图像拼接现在还有研究的价值吗?有哪些可以研究的点?现在技术发展如何?

周末加班偷偷懒,先来回答一下,瞎说轻拍orz。
答案是当然有,图像拼接的第二春13年开始的,这里再简单总结和展望一下。
一个(全局)单应性对齐+柱面或球面投影+光束平差+多频带融合为核心的老一代拼接算法以BROWN大神03’ICCV和07’IJCV的AutoStitch AutoStitch为里程碑,已经非常成熟,各路拼接软件和应用都纷纷落地,著名的如OpenCV的实现stitcher http://stitching. Images stitching,微软的ICE,Image Composite Editor (64 bit) 和Photoshop中的拼接工具,某段时间图像拼接被认为是个已经完美解决的问题。
- Brown M, Lowe D G. Recognising Panoramas [C]// ICCV. 2003.
- Brown M, Lowe D G. Automatic Panoramic Image Stitching using Invariant Features [J]. IJCV, 2007.
这世界上从来没有完美,只有更好的算法。AutoStitch有两个必须满足的假设:
1) 是要求图像直接的重叠区域可以近似一个平面,整个图像近似一个平面效果更好;2) 是各次拍摄时相机光心近乎重合(其实可以合并为一个条件:重叠区域场景中没有深度变化)。如果不满足这两个假设,就会因为视差问题产生明显的伪影和对不齐(重影or模糊)。为了说明这个问题,跟我来做个小实验:假设电脑屏幕是背景,两个眼睛是两个相机(光心距约为6cm),伸出一根手指到眉心前10cm左右,闭起一只眼睛看手指,分别用左右眼看手指在屏幕中的位置会发现这个两个位置之间有间距,而且随着手指距离眼睛越近,这个间距也越大。这就是视差问题带来的图像拼接最大难点:一个单应性矩阵将场景中同一平面的像素点无缝对齐了,而位于其他平面的像素点却无法重合,这就是重影问题。
关于这个问题有两个解决办法:
- 是硬件方案。从问题根源出发,不就是光心不重合吗,那我们让相机光心重合不就好了。Panocast http://http://www.altiasystems.com 和FullView http://http://www.fullview.com就是这样做的。当然也可以再进一步回归问题本质,图片拼接就是为了获得更大视角,直接采用广角镜头,或者普通镜头加球面透镜,如GoPano http://http://www.gopano.com。硬件方案成本较高(子曰:单反穷三代,有了单反你才需要广角镜头)
- 是算法方案。算法方案成本更低,普通相机多次拍摄就能合成类似广角镜头的效果。
还是从问题根源出发,不就是一个全局单应性矩阵的对齐能力不够吗,那用更强力的矩阵或者更多个单应性矩阵不就好了。
故事是从11’CVPR的Dual-Homography Warping(DHW)开始的,将场景划分为背景平面和前景平面,用两个单应性矩阵(8参数变换矩阵,能把正方形变成任意四边形)分别对齐背景和前景,这种方法可以无缝拼接大部分现实场景了。
- Gao J, Kim S J, Brown M S. Constructing image panoramas using dual-homography warping [C]// CVPR, 2011.


既然两个单应性矩阵效果更好,那很多人就会想能不能用更多的矩阵呢?效果会不会更好呢?图像拼接第二春就是这么一步一步发展过来的。当然有人这么做了,答案也是肯定的。另一篇11’CVPR的Smoothly Varying Affine(SVA),用多个仿射变换(6参数的变换矩阵,经过仿射变换的平行线依然平行,能把正方形变成平行四边形),局部变形能力和对齐能力更强,具有一定处理视差的能力(自己和自己下棋,图像拼接这么玩确实挺炫的)。
- Lin W Y, Liu S, Matsushita Y, et al. Smoothly varying affine stitching [C]// CVPR, 2011.


