数据结构与算法基础知识点
线性表(Linear List)
是具有相同数据类型的数据元素的一个有限序列。通常表示为:(a1,a2,… ai,ai+1… an)
线性表的顺序存储是指用一组地址连续的存储单元依次存放线性表的数据元素,这种存储形式的线性表称为顺序表。它的特点是线性表中相邻的元素在内存中的存储位置也是相邻的。由于线性表中的所有数据元素属于同一类型,所以每个元素在存储中所占的空间大小相同。
优点:顺序存储结构内存的存储密度高,可以节约存储空间,并可以随机或顺序地存取结点,但是插入和删除操作时往往需要移动大量的数据元素,并且要预先分配空间,并要按最大空间分配,因此存储空间得不到充分的利用,从而影响了运行效率。
线性表的链式存储结构,它能有效地克服顺序存储方式的不足,同时也能有效地实现线性表的扩充。
单链表和循环链表(循环链表是单链表的变形)
线性表的链式存储结构是用一组地址任意的存储单元存放线性表中的数据元素。除了存储其本身的值之外,还必须有一个指示该元素直接后继存储位置的信息,即指出后继元素的存储位置。这两部分信息组成数据元素ai的存储映像,称为结点(node)。每个结点包括两个域:一个域存储数据元素信息,称为数据域;另一个存储直接后继存储位置的域称为指针域。
指针域中存储的信息称做指针或链。N个结点链结成一个链表,由于此链表的每一个结点中包含一个指针域,故又称线性链表或单链表。
循环链表最后一个结点的next指针不为空,而是指向了表的前端。为简化操作,在循环链表中往往加入表头结点。
循环链表的特点是:只要知道表中某一结点的地址,就可搜寻到所有其他结点的地址。
双向链表
双向链表是指在前驱和后继方向都能游历(遍历)的线性链表。
在双向链表结构中,每一个结点除了数据域外,还包括两个指针域,一个指针指向该结点的后继结点,另一个指针指向它的前趋结点。通常采用带表头结点的循环链表形式。
用指针实现表
用数组实现表时,利用了数组单元在物理位置上的邻接关系表示表元素之间的逻辑关系。
优点是:
无须为表示表元素之间的逻辑关系增加额外的存储空间。
可以方便地随机存取表中任一位置的元素。
缺点是:
插入和删除运算不方便,除表尾位置外,在表的其他位置上进行插入或删除操作都须移动大量元素,效率较低。
由于数组要求占用连续的存储空间,因此在分配数组空间时,只能预先估计表的大小再进行存储分配。当表长变化较大时,难以确定数组的合适的大小
顺序表与链表的比较
顺序表的存储空间可以是静态分配的,也可以是动态分配的。链表的存储空间是动态分配的。
顺序表可以随机或顺序存取。链表只能顺序存取。
顺序表进行插入/删除操作平均需要移动近一半元素。链表则修改指针不需要移动元素。
若插入/删除仅发生在表的两端,宜采用带尾指针的循环链表。
存储密度=结点数据本身所占的存储量/结点结构所占的存储总量。
顺序表的存储密度= 1,链表的存储密度< 1。
总结:顺序表是用数组实现的,链表是用指针实现的。用指针来实现的链表,结点空间是动态分配的,链表又按链接形式的不同,区分为单链表、双链表和循环链表。
栈(stack)
是限定仅在表尾进行插入或删除操作的线性表。栈是一种后进先出(Last In First Out)/先进后出的线性表,简称为LIFO表
用指针实现栈—链(式)栈链式栈
无栈满问题,空间可扩充
插入与删除仅在栈顶处执行
链式栈的栈顶在链头
适合于多栈操作
链栈的基本操作
1)进栈运算
进栈算法思想:
1)为待进栈元素x申请一个新结点,并把x赋给 该结点的值域。
2)将x结点的指针域指向栈顶结点。
3)栈顶指针指向x结点,即使x结点成为新的栈顶结点。
具体算法如下:
SNode *Push_L(SNode * top,ElemType x)
{
SNode *p;
p=(SNode*)malloc(sizeof(SNode));
p->data=x;
p->next=top;
top=p;
return top;
}
2)出栈运算
出栈算法思想如下:
1)检查栈是否为空,若为空,进行错误处理。
2)取栈顶指针的值,并将栈顶指针暂存。
3)删除栈顶结点。
SNode *POP_L(SNode * top,ElemType *y)
{SNode *p;
if(top==NULL) return 0;/*链栈已空*/
else{
