【语义分割】【2019】Object-Contextual Representations for Semantic Segmentation
论文地址:https://arxiv.org/abs/1909.11065
代码:https://github.com/HRNet/HRNet-Semantic-Segmentation/tree/HRNet-OCR
总结:https://blog.csdn.net/qq_36268755/article/details/106542753
摘要
1.介绍
2.相关工作
3.方法
3.1背景
3.2 公式
3.3 结构
3.4 实验分析
4 实验
4.1 数据集
4.2 实施细节
4.3 与现有上下文方法的比较
4.4 与先进结果的比较
5 结论
摘要
在本文中,我们解决了语义分割的问题,并将重点放在用于稳健分割的上下文聚合策略上。我们的动机是像素的标签是像素所属对象的类别。我们提出一种简单而有效的方法,即对象上下文表示,通过利用相应对象类的表示来表征像素。首先,我们基于由groudtruth分割监督特征图构造对象区域,然后计算对象区域表示。其次,我们计算每个像素与每个对象区域之间的表示相似度,并使用对象上下文表示来增强每个像素的表示,这是所有对象区域表示根据它们与像素的相似性的加权聚合。我们凭实验证明,所提出的方法在六个具有挑战性的语义分割基准测试中取得了竞争优势,这些基准测试分别是Cityscapes,ADE20K,LIP,PASCAL VOC 2012,PASCAL Context和COCO Stuff。值得注意的是,我们以单一模型在Cityscapes排行榜上排名第2位。
针对语义分割问题中的上下文聚合策略进行研究,提出目标上下文描述,即通过相应目标类对像素进行表示。首先基于ground-truth有监督的学习目标区域的分割,然后对目标区域中的像素进行聚合表征计算目标区域描述,最后计算像素与对应目标区域之间的关系,并通过目标上下文表示来加强像素描述,其中目标上下文是根据所有目标区域描述与像素的关系进行加权聚合得到的。
1.介绍
语义分割是将类别标签分配给图像的每个像素的问题。 它是计算机视觉的基本主题,对于诸如自动驾驶之类的各种实际任务至关重要。 自FCN [41]以来,深度卷积网络一直是主要解决方案。 已经进行了各种研究,包括高分辨率表示学习[7,48],上下文聚合[66,6],这是本文的研究重点,等等。
一个位置的上下文通常是指一组位置,例如周围的像素。 早期的研究主要是关于语境的空间尺度,即空间范围。 代表作品,例如ASPP [6]和PPM [66],利用了多尺度背景。 最近,诸如DANet [15],CFNet [63]和OCNet [60]之类的一些作品考虑了一个位置及其上下文位置之间的关系,并为相似表示使用权重较高的聚合位置表示法进行汇总。
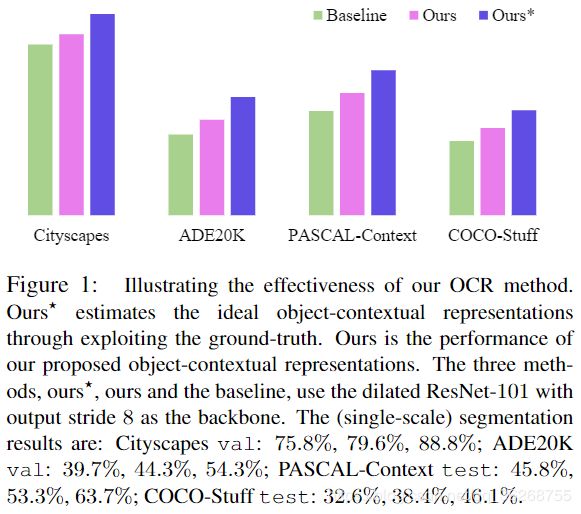
我们提议沿着探索位置与上下文之间关系的路线来研究上下文表示方案。 动机是分配给一个像素的类别标签是该像素所属的对象的类别。 我们旨在通过利用相应类别的对象区域的表示来增加一个像素的表示。 如图1所示的实证研究证明,当给出目标区域groudtruth时,这种表示增强方案可以显着提高分割质量。
我们的方法包括三个主要步骤。 首先,我们将上下文像素划分为一组软对象区域,每个软对象区域对应于一个类别,即从深层网络(例如ResNet [22]或HRNet [48])计算出的粗略软分割。 这种划分是在分割groud-truh的监督下学习的。 其次,我们通过聚集相应对象区域中像素的表示来估计每个对象区域的表示。 最后,我们使用对象上下文表示(OCR)扩展每个像素的表示。 OCR是所有对象区域表示的加权聚合,其加权根据像素和对象区域之间的关系计算。