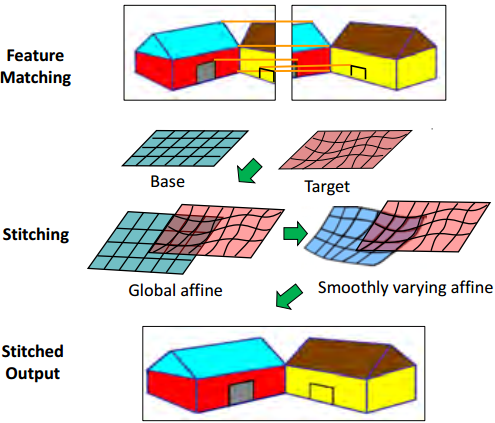
矩阵能不能更强一点呢?图像拼接第二春的里程碑算法,13’CVPR,14’PAMI的As-Projective-As-Possible(APAP)出现了,来自TJ CHIN大神组的工作,将图像划分为密集网格,每个网格都用一个单应性矩阵对齐,叫做局部单应性,并同时给出了一整套高效的计算方法Moving DLT,最最最重要的是公开了MATLAB代码.
- Zaragoza J, Chin T J, Brown M S, et al. As-projective-as-possible image stitching with moving DLT [C]// CVPR, 2013.
- Zaragoza J, Chin T J, Tran Q H, et al. As-Projective-As-Possible Image Stitching with Moving DLT [J]. TPAMI, 2014.
- source code: http://cs.adelaide.edu.au/~tjchin/apap/


至此,图像拼接的第二春开始了(春来发几枝-_-!),你可能会疑惑,不就是划分网格多个的局部单应性吗,有这么厉害吗?当然厉害啊,不过厉害的不是局部单应性,重点在于网格二字,重新看APAP算法,可以用一句话总结:网格变形!(汽车人请保持冷静,没说你们)。
我们需要先梳理一下派别,图像拼接属于计算机视觉问题(三大会议CVPR, ECCV, ICCV和两个顶刊IJCV, PAMI),而网格变形与优化相关的图像变形、尺寸缩放、重定向、视频去抖等问题都属于图形图像问题(顶会SIGGRAPH和顶刊ACM TOG)。虽然自古武功不外传,但就像某某高手,博采众家之长自成一派创立武功绝学一样,APAP打通了图像拼接和网格优化,马上就有人从网格变形联想到网格优化,用网格优化的方法来解决图像拼接问题。
14’CVPR的Parallax-tolerant Image Stitching Parallax-tolerant Image Stitchin, 借鉴经典视频去抖方法Content-preserving warps(CPW)的优化项和缝合线主导的13’Eurographics的Seam-driven,大幅提高了大视差场景的拼接性能。
- Zhang F, Liu F. Parallax-tolerant image stitching [C]// CVPR, 2014.
- source code: gain2217/Robust_Elastic_Warping
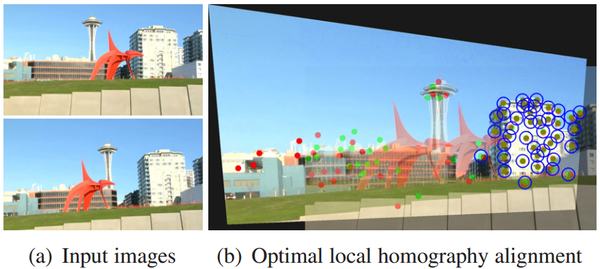
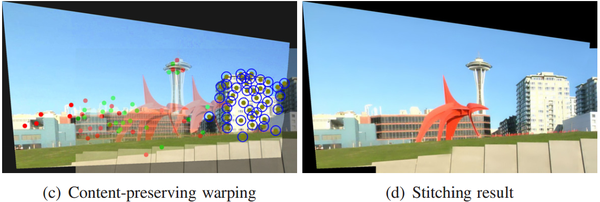
