论文翻译DCFEE:基于自动标注数据的文档级中文金融事件提取系统
翻译文章前简单的介绍下事件抽取:
事件抽取是信息抽取领域的一个重要研究方向,主要目的是从含有事件信息的非结构化的自然语言描述的文本中抽取出事件信息并且以结构化的形式表示出来。通常一个完整的事件可以用5W1H表示出来。who(事件的主动实施者),whom(事件的被动接受者),what(具体干什么),when(何时),where(何地),how(如何做的). what一般由谓语动词体现,在事件中是触发词,who,whom,when,where是事件的四个要素。一个事件的语义可以描述为
When who do what to whom in where
摘要
我们提出了一个事件提取框架,从金融新闻的文章中发现事件描述并且提取事件。到目前为止,基于监督学习模式的方法在公开数据集(ACE2005,KBP2015)上取得较好的表现。这些方法极大的依赖于手工标注的训练数据。然而,在一些特殊的领域,例如:金融、医学、司法领域等,由于数据标注过程的高昂代价导致这些领域没有足够的标注数据可供训练。此外,大部分现存的方法都集中于从一个句子中提取事件,但是在一篇文章中,一个事件通常是由多个句子所表达的。为了解决这些问题(指的是第一没有足够的标注数据,第二从仅仅一个句子中提取事件不合理),我们提出了DCFEE,这个系统可以自动的生成大规模的标注数据(解决了问题一)而且从整个文章中提取事件(解决了问题二)。实验结果表明了DCFEE的有效性。
介绍
事件抽取在NLP领域是一个有挑战性的任务,目的是从文本中发现事件描述,提取含有事件触发词的事件以及事件参数。(event mention 事件描述,描述一个事件的句子,这个句子中包含这个事件类型所需要的触发词和事件参数)
(event trigger 事件触发词,能够最明显的表达一个事件发生的那个单词,通常是动词或名词)
(event argument 事件参数指的是在事件中处于具体角色的实体)。

例如图1。一个事件抽取系统要能够发现由冻结(frozen)这个单词所触发的股权冻结事件并且提取出五个不同角色的事件元素,这些角色包括:股东名、冻结股票的数目、冻结机构、冻结起始日期、冻结结束日期。这五个元素就是长富瑞华、520000股、大连市人民法院、2017年5月5日、3年。从文本中提取事件实例在构建像信息抽取,智能问答等NLP系统中有重要作用。最近已经有研究者构建了像EventRegistry,Stela等英文事件抽取系统。然而在金融领域,特别是中文,还没有这类的事件抽取系统。
金融事件能够帮助用户获得竞争者的战略,预测股票市场并且做出正确的投资决定。例如,股权冻结事件的发生对公司会有很坏的影响,此时股东应该及时作出决定避免损失。在商业领域,由公司所公布的官方通告代表着重要事件的发生,例如股权冻结,股票交易事件等。所以从这些通告中发现实体描述并且提取事件是很有价值的。然而在中文金融实体抽取领域有两种挑战:
- 缺乏数据: 大部分的实体抽取方法通常采用监督学习的范式,而这种方式极大的依赖于精心设计的人工标注数据,但是在中文金融领域没有标注的数据。
- 文档层面的事件抽取: 当前大部分事件抽取的方法都是集中于句子级别。但是一个事件通常是由在文档中的多个句子表示。在这篇文章中的金融领域数据集,有91%的情况是一个事件的事件元素分布在不同的句子中。如图1所示,E1,E2共同描述股权冻结事件。
为了解决这两个问题,我们提出了名叫DCFEE的框架,这个框架可以从自动标注的训练数据中提取出文档级别的事件。远程监督已经被证实可以为事件抽取生成标注数据,我们利用远程监督生成大规模的标注数据。我们利用序列标注模型自动的提取句子级别的事件。接下来,我们提出了一个关键事件发现模型和一个元素填充方案从文章中提取整个事件。
这篇文章的贡献总结如下:
- 我们提出的DCFEE框架可以自动的生成大量的标注数据并且从金融通告中提取文档级的事件