提出的OCR方法不同于传统的多尺度上下文方案。 我们的OCR将相同对象类别的上下文像素与不同对象类别的上下文像素区分开来,而多尺度上下文方案(例如ASPP [6]和PPM [66])则不会,仅区分具有不同空间位置的像素 。 图2提供了一个示例来说明我们的OCR环境和多尺度环境之间的差异。 另一方面,我们的OCR方法也不同于先前的关系上下文方案[55、15、60、61、63]。 我们的方法将上下文像素构造为对象区域,并利用像素和对象区域之间的关系。相反,以前的关系上下文方案分别考虑上下文像素,仅利用像素和上下文像素之间的关系[15、60、63]或预测 仅来自像素的关系而不考虑区域[61]。

我们评估各种具有挑战性的语义细分基准的方法。 我们的方法优于PSPNet,DeepLabv3等多尺度上下文方案以及最近的DANet等关系上下文方案,并且效率也得到了提高。 我们的方法在五个基准上实现了竞争性性能:Cityscapestest为83.7%,ADE20Kval为45.66%,LIPval为56.65%,PASCAL-Contexttest为56.2%,COCO-Stufftest为40.5%。
2.相关工作
多尺度上下文。PSPNet[66]对金字塔池表示执行常规的卷积运算以捕获多尺度上下文。 DeepLab系列[5,6]采用具有不同扩张速率的par-alel扩张卷积(每个速率捕获不同规模的上下文)。 最近的工作[21、57、71、60]提出了各种扩展,例如,DenseASPP [57]使扩张的速率致密以覆盖更大的范围。 其他一些研究[7,38,16]构造了编码器-解码器结构,以利用多分辨率特征作为多尺度上下文。
关系上下文。DANet[15],CFNet [63]和OC-Net [60]通过聚合上下文像素的表示来扩展每个像素的表示,其中上下文由所有像素组成。 与全局上下文[40]不同,这些工作考虑了像素之间的关系(或相似性),这是基于自注意力方案[55,53]的,并以相似性作为权重执行加权聚合。 它的相关工作[8、61、9、36、34、59、32]和ACFNet [61]将像素分组为一组区域,然后通过考虑因素对区域表示进行聚合来增强像素表示 通过使用像素表示预测的上下文关系。
Double Attention及其相关工作[8、61、9、36、34、59、32]和ACFNet [61]将像素分组为一组区域,然后通过对区域表示进行聚集选通来增强像素表示 考虑到使用像素表示法预测的上下文关系。
我们的方法是一种关系上下文方法,与Double Attention和ACFNet有关。 区别在于区域形成和像素-区域关系计算。 我们的方法是在分割groud-truth的监督下学习区域的。 相比之下,除ACFNet以外的其他区域是无监督地形成的。 另一方面,像素和区域之间的关系是通过同时考虑像素和区域表示来计算的,而先前论文中的关系仅是根据像素表示来计算的。
粗到细分割。已经开发了各种粗到细分割方案[14、17、29、51、25、28、70],以逐步从粗到细细分分割图。 例如,[29]将粗分割图作为附加表示,并将其与原始图像或其他表示结合起来以计算出细分割图。
在某种意义上,我们的方法也可以被认为是粗到细的方案。 区别在于,我们使用粗略的分割图来生成上下文表示,而不是直接用作额外的表示形式。我们在补充材料中将我们的方法与传统的“粗到细”方案进行了比较。
按区域分割。按区域分割方法[1、2、20、19、56、44、2、52]将像素组织为一组区域(通常是超像素),然后对每个区域进行分类以获得图像分割 结果。 我们的方法不会对每个区域进行分割,而是使用该区域来学习像素的更好表示,从而获得更好的像素标记。
