【YOLOv3】基于darknet的训练过程(简洁版)
文章目录
- 准备工作
- 训练自己的数据集
- 开始训练
- 训练日志可视化
准备工作
参考链接:https://pjreddie.com/darknet/yolo/
- 下载darknet
- 修改Makefile
- 下载yolov3.weights
- 下载darknet53.conv.74(后面训练数据集会用到,先下载好了,留着备用)
- 测试
#1. 下载`darknet`
git clone https://github.com/pjreddie/darknet
#2. 修改`Makefile`
cd darknet
make
#3. 下载`yolov3.weights`
wget https://pjreddie.com/media/files/yolov3.weights
#4. 下载`darknet53.conv.74`
wget https://pjreddie.com/media/files/darknet53.conv.74
#5. 测试图片
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
#5. 测试视频
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights <video file>
#5. 加载摄像头
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
总结:可以将上述下载的文件备份一下,以后每次自己训练数据集的时候就不用再次下载了,直接改用。
训练自己的数据集
参考链接:https://www.cnblogs.com/answerThe/p/11481564.html
- 在darknet文件夹下新建一个
myData文件夹。将标注好的图片和xml文件放到对应目录下。运行test.py生成train.txt/val.txt/test.txt/trainval.txt文件。myData包含如下文件(夹):
myData
......JPEGImages #存放图像
......Annotations #存放图像对应的xml文件
......ImageSets/Main #存放训练/存放train.txt/val.txt/test.txt/trainval.txt文件
......test.py #生成train.txt/val.txt/test.txt/trainval.txt文件
test.py代码如下:
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
如果按照上述文件结构,则
test.py文件不需要修改,直接运行,即可生成txt文件。
- 将darknet文件夹下的scripts/voc_label.py拷贝出来,修改成
my_labels.py放在darknet文件夹中。【注意修改类别和路径】
运行该脚本my_lables.py会在./myData目录下生成一个labels文件夹一个txt文件(myData_train.txt)(内容是: 类别的编码和目标的相对位置)。
my_labels.py代码如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('myData', 'train'), ('myData', 'val'), ('myData', 'train'), ('myData', 'val'), ('myData', 'test')]
classes = ["person", "foot", "face"] # 改成自己的类别
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('myData/Annotations/%s.xml'%(image_id))
out_file = open('myData/labels/%s.txt'%(image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('myData/labels/'): # 改成自己建立的myData
os.makedirs('myData/labels/')
image_ids = open('myData/ImageSets/Main/%s.txt'%(image_set)).read().strip().split()
list_file = open('myData/%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/myData/JPEGImages/%s.jpg\n'%(wd, image_id))
convert_annotation(year, image_id)
list_file.close()
注意:这里面如果采用上述文件结构,只需要将classes改成自己的类别即可,其他内容不需要修改。
- 在
myData文件夹下新建myData.names文件。

- 在
myData文件夹下新建weights文件,用于保存生成的权重文件。 - 修改darknet/cfg下的voc.data和yolov3-voc.cfg文件。
复制这两个文件,并分别重命名为my_data.data和my_yolov3.cfg
(1)修改my_data.data:
classes= 4 #改为自己的分类个数
##下面都改为自己的路径
train = /home/zhan/darknet/myData/myData_train.txt
valid =/home/zhan/darknet/myData/myData_test.txt
names = /home/zhan/darknet/myData/myData.names
backup = /home/zhan/darknet/myData/weights
(2)修改my_yolov3.cfg:
Ctrl+F,搜出3个含有yolo的地方。每个地方都必须要改2处,filters 、classes
filters:3*(5+len(classes))
可修改:random = 1:原来是1,显存小改为0。(是否要多尺度输出。)
一般地,max_batches修改成合适的数值。
开始训练
参考链接:https://blog.csdn.net/csdn_zhishui/article/details/85397380
- 训练
首先,将cfg/my_yolov3.cfg文件中改成Training模式。
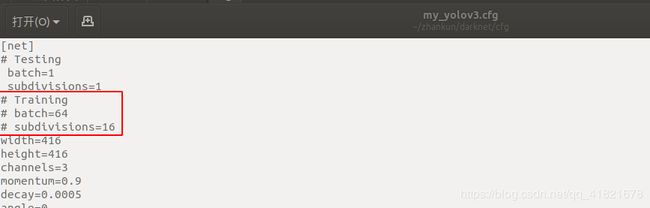
训练命令:
./darknet detector train cfg/my_data.data cfg/my_yolov3.cfg darknet53.conv.74
# 指定gpu训练,默认使用gpu0(查看GPU情况,`nvidia-smi`)
./darknet detector train cfg/my_data.data cfg/my_yolov3.cfg darknet53.conv.74 -gups 0,1,2,3
# 训练过程中保存训练日志xxx.log
./darknet detector train cfg/my_data.data cfg/my_yolov3.cfg darknet53.conv.74 | tee train_yolov3.log