- 我们为事件抽取引入了一种自动标注数据的方法并且为构建中文金融事件数据集给出了一些技巧。我们提出的文档级别事件抽取系统主要依靠与一个序列标注模型,一个关键事件发现模型和一个事件元素补全方案。实验结果显示了这个系统的有效性。
- DCFEE系统已经被成功的构建为一个在线应用,可以快速从金融文档中提取事件。

2 方法
图二描述了我们提出的DCFEE框架的架构,主要包括下面两部分:数据生成,利用远程监督自动的从整篇文章中给事件描述做标签并且对事件描述注释触发词和事件元素;EE系统,主要包含句子级别事件抽取(SEE)和文档级别事件抽取(DEE),SEE是由句子层面上标注的数据供应,DEE是由文档层面上标注的数据供应。在下一章,我们会简短的描述标注的数据生成和EE系统的架构
2.1 数据生成

图三描述了基于远程监督方法的标注的数据生成过程。在这一章节中,我们会先介绍我们所使用的数据源。然后我们描述自动标注数据的方法。最后我们会给出一些可以用来提高标注的数据质量的一些技巧。
数据源:
自动生成数据需要两种数据源:包含着大量的结构化事件数据的金融事件知识库和含有事件信息的非结构化文本数据。在这篇文章中所用到的金融事件知识库是包含九种常见的金融事件类型的结构化数据,这些数据以表格式存储。这些结构化的数据包含着由金融学专家从文档中摘要出来的关键事件元素。用一个股权质押事件作为例子,如图三左侧,关键事件元素包括股权持有者名称,质押机构,质押股票数量,质押起始时间和结束时间。非结构化的数据来源于公司发布的官方通告,以非结构化的形式存储在网页中。我们从搜狐的证券网站上获得这些数据。
数据生成的方法:
注释数据由两部分组成:通过标注事件描述中的事件触发器和事件元素来产生句子级别的数据;通过从文档中标注事件描述来生成文档级别的数据。现在的问题是如何找到事件触发词。那些符合结构化的事件知识库中的事件元素和事件描述可以从大规模的文档通告中总结归纳出来。远程监督在关系抽取和事件抽取领域已经被证明出其有效性。受到远程监督的启发,我们假定包含有最多的事件元素并且由一个具体的触发词所驱动的句子最有可能是一篇文档中的实体描述。在这个事件描述中的事件元素会扮演对应的事件中的角色。对于每一个金融事件类型,我们构建事件触发词的一个字典,例如在股权冻结事件中的冻结以及股权质押事件中的质押。所以那些来自文档通告中的触发词可以通过查询预先定义的字典被自动的标记出来。通过这些预处理,结构化的数据就可以被映射到文档通告中的事件元素。因此我们就可以自动的识别出事件描述以及将包含在这个事件描述中的事件触发词和事件元素打上标签,这样就生成了句子级别的数据,如图3的底部。然后,这个事件描述就被自动的标记为正类而在这篇文档中的其它句子被标记为负类,以此来构建文档级别的数据,如图3的右侧。文档级别的数据和句子级别的数据共同形成实体抽取系统所需要的训练数据。
技巧:
实际上,在数据标注的过程中有很多的挑战:金融通告和事件知识库中知识的一致性;事件元素描述的模糊性和缩写简写问题。有一些技巧可以用来解决这些问题,如图3的例子。
- 减小搜索空间:候选文档通告的搜素范围可以通过检索诸如公开的日期和通告中股票的编码等重要事件元素来减小。
- 规则化表示:更多的事件元素可以通过规则的表示被匹配到以此来提成标注数据的召回率。例如隆鑫控股有限公司在金融事件知识库中,但是在句子中的是隆鑫控股。我们可以解决这个问题通过规则化表示然后把隆鑫控股标注为一个事件元素。
- 规则:一些任务驱动的规则可以被用来标注数据。例如我们可以通过计算质押终止日期和质押起始日期之间的差值从而标记12月为一个事件元素(角色是质押终止日期)。
2.2 事件抽取

图4描述了事件抽取系统的全局架构,主要涉及接下来的两部分:句子级别的事件抽取,目的是从一个句子中提取事件元素和事件触发词;文档级别的事件抽取,目标是从基于一个关键事件发现模型和一个元素补全方案的整篇文档中提取事件元素。
2.2.1 SEE