3.方法
语义分割是一个为图像I的每个像素 分配一个标签
分配一个标签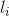 的问题,其中是K个不同的类之一。
的问题,其中是K个不同的类之一。
3.1背景
多尺度上下文。ASPP [5]模块通过以不同的扩张率[5,6,58]执行几个并行的等位扩张卷积来捕获多尺度上下文信息:
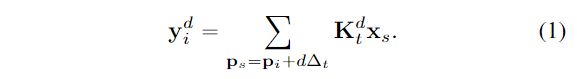
其中,![]() 是膨胀率为d的膨胀卷积在处(膨胀卷积核中心位置)的第s个采样位置。t是卷积的位置索引,如在
是膨胀率为d的膨胀卷积在处(膨胀卷积核中心位置)的第s个采样位置。t是卷积的位置索引,如在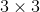 卷积中,
卷积中,![]() 。
。![]() 是
是![]() 的特征表示。
的特征表示。![]() 是的膨胀率为d的膨胀卷积的输出表示。
是的膨胀率为d的膨胀卷积的输出表示。![]() 是膨胀率为d的膨胀卷积在t处的核参数。输出多尺度上下文表示是由并行膨胀卷积输出的表示的级联。
是膨胀率为d的膨胀卷积在t处的核参数。输出多尺度上下文表示是由并行膨胀卷积输出的表示的级联。
基于膨胀卷积的多尺度上下文方案在不损失分辨率的情况下捕获了多个尺度的上下文。 PSPNet [66]中的金字塔池模块对不同尺度的表示执行常规的卷积,并且还捕获了多个尺度的上下文,但是对于大规模上下文失去了分辨率。
关系上下文。关系上下文方案[15,60,63]通过考虑相关性来计算每个像素的上下文:
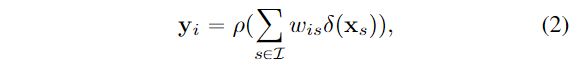
其中, 是图像的像素集,
是图像的像素集,![]() 是
是 与
与![]() 之间的关系,可以仅根据进行预测,也可以根据与
之间的关系,可以仅根据进行预测,也可以根据与![]() 计算得出。
计算得出。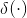 和
和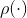 是类似自注意力[53]中的两个不同的转换函数。全局上下文方案[40]是关系上下文的一种
是类似自注意力[53]中的两个不同的转换函数。全局上下文方案[40]是关系上下文的一种![]() 的特殊情况。
的特殊情况。
3.2 公式
像素的类标签本质上是包含像素的对象的标签。受此启发,我们提出了一种对象上下文表示方法,该方法通过利用相应的对象表示来表征每个像素。
提出的对象上下文表示方案为(1)将图像I中的所有像素结构化为K个软对象区域;(2)通过聚集第k个对象区域中所有像素的表示,将每个对象区域表示为 (3)通过考虑它与所有对象区域的关系来聚合K个对象区域的表示来增强每个像素的表示:
(3)通过考虑它与所有对象区域的关系来聚合K个对象区域的表示来增强每个像素的表示:
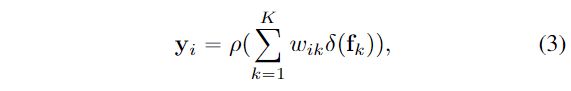
其中,是第k个对象区域的特征表示,![]() 是第i个像素与第k个对象区域之间的关系。和是转换函数。
是第i个像素与第k个对象区域之间的关系。和是转换函数。
软对象区域。我们将图像I分成K个对象区域![]() 。每个对象区域
。每个对象区域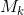 对应了类k,并由一个2维图(或粗分割图)表示,其中每个条目表示相应像素所属类别k的程度。
对应了类k,并由一个2维图(或粗分割图)表示,其中每个条目表示相应像素所属类别k的程度。
