视频,首先我们要采取一些候选样本,这些候选区域是在上一帧视频中目标对象的周围采样的,得到这些图像的观察值后,我们用预训练的CNN来提取这些采样图像的特征描述。我们发现,这些从CNN提取到的语义信息特征是非常有效的,它能够成功的处理结构和光照变化。然而这些特征表示由于CNN的pooling操作会丢失掉目标的一些空间信息,这对于目标跟踪是不太令人满意的,因为空间信息对于目标的精确定位是非常有效的。
为了充分利用CNN特征的表示能力来保存目标的空间信息,我们采用指定目标对象的显著图作为我们的观察值来做跟踪,这些显著图是通过反向传播指定目标对象的CNN特征信息到输入层而产生的。类别特定的显著图是通过反向传播相应的信息到特定的标签来可视化感兴趣的区域来建造的。因为视觉跟踪问题属于一个任意类别的问题,他的类别是不知道的,目标类别的模型是很难预训练到的。
因此,我们采用一个在线的SVM,它能够利用从CNN模型学习到的特定目标的特征来从背景中区分出目标对象,通过在线SVM学习到的特定目标的信息被看做是类别信息。SVM能够区分每一个样本,我们计算每一个正样本显著图,通过沿着预训练的CNN模型反向传播他的CNN特征到输入层,整个过程是在SVM的指导下进行的。每一个显著图会会将从背景中区分得到的目标区域高亮。这个特定目标显著图减轻了CNN特征做视觉跟踪的限制,通过提供目标对象的重要的空间结构特征。
接下来,跟踪算法可以表述为一个顺序的贝叶斯滤波框架,在跟踪的时候用特定目标显著图作为观测值。然后一个产生式的外观模型通过随着时间的推移累加目标的观测值(特定目标的显著图)来构造,它能够揭示目标的有意义的空间构造(例如形状和局部)。然后每一帧的一个密集的似然图谱可以有效的通过卷积来计算,这个卷积操作是发生在特定目标的显著图和产生式外观模型之间的。
本文的算法利用了在线SVM的可区分性的性能,他帮助我们生成一个特定目标显著图谱。此外,作者利用显著图谱来构建产生式外观模型,通过顺序贝叶斯滤波来执行跟踪。这样就很自然的结合了判别式和产生式方法。
3.1 预训练CNN来提取特征描述子
为了表达目标的外观,作者采用了CNN,它是在一个大规模图片数据集上预训练的。这个预训练的模型对于在线跟踪是非常有用的,因为他并不是直接的收集大量的训练数据。在这篇文章中,作者选用的是R-CNN,当然其他的CNN模型也是可以选择的。对于整个网络结构,作者选择的是第一个全连接层的输出,因为他们更趋向于捕获目标对象的一般特征,并且在很多其他领域表现出很好的泛化性能。
对于一个候选的目标Xi,CNN网络将它对应的图片的观测值Zi作为输入,从第一个全连接层返回
 作为Xi的特征输出。对于每一个CNN特征向量
,
作者利用SVM将Xi分为正样本或者负样本。
作为Xi的特征输出。对于每一个CNN特征向量
,
作者利用SVM将Xi分为正样本或者负样本。
3.2 特定目标显著图谱的估计
对于目标跟踪问题,首先计算候选样本通过CNN得到的特征表达的SVM得分,然后将他们分为目标或者是背景。基于这些信息,一个很自然的选择就是简单的选择具有最高得分的最优样本来完成跟踪。计算得分的公式如下:
然而,这个方法在目标的精确定位上是有局限的,因为目标的空间结构会因为空间的pooling操作有损失。
为了解决精确定位的问题而且还要用到CNN的有效的特征,作者提出了特定目标的显著图谱,它能够将图片中具有目标区分性的区域标记出来(高亮)。对于一个给定的图像I,特定类别的显著图谱是类别得分
 关于图像I的梯度,公式表述为:
关于图像I的梯度,公式表述为:

显著图是根据反向传播来构造的。

然后,上面的公式【1】就可以利用链式规则用下面的公式【2】来计算:

很直观的,和类别C越相关的像素对
 的影响越大,这就一意味着在这些像素区域周围的地方在显著图上会有更高的值。
的影响越大,这就一意味着在这些像素区域周围的地方在显著图上会有更高的值。
当我们计算目标跟踪的显著图的时候,我们加上特定目标信息而不是类别信息。为了达到目的,作者采用SVM权重向量W=(w1,w2,...,wn)T,这是在线学习的,用来区分目标和背景。因为最后一个全连接层相当于一个在线SVM,网络的最后两层的输出如下:
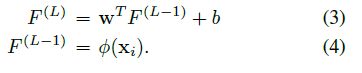
候选区域Xi的渐变映射如下:

Zi是Xi对应的图像的观测值。
作者只选择和W中正的权重维度相同的特征而不是所有来生成特定目标的显著图谱。注意,
 中的每一个元素都是正值,因为在CNN学习中使用了ReLU操作。然后我们就得到了特定目标的特征
中的每一个元素都是正值,因为在CNN学习中使用了ReLU操作。然后我们就得到了特定目标的特征
 ,计算公式如下:
,计算公式如下:

然后,关于图像观察值的特定目标特征
的梯度就可以用如下的式子得到:
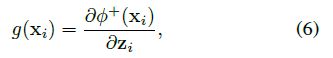
因为这个梯度仅仅使用了和特定目标信息正相关的特征
来计算的,所以从背景中区分目标的像素值在
 中
将会较大。
中
将会较大。
特定目标显著图M是通过聚合样本的
来得到的,这些样本在图像空间有一个正的SVM得分。因为
使用样本观测值Zi来定义的,所以我们首先将它投影到图像空间;投影后的结果表示为
 。然后,就会得到特定目标的显著图,通过渐变映射
相对应的正样本中像素值较大的位置。公式表述如下:
。然后,就会得到特定目标的显著图,通过渐变映射
相对应的正样本中像素值较大的位置。公式表述如下:
P表示像素的位置。我们抑制背景图像的错误的激活,在我们聚集样本的渐变映射图的时候,只聚集正样本。
3.3 通过显著图来定位目标区域
Mt表示t时刻的特定目标的显著图,观测值
Xt表示t时刻的状态


Ht表示的是目标外观模型。

取M个,算均值
通过计算得到目标区域的外观

3.4 通过在线SVM更新判别模型
作者采用一个在线SVM来学习目标的判别模型。作者将SVM看作是一个只有一个节点的全连接层,它能在一个单通道里提供一个快速精确的学习一个递增的模型。
给定一系列的具有关联标签的样本,
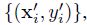 是从当前的训练结果中获取到的,我们希望更新SVM的权重W。新样本的标签是通过如下式子得到的:
是从当前的训练结果中获取到的,我们希望更新SVM的权重W。新样本的标签是通过如下式子得到的:
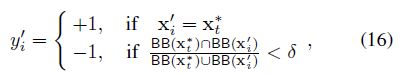
在谈论在线SVM之前,作者首先简单的回顾了一下线下学习算法的最优化过程。给定的训练样本
 ,一个线下的SVM学习权重向量
,一个线下的SVM学习权重向量
 通过解决一个二次凸优化问题。SVM对偶形式的目标方程给定如下:
通过解决一个二次凸优化问题。SVM对偶形式的目标方程给定如下:
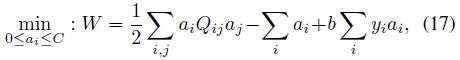
其中的
 表示一个拉格朗日乘数,b表示偏置。在我们的跟踪算法中,核函数是通过两个CNN特征之间的内积来定义的
表示一个拉格朗日乘数,b表示偏置。在我们的跟踪算法中,核函数是通过两个CNN特征之间的内积来定义的
 。在在线跟踪时,他并不是直接的解决传统的QP的优化问题,因为训练数据是顺序给出的,并不是一次给定。而增量SVM恰好就可以解决这个问题。其中关键的一点就是在所有的例子中保持KKT条件,当我们用一个新的样本来更新模型的时候,这样它就保证了有一个精确解。KKT条件是最优解的一个必要条件:
。在在线跟踪时,他并不是直接的解决传统的QP的优化问题,因为训练数据是顺序给出的,并不是一次给定。而增量SVM恰好就可以解决这个问题。其中关键的一点就是在所有的例子中保持KKT条件,当我们用一个新的样本来更新模型的时候,这样它就保证了有一个精确解。KKT条件是最优解的一个必要条件:

通过【18】的条件,每一个训练样本都属于如下三类中的一类:E1表示的是支持向量在最大间隔上,E2表示的是支持向量在最大间隔内,E3表示的非支持向量。
给定第K个样本,增量SVM来估计拉格朗日乘数
 ,同时要保持所有钱K-1个样本满足KKT条件。简而言之,就是先将
的值初始化为0,然后通过迭代增加它的值来更新。在每一次迭代中,算法来估计最大可能的增量
,同时要保持所有钱K-1个样本满足KKT条件。简而言之,就是先将
的值初始化为0,然后通过迭代增加它的值来更新。在每一次迭代中,算法来估计最大可能的增量
 ,并且现存的所有样本保证KKT条件。这个迭代过程将会停止,当第K个样本变成了支持向量或者至少一个现存的样本的所属的类别发生了变化。我们可以很容易的推广这个在线更新的过程,当多个样本提供给我们作为一个新的训练数据。对于一个新的、更新的拉格朗日乘数,权重向量W可以通过如下式子得到:
,并且现存的所有样本保证KKT条件。这个迭代过程将会停止,当第K个样本变成了支持向量或者至少一个现存的样本的所属的类别发生了变化。我们可以很容易的推广这个在线更新的过程,当多个样本提供给我们作为一个新的训练数据。对于一个新的、更新的拉格朗日乘数,权重向量W可以通过如下式子得到:

为了更加有效,我们在跟踪的过程中只维持一个固定数量的支持向量。