我们把SEE看做一个序列标注任务,并且训练数据是由句子层面的标注好的数据提供。句子是用BIO格式表示的,意思是对于每一个字符(包括事件触发词,事件元素和其他的单词),如果这个字符是一个事件元素的开始,那么就被标记为B-label,在中间就标记为I-label。如果不是事件元素,那么就标记为O。(如图4所示,质押这个单词是触发词,所以质被标记为B-TRI,押被标记为I-TRI)。在最近几年,神经网络由于它能从文本表示中自动的学习特征,所以已经被广泛的应用在大部分的NLP任务中。并且BiLSTM-CRF这种模型在一些典型的如词性标记,实体识别等NLP任务上可以达到SOTA的性能(就是最好的性能)。由于双向LSTM,模型可以有效的利用过去和未来的输入特征,由于条件随机场,模型可以使用句子层面的标注信息。(如果没有CRF,那么模型在输出层预测标签时各个标签之间是独立预测的,第一个预测为B-ORG,第二个可能预测为B-PER)
SEE模型的具体实现如图4左侧部分,由一个BiLSTM神经网络和CRF层组成。句子中每一个中文字符由一个向量表示并且作为BiLSTM的输入。BiLSTM的输出被转变为每一个的分数。CRF层用来克服标签偏置的问题。对于文档中的每一个句子,SEE模型最终返回句子级别实体抽取的结果。
2.2 文档级别的事件抽取
DEE由两部分组成:一个是文档中关键事件发现模型,目的就是发现文档中的事件描述,和一个事件元素补全方案,目的是补全缺失的事件元素。
关键事件发现
如图4的右侧所示,事件发现的输入由两部分组成:一个是来自于SEE(蓝色部分)输出的事件元素和事件触发词的向量表示,另一个是当前句子的向量表示(红色部分)。这两个部分连接起来作为CNN层的输入特征。然后当前的句子被分类到两个类别:关键事件或者非关键事件。
元素补全方案
我们已经通过DEE获得了包含大部分事件元素的关键事件,也通过SEE获得了文档中每一个句子的事件提取结果。为了获得完整的事件信息,我们使用可以自动的从周围的句子中补全确实事件元素的元素补全方案。如图4所示,一个完整的质押事件包含事件描述 S n S_n Sn中的事件元素以及补全的从句子 S n + 1 S_{n+1} Sn+1获得的事件元素12个月。
3 评估
3.1 数据集
我们在四种类型的金融事件上进行实验,这四种事件类型是:股权冻结、股权质押、股权回购、股权增持事件。通过上述的自动生成数据的方法,我们标注了总共3976个金融通告。我们划分数据集按照8:1:1的方案。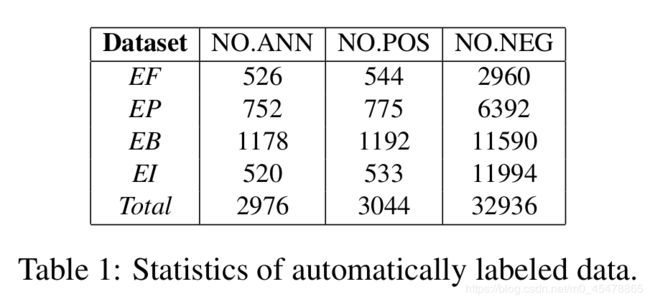
表1显示了数据集的统计,NO.ANN意思是对于每一个事件类型可以自动的进行标注的金融通告的数量(例如526的意思就是在总共的2976个金融通告中,可以被标注为股权冻结事件的数量是526个)。NO.POS代表总共的事件描述的数量(事件描述也是正例,事件描述是指能够描述一个事件的句子,那些不能描述一个事件的句子或者描述的不是当前事件类型的句子就是负例。例如,526是指有526个通告可以标记为股权冻结事件,而每一篇通告中有很多很多个句子,这526个通告的所有句子加起来有544个句子是描述股权冻结事件,剩下的2960个句子要么根本就没有描述一个事件,要么描述的也不是股权冻结事件)。正例句子和负例句子组成了DEE模型需要的文档级别的训练数据。包括事件触发词和一系列事件元素的正例句子被作为句子级别的训练数据输入给SEE模型。
我们随机选择200个样本(包含862个事件元素)来手工的评估自动标注数据的精度。如表2所示,展现了我们自动标注数据的高质量。
3.2 系统性能
我们使用准确率、召回率、F1值来评估DCFEE系统。表3展示的是在股权冻结事件的提取上基于模式的方法和DCFEE的方法的性能对比。实验结果表明在大部分的事件元素提取上DFCEE是优于基于模式的方法的。