我们根据骨干网(例如ResNet或HR-Net)的中间表示输出来计算K个对象区域。 在训练过程中,我们利用交叉熵损失从地面真伪分割的监督下学习目标区域生成器。
对象区域表示。我们通过每个像素属于第k个对象区域的程度对所有像素进行加权表示,从而形成第k个对象区域的特征表示:

其中,是像素的表示。![]() 是像素属于第k个对象区域的归一化程度。我们使用空间softmax规范化每个对象区域。
是像素属于第k个对象区域的归一化程度。我们使用空间softmax规范化每个对象区域。
对象上下文表示。我们计算每个像素与每个对象区域之间的关系的方式如下:

其中,![]() 是非标准化关系函数,
是非标准化关系函数,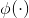 和
和![]() 是两个转换函数,表示为
是两个转换函数,表示为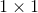 conv→BN→ReLU。这是受到自注意力[53]的启发,可以进行更好的关系估计。
conv→BN→ReLU。这是受到自注意力[53]的启发,可以进行更好的关系估计。
增强表示。像素的最终表示由两部分聚合而成。(1)原始的表示,(2)对象上下文表示 :
:
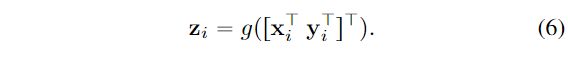
其中,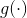 是用于融合原始表示和对象上下文表示的转换函数,表示为conv→BN→ReLU。我们的方法的整体流程如图3所示。
是用于融合原始表示和对象上下文表示的转换函数,表示为conv→BN→ReLU。我们的方法的整体流程如图3所示。
评论:最近的一些著作,例如Double Attention[8]和ACFNet [61],可以用公式3来表示,但是在某些方面与我们的方法有所不同。 例如,在“双倍注意”中形成的区域不对应于对象类别,并且ACFNet [61]中的关系仅使用对象区域表示从无像素的像素表示中计算得出。
3.3 结构
骨干网络。我们使用膨胀的ResNet-101 [22](输出步幅为8)或HRNet-W48 [48](输出步幅为4)作为主干。 对于扩展的ResNet-101,有两个表示形式输入到OCR模块。 Stage3的第一个表示是用于预测粗分割(对象区域)。 阶段4中的另一个表示通过3×3卷积(512个输出通道)进行,然后将其送入OCR模块。 对于HRNet-W48,我们仅将最终表示形式用作OCR模块的输入。
OCR模块。我们将上述方法的公式表示为OCR模块,如图3所示。我们使用线性函数(一个卷积)来预测粗分割(软对象区域),并监督其像素方向的交叉熵损失。 所有变换函数![]() ,,,和通过conv→BN→ReLU实现,前三个输出256通道,后两个输出512通道。 我们使用非线性函数根据最终表示预测最终分割,并在最终分割预测上应用像素级交叉熵损失。
,,,和通过conv→BN→ReLU实现,前三个输出256通道,后两个输出512通道。 我们使用非线性函数根据最终表示预测最终分割,并在最终分割预测上应用像素级交叉熵损失。
3.4 实验分析
我们以膨胀的ResNet-101为骨干网络,在Cityscapes验证集上进行实证分析实验。
对象区域监督。研究对象区域监督的影响。 我们通过删除对软对象区域的监视(即损失)(在图3中的粉红色虚线框内)并在ResNet-101的第3阶段中添加另一个辅助损失来修改我们的方法。 将其他所有设置保持相同,并在表1的最左侧2列中报告结果。我们可以看到,形成对象区域的监督对于性能至关重要。
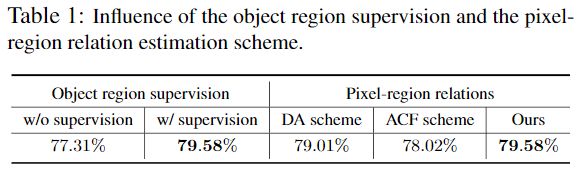