大视差场景拼接其实在Parallax-tolerant之前还有一篇Seam-Driven,用seam-cut 指导来估计最佳geometric transform:
- Gao J, Li Y, Chin T J, et al. Seam-Driven Image Stitching [C]// Eurographics (Short Papers), 2013.
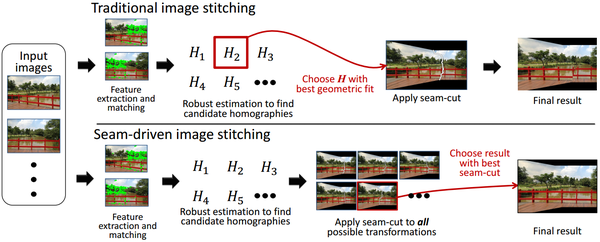
另一篇14’CVPR的Shape-Preserving Half-Projective(SPHP)从形状矫正的角度出发,借鉴图像缩放的Shape-Preserving类方法,非重叠区域逐渐过渡到全局相似变换(4参数的变换矩阵,能把正方形变成矩形),并对整个图像增加相似变换约束,矫正拼接图像的形状,减小了投影失真。
- Chang C H, Sato Y, Chuang Y Y. Shape-preserving half-projective warps for image stitching [C]// CVPR, 2014.
- source code: http://www.cmlab.csie.ntu.edu.tw/~frank/SPH/cvpr14_SPHP_code.tar
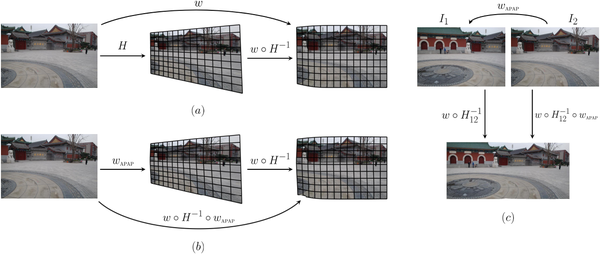
这两个方法的共同点是,给网格添加不同的约束项就能得到不同的效果,约束项让图像拼接进一步升华。如果3年前你就关注CV届,看到这个你肯定会眼前一亮,这可是灌水利器啊,过来人都依稀记得,在深度学习之前统治CV界的稀疏表示,换个约束项就是一篇文章(吐槽下,请不要痛恨遍地都是深度学习,至少深度学习还是work的,不怎么work的稀疏表示曾经也这样泛滥过,养育了一批科研人员)。更致命的是,除了网格优化可以加约束项,常用的最优缝合线(seam-cutting)的图割也是个优化问题,也可以加优化项,更好更找出缝合线也是一个方向。(人家也上有老下有小,水水文章无可厚非)好文章并且真真实实work的工作还是有的,再用一首歌的时间,快速浏览一下那些值得follow的拼接算法:
15‘CVPR的Adaptive As-Natural-As-Possible(AANAP),同样是形状矫正问题,自适应确定角度,同样用全局相似变换矫正形状,IBM出品(大牛很冷漠,没有回我邮件~_~),没有落约束项的俗套,质量杠杠的,拼接结果的观感自然度比SPHP提升了一个档次。
- Lin C C, Pankanti S U, Ramamurthy K N, et al. Adaptive as-natural-as-possible image stitching [C]// CVPR, 2015.
- source code: YaqiLYU/AANAP