p=top;
*y=p->data;
top=p->next; free(p);
return top;
}
3)取栈顶元素
具体算法如下:
void gettop(SNode *top)
{
if(top!=NULL)
return(top->data); /*若栈非空,则返回栈顶元素*/
else
return(NULL); /*否则,则返回NULL*/
}
队列(Queue)
是只允许在表的一端进行插入,而在另一端进行删除的运算受限的线性表。其所有的插入均限定在表的一端进行,该端称为队尾(Rear);所有的删除则限定在表的另一端进行,该端则称为队头(Front)。如果元素按照a1,a2,a3....an的顺序进入队列,则出队列的顺序不变,也是a1,a2,a3....an。所以队列具有先进先出(First In First Out,简称FIFO)/后进后出特性。如车站排队买票,排在队头的处理完走掉,后来的则必须排在队尾等待。在程序设计中,比较典型的例子就是操作系统的作业排队。
队列的顺序存储结构称为顺序队列,顺序队列实际上是运算受限的顺序表,和顺序表一样,顺序队列也是必须用一个数组来存放当前队列中的元素。由于队列的队头和队尾的位置是变化的,因而要设两个指针分别指示队头和队尾元素在队列中的位置。
循环队列是为了克服顺序队列中“假溢出”,通常将一维数组Sq.elem[0]到Sq.elem.[MaxSize-1]看成是一个首尾相接的圆环,即Sq.elem[0]与Sq.elem .[maxsize-1]相接在一起。这种形式的顺序队列称为循环队列。
用线性链表表示的队列称为链队列。链表的第一个节点存放队列的队首结点,链表的最后一个节点存放队列的队尾首结点,队尾结点的链接指针为空。另外还需要两个指针(头指针和尾指针)才能唯一确定,头指针指向队首结点,尾指针指向队尾结点
递归
定义:若一个函数部分地包含它自己或用它自己给自己定义,则称这个函数是递归的;若一个算法直接地或间接地调用自己,则称这个算法是递归的算法。
树
①结点的度:结点拥有子节点的个数
②树的度:该树中最大的度数
③叶子结点:度为零的结点
④分支结点:度不为零的结点
⑤内部结点:除根结点之外的分支结点
⑥开始结点:根结点又称为开始结点
结点的高度:该结点到各结点的最长路径的长度
森林:m(m≥0)棵互不相交的树的集合。将一棵非空树的根结点删去,树就变成一个森林;
反之,给m棵独立的树增加一个根结点,并把这m棵树作为该结点的子树,森林就变成一棵树。
2.结点的层数和树的深度
①结点的层数:根结点的层数为1,其余结点的层数等于其双亲结点的层数加1。
②堂兄弟:双亲在同一层的结点互为堂兄弟。
③树的深度:树中结点的最大层数称为树的深度。
注意:要弄清结点的度、树的度和树的深度的区别。
树中结点之间的逻辑关系是“一对多”的关系,树是一种非线性的结构
树的遍历
先序遍历:访问根结点——先序遍历根的左子树——先序遍历根的右子数
中序遍历:中序遍历左子树——访问根结点——中序遍历右子树
后序遍历:后序遍历左子树——后序遍历右子树——访问根结点
最优二叉树(哈夫曼树):最小两结点数相加的值再与次小结点数合并。
已知一棵二叉树的前根序序列和中根序序列,构造该二叉树的过程如下:
1. 根据前根序序列的第一个元素建立根结点;
2. 在中根序序列中找到该元素,确定根结点的左右子树的中根序序列;
3. 在前根序序列中确定左右子树的前根序序列;
4. 由左子树的前根序序列和中根序序列建立左子树;
5. 由右子树的前根序序列和中根序序列建立右子树。
-已知一棵二叉树的后根序序列和中根序序列,构造该二叉树的过程如下:
1. 根据后根序序列的最后一个元素建立根结点;
2. 在中根序序列中找到该元素,确定根结点的左右子树的中根序序列;
3. 在后根序序列中确定左右子树的后根序序列;
4. 由左子树的后根序序列和中根序序列建立左子树;
5. 由右子树的后根序序列和中根序序列建立右子树。
翻书问题或者走台阶问题:
共有n个台阶,每次只能上1个台阶或者2个台阶,共有多少种方法爬完台阶。
共有n页书,每次只能翻1页或者2页书,共有多少种方法翻完全书。
# f(n)为翻完全书的方法
# 递归写法
def f(n):
if n == 1:
return 1
if n == 2:
return 2
if n > 2:
return f(n - 1) + f(n - 2)
# 迭代写法,或者叫循环写法
def f(n):
res = [0 for i in range(n + 1)]
res[1] = 1
res[2] = 2
for i in range(3, n+1):
res[i] = res[i - 1] + res[i - 2]
return res[n]
# 使用缓存
cache = {}
def fib(n):
if n not in cache.keys():
cache[n] = _fib(n)
return cache[n]
def _fib(n):
if n == 1 or n == 2:
return n
else:
return fib(n-1) + fib(n-2)二分查找
def LinearSearch(array, t):
for i in range(len(array)):
if array[i] == t:
return True
return False
def BinarySearch(array, t):
left = 0
right = len(array) - 1
while left <= right:
mid = int((left + right) / 2)
if array[mid] < t:
left = mid + 1
elif array[mid] > t:
right = mid - 1
else:
return True
return False
array = list(range(100000000))
import time
t1 = time.time()
LinearSearch(array, 100000001)
t2 = time.time()
print('线性查找:', t2 - t1)
t3 = time.time()
BinarySearch(array, 100000001)
t4 = time.time()
print('二分查找:', t4 - t3)
二分查找例题(变种)
题意
[
[1, 3, 5, 7],
[10, 11, 16, 20],
[23, 30, 34, 50]
]
查找比如16在不在矩阵中。解法
class Solution:
# @param matrix, a list of lists of integers
# @param target, an integer
# @return a boolean
def searchMatrix(self, matrix, target):
i = 0
j = len(matrix[0]) - 1
while i < len(matrix) and j >= 0:
if matrix[i][j] == target:
return True
elif matrix[i][j] > target:
j -= 1
else:
i += 1
return False链表
链表中最简单的一种是单向链表,它包含两个域,一个信息域和一个指针域。这个链接指向列表中的下一个节点,而最后一个节点则指向一个空值。
python代码
链表中的节点的数据结构
# 链表中的节点的数据结构
class ListNode(object):
def __init__(self, x):
self.val = x
self.next = None
# 实例化
A = ListNode('a')
B = ListNode('b')
C = ListNode('c')
A.next = B
B.next = C
# 这样,一条链表就形成了。
# 'a' -> 'b' -> 'c'
# 遍历链表
tmp = A
while tmp != None:
print(tmp.val)
tmp = tmp.next
# 递归遍历链表
def listorder(head):
if head:
print(head.val)
listorder(head.next)
listorder(A)例题
翻转一条单向链表。
例子:
Input: 1->2->3->4->5->NULL
Output: 5->4->3->2->1->NULL解答:
# Definition for singly-linked list.
class ListNode(object):
def __init__(self, x):
self.val = x
self.next = None
class Solution(object):
def reverseList(self, head):
"""
:type head: ListNode
:rtype: ListNode
"""
dummy = head
tmp = dummy
while head and head.next != None:
dummy = head.next
head.next = dummy.next
dummy.next = tmp
tmp = dummy
return dummy
head = ListNode(1)
head.next = ListNode(2)
head.next.next = ListNode(3)
head.next.next.next = ListNode(4)
head.next.next.next.next = ListNode(5)
solution = Solution()
reverse_head = solution.reverseList(head)
tmp = reverse_head
while tmp:
print(tmp.val)
tmp = tmp.next二叉树
python代码
class TreeNode(object):
def __init__(self, x):
self.val = x
self.left = None
self.right = None
root = TreeNode(1)
root.left = TreeNode(2)
root.right = TreeNode(3)
'''
1
/ \
2 3
'''
# root就是一颗二叉树中序遍历(先遍历左子树,再遍历根节点,再遍历右子树)
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
def inorder(root):
if root:
inorder(root.left)
print(root.val)
inorder(root.right)前序遍历(先遍历根节点,再遍历左子树,再遍历右子树)
class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
def preorder(root):
if root:
print(root.val)
preorder(root.left)
preorder(root.right)
root = TreeNode(1)
root.left = TreeNode(2)
root.right = TreeNode(3)
preorder(root)后序遍历(先遍历左子树,再遍历右子树,再遍历根节点)
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
def postorder(root):
if root:
postorder(root.left)
postorder(root.right)
print(root.val)测试程序
class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
def preorder(root):
if root:
print(root.val)
preorder(root.left)
preorder(root.right)
def inorder(root):
if root:
inorder(root.left)
print(root.val)
inorder(root.right)
def postorder(root):
if root:
postorder(root.left)
postorder(root.right)
print(root.val)
root = TreeNode(1)
root.left = TreeNode(2)
root.right = TreeNode(3)
root.left.left = TreeNode(4)
root.left.right = TreeNode(5)
root.right.left = TreeNode(6)
root.right.right = TreeNode(7)
preorder(root)
inorder(root)
postorder(root)已知一颗二叉树的先序遍历序列为ABCDEFG,中序遍历为CDBAEGF,能否唯一确定一颗二叉树?如果可以,请画出这颗二叉树。
A
/ \
B E
/ \
C F
\ /
D G
先序遍历: ABCDEFG
中序遍历: CDBAEGF
后序遍历: DCBGFEA
使用程序根据二叉树的先序遍历和中序遍历来恢复二叉树。
class TreeNode:
def __init__(self, x):
self.val = x
self.left = None
self.right = None
def buildTree(preorder, inorder):
if len(preorder) == 0:
return None
if len(preorder) == 1:
return TreeNode(preorder[0])
root = TreeNode(preorder[0])
index = inorder.index(root.val)
root.left = buildTree(preorder[1 : index + 1], inorder[0 : index])
root.right = buildTree(preorder[index + 1 : len(preorder)], inorder[index + 1 : len(inorder)])
return root
preorder_string = 'ABCDEFG'
inorder_string = 'CDBAEGF'
r = buildTree(preorder_string, inorder_string)
preorder(r)
inorder(r)
postorder(r)栈和队列
栈
python实现