像素-区域关系。我们将我们的方法与其他两种不使用区域表示法来估计像素-区域关系的机制进行比较:(i)Double-Attention [8]使用像素表示来预测相关性; (ii)ACFNet [61]直接使用一个中间分割图来表示关系。 我们使用DA方案和ACF方案来表示上述两种机制。我们自己实现了这两种方法,仅使用膨胀的ResNet-101作为主干,而未使用多尺度上下文(使用ASPP [61]改善了ACFNet的结果)。 表1显示了我们的方法获得了卓越的性能。 原因是我们利用像素表示以及区域表示来计算关系。 区域表示能够表征特定图像中的对象,因此与仅使用像素表示相比,该关系对于特定图像更准确。
Groud-truth OCR。我们使用分割的groudtruth来形成目标区域和像素区域关系来研究分割性能,以证明我们的动机。(i)使用groudtruth形成对象区域:如果groudtruth标签![]() 则设像素i属于第k个目标区域的置信度
则设像素i属于第k个目标区域的置信度![]() ,否则设
,否则设![]() .(ii)使用groudtruth计算像素区域关系:如果groudtruth标签
.(ii)使用groudtruth计算像素区域关系:如果groudtruth标签![]() 则设像素-区域关系
则设像素-区域关系![]() ,否则设
,否则设![]() 。我们在图1中说明了我们在四个baseline的详细结果。
。我们在图1中说明了我们在四个baseline的详细结果。
4 实验
4.1 数据集
Cityscapes. Cityscapes数据集[11]的任务是了解城市景观。 总共有30个类,只有19个类用于解析评估。 该数据集包含5K高质量像素级别的精细注释图像和20K粗略注释图像。 带有注释的5K图像分为2,975/500 /1,525张图像,分别用于训练,验证和测试。
ADE20K. ADE20K数据集[68]用于ImageNetscene解析挑战2016。共有150个类和具有1,038个图像级标签的各种场景。 数据集分为20K / 2K / 3K图像用于训练,验证和测试。
LIP. LIP数据集[18]用于单个人解析任务的LIP挑战2016。 大约有5万张图像,其中包含20个类别(19个语义人体零件类别和1个背景类别)。 训练集,验证集和测试集分别包含30K,10K,10K图像。
PASCAL-Context. PASCAL-Context数据集[43]是具有挑战性的场景解析数据集,其中包含59个语义类和1个背景类。 训练集和测试集分别包含4,998和5,105个图像。
COCO-Stuff. COCO-Stuff数据集[3]是一个具有挑战性的场景解析数据集,包含171个语义类。训练集和测试集分别由9K和1K图像组成。
4.2 实施细节
训练设置。 我们使用ImageNet上预训练的模型初始化骨干网络并随机初始化OCR模型。 我们用因子![]() 执行多项式学习率策略,最终损失的权重为1,对监督对象区域估计(或辅助损失)的损失的权重为0.4。 我们使用
执行多项式学习率策略,最终损失的权重为1,对监督对象区域估计(或辅助损失)的损失的权重为0.4。 我们使用![]() [47]在多个GPU之间同步BN的均值和标准差。 对于数据扩充,我们执行水平随机翻转,在[0.5,2]范围内进行随机缩放以及在[-10,10]范围内进行随机亮度抖动。对复的现方法执行相同的训练设置,例如PPM,ASPP, 确保公平。 我们遵循先前的工作[6,62,66]为基准数据集设置训练。
[47]在多个GPU之间同步BN的均值和标准差。 对于数据扩充,我们执行水平随机翻转,在[0.5,2]范围内进行随机缩放以及在[-10,10]范围内进行随机亮度抖动。对复的现方法执行相同的训练设置,例如PPM,ASPP, 确保公平。 我们遵循先前的工作[6,62,66]为基准数据集设置训练。
