【语义分割】【总结】Object-Contextual Representations for Semantic Segmentation
中文翻译:https://blog.csdn.net/qq_36268755/article/details/105850287
主要贡献
整体结构
具体方法
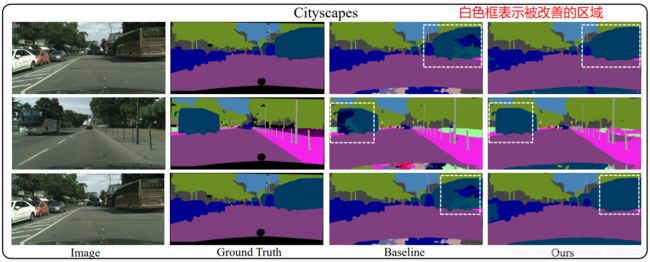
实验
对比实验1 粗分割的监督
对比实验2 像素-区域关系方法
Double-attention
ACFNet
实验3 多尺度上下文方法
PPM
ASPP
对比实验4 关系上下文方法
Self-Attention(non-local)
CC-Attention
DANet
对比实验5 复杂度
主要贡献
提出了一种新的关系上下文方法,该方法根据粗分割结果学习像素与对象区域特征之间的关系来增强像素特征的描述。
特点:
1.与之前的关系上下文方法(如non-local、dual attention、ocnet等)不同的是对对象进行了区分,学习了像素-对象区域之间的关系
2.可以理解为一种对粗分割的后操作处理
整体结构

- 将上下文像素划分为一组软对象区域,每个软对象区域对应一个类别,即从深层网络计算出的粗分割。
- 通过聚合相应对象区域中的像素表示作为每个对象区域的表示。
- 使用对象上下文表示扩展每个像素的表示。 OCR是所有对象区域表示的加权聚合,其加权根据像素和对象区域之间的关系计算。
具体方法
Backbone:ResNet or HRNet
Pixel Representations:对backboe得到的特征图,先进行了上采样,然后3*3卷积改变了通道数,每个像素对应的特征为
Soft Object Regions:对backboe得到的特征图,先进行了上采样,然后进行语义分割得到粗分割结果(通道数为NUM_CLASS的特征图,每层表示该像素属于该类的概率![]() )
)
Object Region Representations:每类对象的特征表示为

Pixel-Region Relation:每个像素与每个对象区域之间的关系

其中,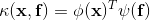 是关系函数(参考transformer) ,
是关系函数(参考transformer) ,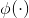 和
和![]() 是两个转换换函数,表示为1×1conv→BN→ReLU
是两个转换换函数,表示为1×1conv→BN→ReLU
Object Contextual Representations粉块:
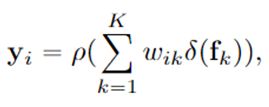
其中,![]() 和
和![]() 是变换函数,同上
是变换函数,同上
Augmented Representations:将对象上下文模块与初始特征图concat得到Object Contextual Representations,再进行通道数改变

其中,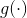 是转换函数,同上
是转换函数,同上
实验
对比实验1 粗分割的监督

注:w/o supervision表示将粉色框部分的loss替换为resnet第三层的auxiliary loss
在粗分割结果后加个loss本质上是对attention(分割结果概率)添加了约束,所以会使得结果变好,个人猜想如果加一个auxiliary loss后再加一个对粗分割结果的loss效果应该会更好。
对比实验2 像素-区域关系方法

Double-attention

Double-attention首先将整个空间的关键特征(对象区域特征)收集到一个紧凑的集合中,然后自适应地将其分布到每个位置(利用对象特征丰富像素特征),这样后续的卷积层即使没有很大的接收域也可以感知整个空间的特征。第一级的注意力集中操作有选择地从整个空间中收集关键特征,而第二级的注意力集中操作采用另一种注意力机制,自适应地分配关键特征的子集,这些特征有助于补充高级任务的每个时空位置。
ACFNet


网络主体操作由CCB模块与CAB模块实现。整体结构与OCR相同,不同点在于对象区域特征的计算部分,ACFNet只是将属于某一类对象的所有特征进行了简单的加和平均(即Class Center),所以效果比较差。
CCB(用于计算对象区域特征):先使用1*1的卷积减少特征通道数来降低计算花销,然后进行粗分割图像和feature进行相关的reshape和transpose,最后相乘获得Class Center,即通过每个像素点实现 特征-->类别 的映射。
CAB(用于计算对象上下文特征):得到的Class Center和粗糙分割图像在相关的transpose和reshape操作后进行相乘,就得到了类注意的特征。其过程可以理解为 像素点-->类别-->特征 的映射,这样就实现了相同类别像素点的特征的提取。
实验3 多尺度上下文方法

PPM

pyramid pooling modules 来进行不同尺寸的池化。文章中将特征图大小分别池化为:1x1,2x2,3x3,6x6。并通过一个卷积层将每个特征通道数变为feature map通道数的1/N,其中N为级数,此时N=4。
ASPP
使用不同膨胀率的空洞卷积得到特征图后concat
对比实验4 关系上下文方法

Self-Attention(non-local)


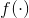 用于计算两个像素点之间的相关性(attention),并作为点j特征的权重,用于计算某点的特征,两者加权获得点i的新特征
用于计算两个像素点之间的相关性(attention),并作为点j特征的权重,用于计算某点的特征,两者加权获得点i的新特征
CC-Attention
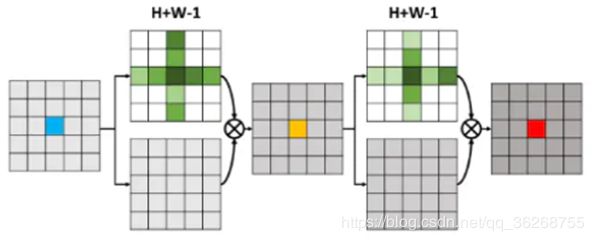
non-local的局限性在于需要的计算量很大,因此CCNet提出了criss-cross attention module在解决long-range dependencies的前提下,大幅降低了内存占用和计算量。作者发现non-local操作可以被两个连续的criss-cross操作代替,对于每个pixel,一个criss-cross操作只与特征图中(H+W-1)个位置连接,而不是所有位置。这激发了作者提出criss-cross attention module来从水平和竖直方向聚合long-range上下文信息。通过两个连续的criss-cross attention module,使得每个pixel都可以聚合所有pixels的特征信息,并且将时间和空间复杂度由O((HxW)x(HxW))降低到O((HxW)x(H+W-1))。
DANet

Dual Attention Networks (DANet)在spatial和channle维度来捕获全局特征依赖,提出position attention module去学习空间特征的相关性,提出channel attention module去建模channle的相关性
(多尺度上下文方法是将不同感受野的特征综合起来对特征进行丰富(通常基于金字塔池化或空洞卷积),关系上下文方法是利用特征之间的关系对特征进行丰富(通常基于自注意力机制))
对比实验5 复杂度