class Stack(object):
def __init__(self):
self.stack = []
def pop(self):
if self.is_empty():
return None
else:
return self.stack.pop()
def push(self,val):
return self.stack.append(val)
def peak(self):
if self.is_empty():
return None
else:
return self.stack[-1]
def size(self):
return len(self.stack)
def is_empty(self):
return self.size() == 0
s = Stack()
s.push(1)
s.peak()
s.is_empty()
s.pop()队列
python实现
class Queue(object):
def __init__(self):
self.queue = []
def enqueue(self,val):
self.queue.insert(0,val)
def dequeue(self):
if self.is_empty():
return None
else:
return self.queue.pop()
def size(self):
return len(self.queue)
def is_empty(self):
return self.size() == 0
q = Queue()
q.enqueue(1)
q.is_empty()
q.dequeue()使用队列模拟栈。
class StackByQueue(object):
def __init__(self):
self.stack = Queue()
def push(self, val):
self.stack.enqueue(val)
def pop(self):
for i in range(self.stack.size() - 1):
value = self.stack.dequeue()
self.stack.enqueue(value)
return self.stack.dequeue()使用栈模拟队列
class QueueByStack(object):
def __init__(self):
self.queue1 = Stack()
self.queue2 = Stack()
def enqueue(self, val):
self.queue1.push(val)
def dequeue(self):
for i in range(self.queue1.size() - 1):
value = self.queue1.pop()
self.queue2.push(value)
res = self.queue1.pop()
for i in range(self.queue2.size()):
value = self.queue2.pop()
self.queue1.push(value)
return res插入排序
def insertSort(A):
for j in range(1, len(A)):
key = A[j]
i = j - 1
while i >= 0 and A[i] > key:
A[i + 1] = A[i]
i = i - 1
A[i + 1] = key
return A
A = [5, 2, 4, 6, 1, 3]
print(insertSort(A))
function insertSort(A) {
for (j = 1; j < A.length; j++) {
var key = A[j];
var i = j - 1;
while (i >= 0 && A[i] > key) {
A[i + 1] = A[i];
i = i - 1;
}
A[i + 1] = key;
}
return A;
}
var A = [5, 2, 4, 6, 1, 3];
console.log(insertSort(A));快速排序
def partition(A, p, r):
x = A[r]
i = p - 1
for j in range(p, r):
if A[j] <= x:
i = i + 1
A[i], A[j] = A[j], A[i]
A[i + 1], A[r] = A[r], A[i + 1]
return i + 1
def quickSort(A, p, r):
if p < r:
q = partition(A, p, r)
quickSort(A, p, q - 1)
quickSort(A, q + 1, r)
A = [2, 8, 7, 1, 3, 5, 6, 4]
quickSort(A, 0, 7)
print(A)时间复杂度
假设快速排序的时间复杂度为f(N)
f(N) = 2 * f(N / 2) + O(N)
f(N) = 2 * (2 * f(N / 4) + O(N/2)) + O(N)
...
f(1) = O(1)
所以f(N) = O(NlogN) 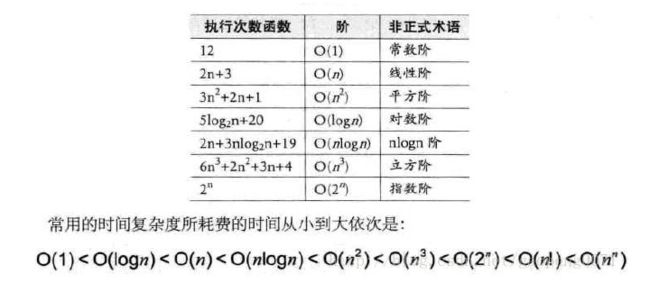
在数组元素数量为n的数组里面寻找第k大的数
def partition(A, p, r):
x = A[r]
i = p - 1
for j in range(p, r):
if A[j] >= x:
i = i + 1
A[i], A[j] = A[j], A[i]
A[i + 1], A[r] = A[r], A[i + 1]
return i + 1
def findKthLargest(A, p, r, k):
if p <= r:
q = partition(A, p, r)
if k - 1 == q:
return A[q]
elif k - 1 < q:
return findKthLargest(A, p, q - 1, k)
else:
return findKthLargest(A, q + 1, r, k)
A = [2, 8, 7, 1, 3, 5, 6, 4]
ret = findKthLargest(A, 0, 7, 8)
print('ret: ', ret)