# 断点继续训练
./darknet detector train cfg/my_data.data cfg/my_yolov3.cfg myData/weights/my_yolov3.backup | tee new_train_yolov3.log
训练日志可视化
vis_yolov3_log.py代码如下:
# -*- coding: utf-8 -*-
import pandas as pd
import matplotlib.pyplot as plt
import os
# ==================可能需要修改的地方=====================================#
g_log_path = "train_yolov3.log" # 此处修改为自己的训练日志文件名
# ==========================================================================#
def extract_log(log_file, new_log_file, key_word):
'''
:param log_file:日志文件
:param new_log_file:挑选出可用信息的日志文件
:param key_word:根据关键词提取日志信息
:return:
'''
with open(log_file, "r") as f:
with open(new_log_file, "w") as train_log:
for line in f:
# 去除多gpu的同步log
if "Syncing" in line:
continue
# 去除nan log
if "nan" in line:
continue
if key_word in line:
train_log.write(line)
f.close()
train_log.close()
def drawAvgLoss(loss_log_path):
'''
:param loss_log_path: 提取到的loss日志信息文件
:return: 画loss曲线图
'''
line_cnt = 0
for count, line in enumerate(open(loss_log_path, "rU")):
line_cnt += 1
result = pd.read_csv(loss_log_path, skiprows=[iter_num for iter_num in range(line_cnt) if ((iter_num < 500))],
error_bad_lines=False,
names=["loss", "avg", "rate", "seconds", "images"])
result["avg"] = result["avg"].str.split(" ").str.get(1)
result["avg"] = pd.to_numeric(result["avg"])
fig = plt.figure(1, figsize=(6, 4))
ax = fig.add_subplot(1, 1, 1)
ax.plot(result["avg"].values, label="Avg Loss", color="#ff7043")
ax.legend(loc="best")
ax.set_title("Avg Loss Curve")
ax.set_xlabel("Batches")
ax.set_ylabel("Avg Loss")
def drawIOU(iou_log_path):
'''
:param iou_log_path: 提取到的iou日志信息文件
:return: 画iou曲线图
'''
line_cnt = 0
for count, line in enumerate(open(iou_log_path, "rU")):
line_cnt += 1
result = pd.read_csv(iou_log_path, skiprows=[x for x in range(line_cnt) if (x % 39 != 0 | (x < 5000))],
error_bad_lines=False,
names=["Region Avg IOU", "Class", "Obj", "No Obj", "Avg Recall", "count"])
result["Region Avg IOU"] = result["Region Avg IOU"].str.split(": ").str.get(1)
result["Region Avg IOU"] = pd.to_numeric(result["Region Avg IOU"])
result_iou = result["Region Avg IOU"].values
# 平滑iou曲线
for i in range(len(result_iou) - 1):
iou = result_iou[i]
iou_next = result_iou[i + 1]
if abs(iou - iou_next) > 0.2:
result_iou[i] = (iou + iou_next) / 2
fig = plt.figure(2, figsize=(6, 4))
ax = fig.add_subplot(1, 1, 1)
ax.plot(result_iou, label="Region Avg IOU", color="#ff7043")
ax.legend(loc="best")
ax.set_title("Avg IOU Curve")
ax.set_xlabel("Batches")
ax.set_ylabel("Avg IOU")
if __name__ == "__main__":
loss_log_path = "train_log_loss.txt"
iou_log_path = "train_log_iou.txt"
if os.path.exists(g_log_path) is False:
exit(-1)
if os.path.exists(loss_log_path) is False:
extract_log(g_log_path, loss_log_path, "images")
if os.path.exists(iou_log_path) is False:
extract_log(g_log_path, iou_log_path, "IOU")
drawAvgLoss(loss_log_path)
drawIOU(iou_log_path)
plt.show()
可视化这部分除了需要将训练日志文件名修改成自己的,还要特别注意
skiprows=[iter_num for iter_num in range(line_cnt) if ((iter_num < 500))]和skiprows=[x for x in range(line_cnt) if (x % 39 != 0 | (x < 5000))]这两部分,需要根据自己的训练次数来设定的。
分别表示,迭代次数小于500次的跳过,画图不用,从501开始画图;每隔39个数或者前5000个数跳过,说白了就是,前5000个数值舍弃,从第5001个数开始,每隔39个数取一个数值参与画图。
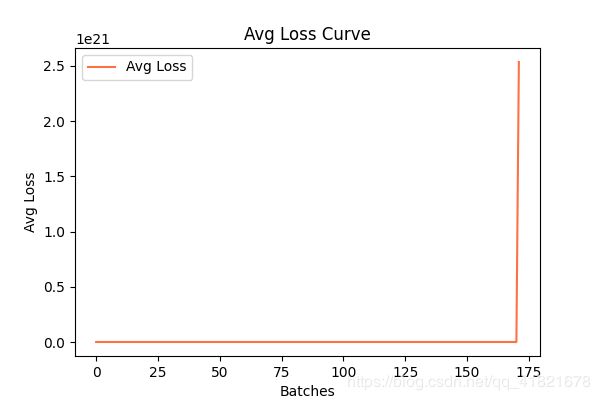
附录两张非常令人糟心的图(因为不知怎么地,它就失败了~~)