16’ECCV的Global Similarity Prior(GSP) Natural Image Stitching with the Global Similarity Prior,直线对齐约束确定全局相似矩阵的角度选择,用APAP初始化网格,约束项方面同时使用局部相似约束和全局相似约束,多图拼接性能和观感自然度提升。
- Chen Y S, Chuang Y Y. Natural Image Stitching with the Global Similarity Prior [C]// ECCV, 2016.
- source code: nothinglo/NISwGSPnothinglo/NISwGSP

16‘ECCV的Seam-guided Local Alignment(SEAGULL) Image Stitching Project 在Parallax-tolerant Image Stitching算法的基础上,改进Seam-driven,轮廓检测和直线检测,加入了曲线和直线结构保持约束项的结构保持绘制,确实提升很明显。
- Lin K, Jiang N, Cheong L F, et al. SEAGULL: Seam-Guided Local Alignment for Parallax-Tolerant Image Stitching [C]// ECCV, 2016.


用网格优化来解决图像拼接问题,等价于每个局部单应性矩阵互相独立单独优化,具有更大的自由度,上面几篇论文也能看出来更大的自由度能兼顾的更多,拼接结果更加准确自然。图像拼接大家都在玩大视差的拼接,玩到有点过分了,为了显示算法对其能力的强悍,图像视差大的不可理喻之外,重叠区域也是几乎整个图像,虽然这样没什么实际意义,但对齐能力的提升才是这些过分玩法的基础。其实想怎么玩都可以,图像/视频是一个比较务实的方向,水水论文毕业可以做相关产品的落地。
/************************我是分割线**************************/
再扯扯,又一个VR元年过去了,除了AR火了一把,VR还是安安静静的发展,作为VR技术的核心之一,图像拼接是很有市场的。如果要发顶级文章又怕只做图像拼接做不过各大团队,紧紧围绕VR去做也是可以的,这里再介绍两条路:
视频拼接:VR很需要拼接效果好还能在线实时拼接的算法,价格下来体验上去才能飞入寻常百姓家(看到VR上GTX我表示心累,不热也贵啊)。难点主要有:除了图像拼接中的视差问题,还有前景移动物体穿越相机时的重影和不连续。背景建模类方法速度快但效果差,大视差前景物体难以处理;逐帧拼接类效果好,但速度慢,不考虑空域就会有抖动。
目前比较热的做法是把视频拼接和视频稳定(去抖)一起做,可以做高质量离线拼接,也可以做在线实时拼接,都是有市场和实际应用需求的。如果真的做的好有重大突破,收收专利费过好下半生不会问题~~
这些离线逐帧拼接方法和视频稳定一起玩,效果可以做的很好,加约束项依然行得通,但复杂度嘛,呵呵。。在线实时还没有很work的方案,如果对这个问题感兴趣欢迎讨论。再来做个实验吧:(那我懂你的意思了,原句引用)以人的左右眼成像为例。摆一根手指在眼前,人解决大视差的观看方式是让它重影吧,主要保证大视野信息的完整性。非要看清手指那就只好斗鸡眼了(斗鸡眼-_-!)。。。说说个人做实时在线视频拼接的相关项目的经验吧:
- 融合方法选择:Multi-band blending(多频带)可以处理小视差,但复杂度还是太高了,尤其是图像分辨率较高的时候,如果是写论文追求极限效果那就Multi-band,如果计算资源有限还是推荐Feather blending(渐进渐出)方法,这两个方法都可以和seam-cutting结合。
- 比较有效的策略是背景建模+逐帧前景移动物体检测,检测到了就更新seam(缝合线方法,graphcut),没有检测到就保持之前的seam,可以在处理视差的同时保持前景物体不模糊、连续,但seam-cutting方法的复杂度较高,很小分辨率也难以实时处理,这种做法的缺点是有前景物体经过时帧率会大幅下降,如果计算资源足够可以用这种方法,或者优化seam-cutting类方法的速度。
再用一首歌的时间推荐几篇文章:
15年一作华科的Parallax-Robust Surveillance Video Stitching,虽不能算顶尖工作的代表,也可以作为在线视频拼接的范例,适用环境是类监控场合,特点是相机位置和背景都保持不变,套路基本都类似:
- 用背景帧(第一帧)初始化拼接模板;
- 检测是否有前景物体经过融合区域,或经过缝合线;
- 如果有,更新缝合线和拼接模板,再按照新模板拼接;
- 如果没有,按照前一帧的拼接模板直接拼接。
- He B, Yu S. Parallax-Robust Surveillance Video Stitching[J]. Sensors, 2015.
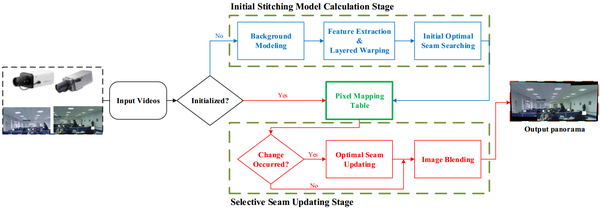
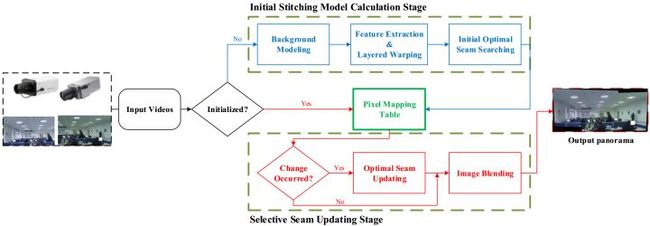
15’CVPRW的Spatial-Temporal Content-Preserving Warping(STCPW),华为出品,加时空域约束项,时空块3D缝合线搜索是创举,但拼接速度未知(做视频拼接的文章不提拼接速度是要闹哪样啊),想想就慢的要死。
- Jiang W, Gu J. Video stitching with spatial-temporal content-preserving warping[C] // CVPRW, 2015.