- Cityscapes:我们将初始学习率设置为0.01,权重衰减设置为0.0005,裁剪大小设置为769*769,批处理大小设置为8。对于验证/测试集的实验,我们在训练集/训练集+验证集上将训练迭代设置为40K / 100K。 对于增加了额外数据的实验,我们对coarse/ Mapillary进行50K迭代优化模型,并根据[31]继续对训练集+验证集进行20K迭代进行模型微调。
- ADE20K:我们将初始学习率设置为0.02,权重衰减设置为0.0001,裁剪尺寸为520*520,批大小设为16,如果未指定,则训练迭代为150K次。
- LIP:我们将初始学习率设置为0.007,权重衰减为0.0005,裁剪大小为473*473,批大小为32,训练迭代度为100K(如果未指定)。
- PASCAL-Context: 如果未指定,我们将初始学习率设为0.001,权重衰减为0.0001,裁剪大小为520ˆ520,批次大小为16,训练迭代次数为30K。
- COCO-Stuff:我们将初始学习率设为0.001,重量衰减为0.0001, 裁剪大小为520ˆ520,批次大小为16,训练迭代为60K(如果未指定)
4.3 与现有上下文方法的比较
我们以膨胀的ResNet-101为骨干进行实验,并使用相同的训练/测试设置来确保公平。
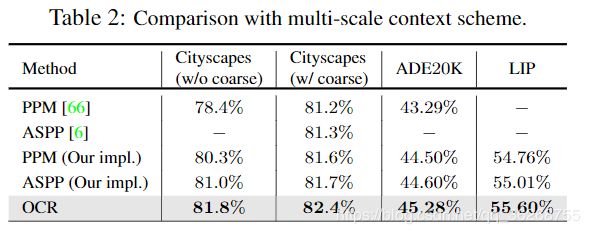
多尺度上下文。我们将OCR与包括PPM [66]和ASPP [6]的多尺度上下文方案进行比较,包括Cityscapes测试集,ADE20K验证集和LIP验证集三个基准。 我们在表2中显示结果。我们复制的PPM / ASPP优于[66,6]中最初报告的数字。 从表2中可以看出,我们的OCR大大优于两种多尺度情境方案。
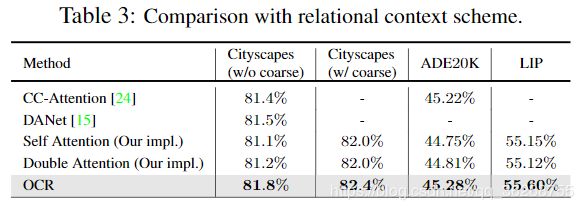
关系上下文。我们在相同的三个基准上,包括Cityscapes测试集,ADE20K验证集和LIP验证集上,将OCR与各种关系上下文方案进行了比较,包括Self-Attention[53,55],Criss-Cross attention [24] (CC-Attention),DANet [15]和Double Attention [8] 对于复现的“Double Attention”,我们微调区域数并选择性能最佳的64个。 补充材料中说明了更详细的分析和比较。 根据表3中的结果,可以看出我们的OCR优于这些关系上下文方案。
复杂性。我们将OCR的效率与多尺度上下文方案和关系上下文方案的效率进行了比较。 我们测量了上下文模块引入的增加的参数,GPU内存,计算复杂度(由FLOP的数量来衡量)和推理时间,而没有计算骨干网的复杂性。 表4中的比较显示了所提出的OCR方案的优越性。
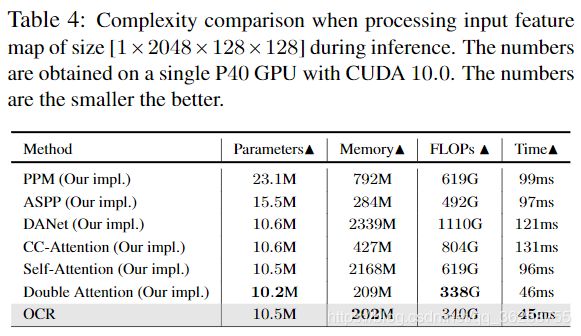
参数:与多尺度上下文方案相比,大多数关系上下文方案需要较少的参数。例如,我们的OCR仅需要PPM参数的50%不到。
内存:我们的OCR和Double Attention方法都比其他方法(例如,DANet,PPM)性能好得多。 例如,DANet需要比我们的OCR大近10倍的GPU内存。 此外,我们的OCR仅需要CC-Attention的50%GPU内存。
FLOPs:我们的OCR仅分别需要PPM/ DANet所需FLOPs的50%/ 30%。
运行时间:我们的OCR比除了Double Attention以外的其他方法快2倍以上。
4.4 与先进结果的比较