表4展示的在不同的事件类型上SEE与DEE的准确率、召回率和F1值。值得注意的是在SEE阶段用的标签数据是自动生成的数据而在DEE阶段用的标签数据是来自于金融事件知识库。实验结果验证了SEE和DEE的有效性。
总结如下,实验结果表明基于远程监督的方法可以自动的生成高质量的有标注的数据从而避免手工的标注。这也证实了在这篇文档中提出的DCFEE能够有效的从文档层面上提取事件。
4 DCFEE的应用
DCFEE系统的应用就是为中文金融文本的在线事件提取系统。它可以帮助金融学专家从金融通告中快速的获得事件信息。图5显示的是在线DCFEE系统的截屏。不同的单词颜色表示不同的事件元素类型,划线句子代表文本中的事件描述。我们可以从非结构化的关于股权冻结事件的金融文本中获得一个完整的股权冻结事件。
5 相关工作
当前的事件抽取方法可以主要分为统计的方法,基于模式的方法和混合的方法。统计的方法可以划分为两类:在特征提取工程的基础上传统的机器学习算法,以及自动特征提取的神经网络算法。基于模式的方法通常应用在工业中因为它达到较高的准确率,但是却是较低的召回率。为了提高召回率,有两种主要的研究方向:构建相对完整的模式库并且使用半监督的方法去构建触发词字典。混合事件提取的方法结合了统计的方法和基于模式的方法。到目前为止,据我们所知,还没有哪一个系统可以在中文金融领域自动的生成标注数据并且从文档中提取出文档级别的事件。
用自己的话总结一下这篇论文:
DCFEE由两部分组成
- 第一部分是利用远程监督从文档中找出事件描述的那个句子,然后注释句子中的触发词和所有事件元素。其中找出的事件描述是属于文档级别的数据,因为DEE需要的训练数据就是事件描述和不是事件描述的句子。注释事件描述中的触发词和事件元素属于句子级别的数据,因为SEE需要的训练数据就是这些每个单词带有标记的句子,类似于实体识别等序列标注任务。
- 第二部分就是事件抽取,因为通过第一部分我们得到了DEE所需的数据和SEE所需要的数据。
那么第一部分具体怎么生成训练数据呢?论文中说在一篇文档中,如果一个句子包含大多数的事件元素并且有具体的触发词,那么这个句子就最可能是事件描述,那么这个句子中的事件元素也就会对应相应的角色。那么如何发现触发词呢?论文中说对于每一个事件类型,会先构建一个这种类型的触发词字典。通过上面的处理步骤后,那么对于结构化的知识库中的数据,就可以用它来回标非结构化的文档。比如图3.在金融的事件知识库中,我们有左侧表格数据,表格数据中有隆鑫有限公司,3940万股,中信证券股份有限公司,2017-02-23,2018-02-23。那么现在有一个句子:隆鑫控股将其持有的公司39400000股无限售流通股质押给质权人中信证券,质押期为12个月。那么根据知识库中的数据,我们就可以标注这句话为股权质押事件,并且将句子中的事件元素(NAME,NUM,ORG,BEG,END)给标注出来。于是也就得到了句子级别的标注数据,这句话就可以作为SEE的训练数据,不是事件元素的单词标注为O,那么现在就是一个典型的实体识别的任务。
这句话也会被标记为事件描述(正例),其它的句子就是负例,现在也就得到了文档级别的训练数据。
值得注意的是数据标注中有一些挑战,比如词汇的缩写等等。
现在已经得到了标注好的训练数据,接下来就是事件抽取。SEE没什么好说的,就是个实体识别了。对于DEE来讲,分为两部分,第一部分是判断一个句子是不是关键事件。(前面已经说了,我们会把得到的事件描述的那个句子和其他句子作为DEE的训练数据,事件描述的类别是1,表示正例)如何判断呢?也就是将SEE的输出和当前句子的向量表示联合起来送进CNN,输出是二分类问题。第二部分是事件元素补全,论文中没说具体怎么补全。

如图所示,An announcement中所有的句子都已经标注好了,也就是说句子中每一个事件元素和触发词都标记好了,然后送入SEE中,SEE会预测每一个句子中每一个单词对应的tag,有着最多的事件元素的那个句子作为事件描述,然后将所有句子输入给DEE,DEE的输出指明了事件描述,事件描述中的事件元素。