16’EUROGRAPHICS(CGF出版)的Seamless Video Stitching from Hand-held Camera Inputs Video Stitching Project 也是SEAGULL的作者做的,密集3D重建,约束项与SEAGULL类似,拼接效果真的很赞,听说一帧就要几分钟。。。
- Lin K, Liu S, Cheong L F, et al. Seamless Video Stitching from Hand-held Camera Inputs [C] // CGF, 2016.


16‘TIP的Joint Video Stitching and Stabilization http://Joint Video Stitching and Stabilization From Moving Cameras,以视频稳定为主,加入视频拼接约束项,算是上一篇的改进,速度快了很多,文中自己说720p视频2fps。
- Guo H, Liu S, He T, et al. Joint Video Stitching and Stabilization From Moving Cameras[J]. TIP, 2016.
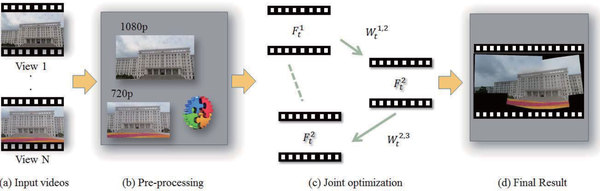
立体图像拼接:VR的沉浸现实感很需要3D帮忙,这样体验才能提高一个档次(3D电影看多了公民的品味高了,2D已经无法满足大众口味)。立体图像和立体视频拼接也是可以做的(立体也是灌水利器-_-!),立体图像拼接推荐15‘CVPR的Casual Stereoscopic Panorama Stitching,立体视频暂时还没有看到相关创新工作。
- Zhang F, Liu F. Casual stereoscopic panorama stitching [C]// CVPR, 2015.


/************************我是分割线********************/
再次回到图像拼接问题,按照主流算法先来给图像拼接划分几个小方向:
- 全局对齐方法(Global
alignment):以一个单应性矩阵对齐图像,前面介绍过了,以AutoStitch为代表,适合没有视差或极小视差的场景(仅重叠区域也可以,下同); - 空域变化绘制方法(Spatially-varying warping):目前的主流,以局部单应性或网格优化变形为主,以APAP为代表,适合场景视差较小的情况。相关论文有:13’CVPR,14’PAMI的APAP,14’CVPR的SPHP(源码仅给了SPHP,没有SPHP+APAP的实现),15’CVPR的AANAP,16’ECCV的NISwGSP。
- 缝合线主导方法(Seam-driven):也是主流之一,缝合线(seam-cutting)是处理视差的另一法宝,这类方法以缝合线为主导,不用严格对齐整个重叠区域,而是仅对齐缝合线附近的区域,以Parallax-tolerant为代表,这类方法可以拼接大视差场景。相关论文有13’Eurographics的Seam-driven, 14’CVPR的Parallax-tolerant, 16’ECCV的SEAGULL。
- 小结一下我们提到的对视差有效的部件:Spatially-varying warping, Seam-cutting,Multi-band blending.
马克思告诉我们,事物都有两面性,Spatially-varying warping类方法看起来这么完美,这不科学啊。幸好这里不是论文只说好处不提缺点,咱们大大方方来谈谈这些方法的缺点和相关解决方案,工业界最看重实用性,同时也希望学术节能提出一些高效的解决方案。
- 计算速度慢。这个显而易见,计算一个单应性矩阵VS多个局部单应性矩阵,结果不言而喻,即使APAP方法给出了加速计算的办法,但也只是勉强可以接受,更别说网格优化类方法,优化网格还要根据网格指导图像绘制,单做图像拼接还可以接受,如果扩展到视频拼接,即使低分辨率图像30fps也还只是个梦想(I have a dream,4K视频也能60fps拼接)。
- 更多的超参数。APAP方法中至少有三个超参数需要调整(内点阈值,高斯核参数,offset值),而网格优化类方法,至少各约束项之间的相对权重需要调整,还有其他乱七八糟一大堆。虽然超参数可以让我们根据实际需求自行调节,但我们还是乐于看到参数自适应选择,而且比较稳定鲁棒的方法,调参累成狗(提到超参数,做深度学习的同学可能深有感触,男人哭吧哭吧不是罪)。
- 内点要求更高。Global alignment类只需要求解一个全局单应性矩阵,理论上有4对内点就可以解出8个模型参数,而Spatially-varying warping方法如APAP、Parallax-tolerant非常依赖特征点,对匹配特征内点的数量和质量要求都更高,图像局部的视差信息完全由匹配特征点来提供,最理想情况是:匹配特征内点能较密集的均匀分布在重叠区域。下面详细分析这个问题。