考虑到不同的方法会在不同的baseline上进行改进以达到最佳性能,因此,我们将现有工作根据适用的baseline分为两类:(i)简单baseline:步长为8的膨胀ResNet-101; (ii)先进的baseline:PSPNet,DeepLabv3,多网格(MG),步长为4的可以生成更高分辨率输出的编码器-解码器结构,或更强大的主干网络,例如WideResNet-38,Xception-71和HRNet。
为了公平地与这两个组进行公平比较,我们在简单的baseline(膨胀的ResNet-101,使用stride8)和高级baseline(HRNet-W48,使用stride4)上执行OCR。 我们将所有结果显示在表5中,并分别说明每个baseline的比较细节,如下所示。
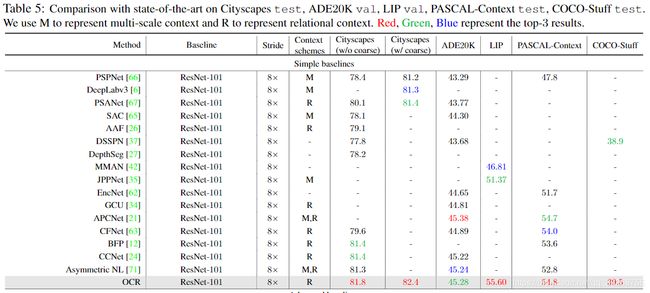
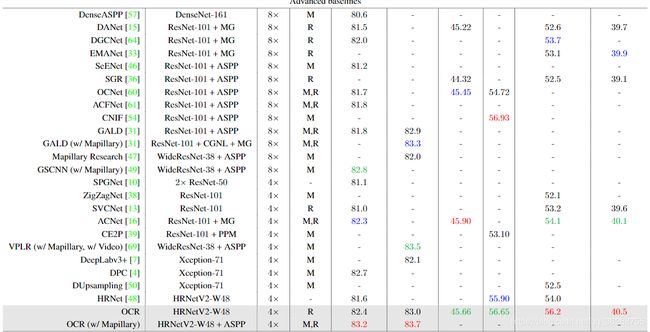
Cityscapes。与在Cityscape测试集上不使用粗略数据的基于简单baseline的方法相比,我们的方法可达到81.8%的最佳性能,这已经可以与某些基于高级baseline的方法(例如DANet,ACFNet)相媲美。 通过利用粗注图像进行训练,我们的方法获得了更好的性能82.4%。
为了与基于高级baseline的方法进行比较,我们在HRNet-W48上执行了OCR,将我们的OCR与ASPP结合起来并在Mapillary数据集 [44]上进行了微调。 通过单一模型输入,我们的方法在Cityscapes测试集上达到83.7%。 此外,我们分别在HRNet-W48上执行PPM和ASPP,并凭经验发现,直接应用PPM或ASPP不会提高性能,甚至会降低性能,而我们的OCR则持续提高性能。
ADE20K。从表5可以看出,我们的OCR方法与之前大多数基于简单baseline和高级baseline的方法相比,获得了具有竞争力的性能(45.28%和45.66%)。例如,ACFNet[21]利用多尺度上下文和关系上下文来实现更高的性能。最新的ACNet[16]通过结合更丰富的局部和全局上下文实现了最佳性能。
LIP。基于简单的baseline,我们的方法在LIP验证集上获得了最佳性能55.60%。应用更强大的主干HRNetV2-W48可以将性能进一步提高到56.65%,这比以前的方法要好。 CNIF [54]的最新工作是通过注入人体部位的层次结构知识来实现最佳性能(56.93%)。 我们的方法可能会从这种层次结构知识中受益。 所有结果均基于仅翻转测试而不进行多尺度测试2.PASCAL-Context。
PASCAL-Context.。根据[48],我们评估了模型在59个类别的性能。可以看出,我们的方法优于基于简单baseline和高级baseline的最佳方法。 HRNet-W48 + OCR方法获得了最佳性能56.2%,大大超过了第二佳的性能,例如ACPNet(54.7%)和ACNet(54.1%)
COCO-Stuff。可以看出,我们的方法在基于ResNet-101实现了39.5%的最佳性能,在HRNetV2-48的基础上达到了40.5%的最佳性能。
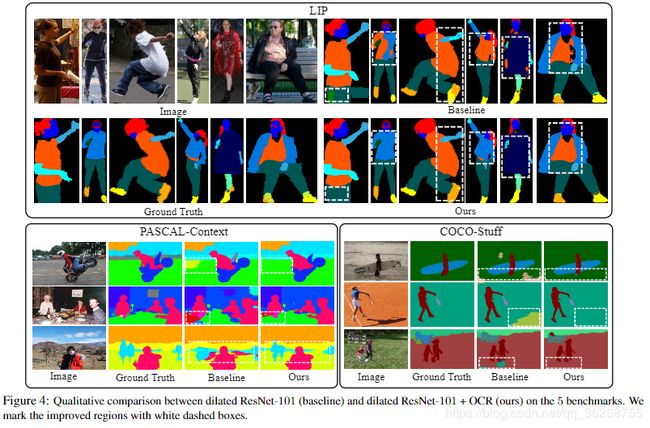
定性结果。我们在图4的5个基准上说明了定性结果。 我们使用白色虚线框标记硬区域,这些硬区域已通过我们的方法很好地分类,但被基线错误地分类了。

5 结论
在这项工作中,我们提出了一种用于语义分割的对象上下文表示方法。 成功的主要原因是像素的标签是像素所位于的对象的标签,并且通过用相应的对象区域表示来表征每个像素来增强像素表示。 我们凭经验表明,我们的方法在各种基准上均带来了持续改进。