- 数量问题:这个问题是关于特征点检测的,就像上图,上面一列是普通情况下各种特征点检测算法,经典的SIFT,加速的SURF,免费的ORB等等(对用破解软件玩破解游戏长大的我来说,SIFT和SURF算法的最大缺点不是速度和检测率,而是收费),在纹理复杂区域特征点较多,但纹理较少的平坦区域,特征点数量就非常少,匹配到的内点就更少了,这就很尴尬了。也许有人认为纹理少的区域不对齐也看不出来,可在纹理规则的区域任何不对齐都是致命的(图b的地面纹理)。图中下面一列是某篇文章的改进结果。
- 质量问题:这个问题是关于特征点匹配和滤除外点的,经典方法是FLANN匹配+Bestof2滤点+RANSAC滤点,问题出在RANSAC,Global alignment类方法的内点阈值非常小,可以保证内点都是正确匹配的点对,而Spatially-varying warping类方法设置比较大的内点阈值才能保证有视差(位于不同平面)的匹配点不被滤掉,通常是全局阈值的10~100倍,如果这时候的内点有错误匹配点,拼接结果就会有严重错误。
就像下图这种情况,特征点都集中在建筑物上,而天空部分特征点很少,这部分就很难对齐。再仔细看天空中的内点,大阈值RANSAC后的内点还是包含明显的错误匹配点,拼接结果就不放出来了,实在不忍心~~Spatially-varying warping类方法完全是靠特征内点来建模局部视差的,所有视差对齐信息都来自特征内点对(民以食为天)。

关于提高内点数量和质量的重要性学术界当然也注意到了,上面的文章也都多多少少做了研究和改进。也有专门针对这个问题研究的文章,或者加入新类型特征,或者提高特征点质量和数量等,这再用一首歌的时间介绍几个不错的工作:
也许有人注意到16’ECCV的两个工作都用到了直线,一篇用直线对齐找全局相似变换的最佳角度,另一篇用了直线结构保持的绘制,其实早在15年就有两个直线相关的图像拼接工作。15‘ICCV的Dual-Feature Warping(DFW),由香港科技大学和微软联合出品,给出了一整套线段特征检测、匹配和RANSAC的方法,作为补充结合点特征一起用,思路就很厉害了,效果自然不会差。
- Li S, Yuan L, Sun J, et al. Dual-feature warping-based motion model estimation [C]// ICCV, 2015.
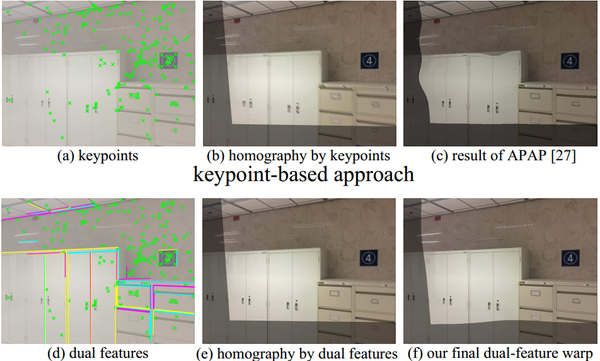

同年15’ICIP的Line meets As-Projective-As-Possible(L-mDLT),与上一篇类似,扩展APAP的MovingDLT,给出了一个点特征和线特征结合的APAP图像拼接框架。但这两个15年的工作对特征线段的处理套路类似特征点,比较直接,而16年的两个工作将直线作为约束项,这样复杂度要低很多。
- Joo K, Kim N, Oh T H, et al. Line meets as-projective-as-possible image stitching with moving dlt [C]// ICIP, 2015.
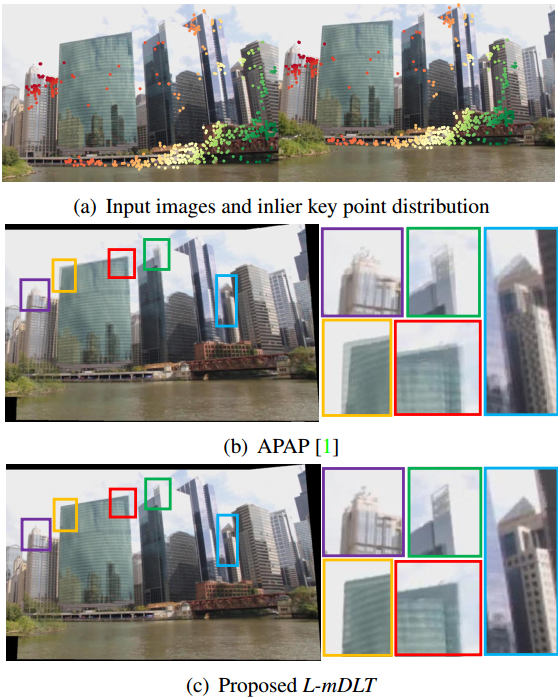

线特征作为点特征的补充对拼接效果的提升很明显,但随之带来的计算复杂度提升也是很可观的。TJ CHIN大神组不就前在16‘arXiv挂出来的方法Correspondence Insertion for As-Projective-As-Possible(APAP+CI),自动识别未对齐区域,在这些区域对应插入匹配点,没仔细看过就不做评价了。
- Liu W X, Chin T J. Correspondence Insertion for As-Projective-As-Possible Image Stitching[J]. arXiv:1608.07997, 2016.

最后,再来聊聊图像拼接怎么和最近很热的深度学习拉关系。图像拼接天然就和VR渊源很深,如果再和深度学习拉上关系,那就不愁文章投不出去,而且深度学习的强大也已经得到了广泛认可,如果能借助深度学习解决以上难题也算是功德一件。我也非常希望能看到更好更实用还免费的新算法代替SIFT/SURF,但新算法要经过学术界的批判和不断改进,工业界的检验和加速优化,才能创造价值(打是亲骂是爱,千锤百炼)。深度学习的网络结构基本固定,做图像拼接相关问题最需要关注的是训练样本和损失函数(如匹配特征点label怎么标注,端到端训练图像拼接ground truth应该怎么给定),再用一首歌的时间,以两篇相关文章为例,来了解和评估一下Deep ConvNet在图像拼接相关邻域的表现。
16’ECCV的Learned Invariant Feature Transform(LIFT) cvlab-epfl/LIFT,将以下三个分别用深度学习做特征点的检测、方向分配和描述子生成的工作结合,end-to-end训练:
- Verdie Y, Yi K M, Fua P, et al. TILDE: A Temporally Invariant Learned DEtector, CVPR, 2015.
- Yi K M, Verdie Y, Fua P, et al. Learning to Assign Orientations to Feature Points, CVPR, 2016.
- Simo-Serra E, Trulls E, Ferraz L, et al. Discriminative learning of deep convolutional feature point descriptors, ICCV, 2015.
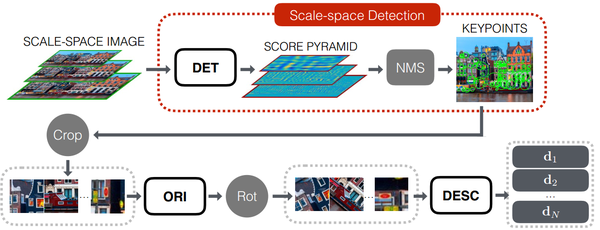
网络结构是3个CNN分别进行检测、方向、描述(好失望,真的是3合1)。深度学习我们最关心的大量训练样本哪里来?意料之中不是人工标注,而是基于SIFT,是SfM重建过程中所用的特征点(原文the feature points that survive the SfM reconstruction process),LIFT在训练阶段的输入是以特征点为中心的小块。测试阶段,多尺度图像输入,滑窗形式特征点检测,之后提取小块逐个分配方向,计算描述子。速度未知,文章没提(猜猜看3个CNN有多快),虽然端到端训练是优势,但训练数据由算法产生,必然会继承SIFT和SfM的缺点(学习雷锋好榜样的必要性),尺度不变性通过多尺度输入获得,光照不变性应该还不错,作者自己说了旋转不变性很差,有兴趣可以跑跑下代码实测效果!
- Yi K M, Trulls E, Lepetit V, et al. Lift: Learned invariant feature transform [C]// ECCV, 2016.
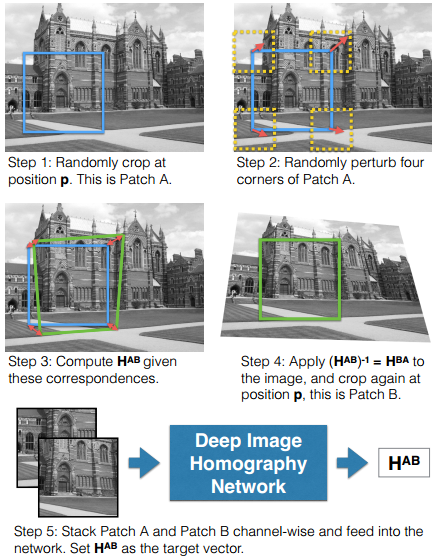
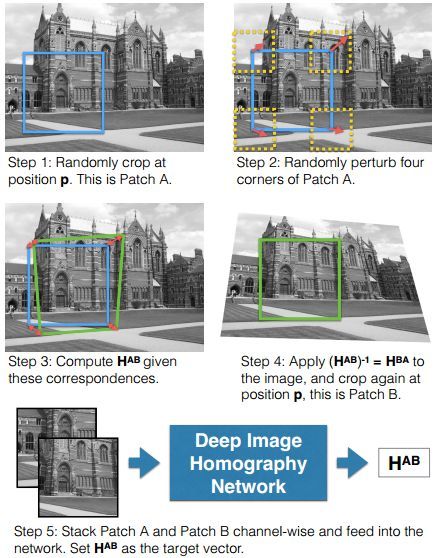
16‘arXiv挂出来的Deep Image Homography Estimation, 提出HomographyNet的用一个类VGG的10层CNN直接从输入图像对,回归预测单应性矩阵的8个参数。听起来很美好,但还是要友情提示,论文投的不是计算机视觉顶会,而是RSS Workshop on Limits and Potentials of Deep Learning in Robotics 2016(机器人领域顶会感谢知友告知),但想法新颖,有参考价值。虽然Titan X(深度学习,贫民退散)上300fps,但输入太小了没有参考意义,再来看看我们最关心的训练数据还是算法生成的,原图像和投影变换后图像同一点裁小块就是两个输入,相应投影变换就是label。两输入的内容几乎一样,完全没有实际问题中的光照、视差和噪声等因素,而且测试也是这么生成的图像对,算法真实效果和实用价值待定,认真你就输了。
- DeTone D, Malisiewicz T, Rabinovich A. Deep image homography estimation [J]. arXiv:1606.03798, 2016.
- CNN生成描述子类似人脸验证,相关文章挺多,可以跟踪一下,参考和借鉴。如果能通过CNN做到特征内点密集、均匀分布于重叠区域,Spatially-varying warping类方法的实用性就能进一步提高,或者更进一步,图像拼接问题直接通过end-to-end训练解决了那就更好了,上面介绍的文章已经说明CNN的无限可能性。但仅目前来看,CNN在产品落地难度还是非常非常大的,实时检测和拼接基本不做奢望(路漫漫其修远兮)。
/**********************我是分割线************************/
前不久有首PPAP很火,有没有觉得和APAP很像,这里就给PPAP配上图像作为结束,ENDING!
I have a pen,I have an apple.Apple-pen!
I have a pen,I have pineapple.Pineapple-pen!
Apple-pen~Pineapple-pen.Pen-Pineapple-Apple-pen!


- 重要说明:以上内容仅是对近两年领域内论文的粗略分析概括,不涉及任何公司内部资料和信息。难免疏漏和错误,希望您仔细甄别,以原作者论文和代码为准。最后,感谢您看完,欢迎探讨。