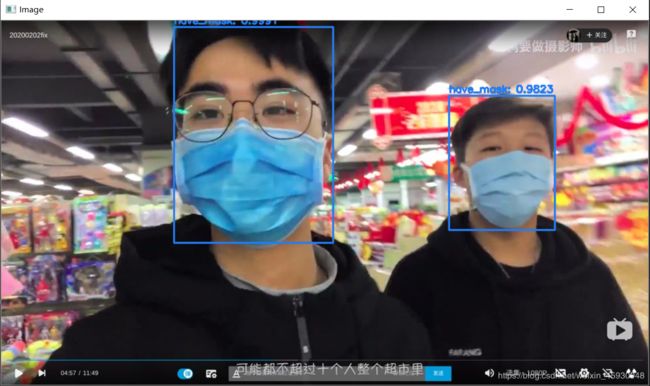
opencv调用自己训练的yolo3模型
一 实现流程
1.准备好自己的数据集,通过yolo3结构框架训练好自己的模型文件(loss值一般训练到10就OK)yolov3源码:https://github.com/qqwweee/keras-yolo3
2.基于keras框架训练出来的模型是.h5格式的文件。把.h5格式的文件转化为darknet形式的.weight文件。
.h5转换成.weight资源:https://download.csdn.net/download/qq_20265187/10973085?ops_request_misc=&request_id=&biz_id=103&utm_source=distribute.pc_search_result.none-task-download-2allsobaiduweb~default-1
3.通过opencv.dnn模块实现对模型的调用。opencv( 3.4.2+版本)的dnn(Deep Neural Network-DNN)模块封装了Darknet框架,可以使用opencv方便地使用yolo的各个版本。把模型解码成预测图片所需要的坐标点和分类及置信度,并标注出来。
二 训练模型
在训练是时候可以添加限制GPU的使用率,防止显存不够。
config = tf.ConfigProto()
config.gpu_options.allocator_type = 'BFC' #A "Best-fit with coalescing" algorithm, simplified from a version of dlmalloc.
config.gpu_options.per_process_gpu_memory_fraction = 0.6 # 显存利用率60%
config.gpu_options.allow_growth = True # 动态显存申请
set_session(tf.Session(config=config))先创建数据集格式。
JPEGImages:存放目标图片
Annotations:存放标注好的XML文件,需与图片名称相对应
ImageSets/main:生成一个txt格式文件,里面存放需要训练的图片名称
训练好的yolo.h5文件转化成yolo.weight文件
![]()
![]()
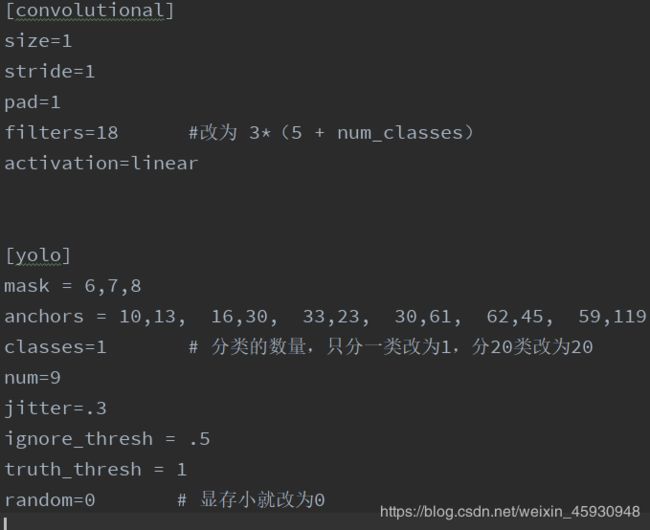
然后修改draknet网络结构yolov3.cfg格式文件。
按Ctrl+F在文件内查找‘yolo’(有3处,分别是每个特征层的输出),需要修改filters,classes,random三个地方。
三 调用opencv.dnn加载网络结构
参考:https://blog.csdn.net/qq_32761549/article/details/90402438
import cv2
import numpy as np
import time
start = time.time()
with open('./model/coco.names','r') as file:
LABELS = file.read().splitlines() #变为列表形式['person', 'bicycle', 'car']
COLORS = np.random.randint(0, 255, size=(len(LABELS), 3), dtype="uint8")
args = {
"image": "0497.jpg",
"confidence": 0.5, # minimum bounding box confidence
"threshold": 0.3, # NMS threshold
}
weightsPath = './model/yolo.weights'
configPath = './model/yolov3.cfg'
image = cv2.imread(args['image'])
(H, W) = image.shape[:2]
#将图像转化为输入的标准格式
#对原图像进行像素归一化1/255.0,缩放尺寸 (416, 416),,对应训练模型时cfg的文件 交换了R与G通道
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (416, 416),swapRB=True, crop=False)
net = cv2.dnn.readNetFromDarknet(configPath,weightsPath) #加载模型权重文件
net.setInput(blob) #将blob设为输入
ln = net.getUnconnectedOutLayersNames() #找到输出层 draknet中有三个输出层‘yolo_82’, ‘yolo_94’, ‘yolo_106’
layerOutputs = net.forward(ln) # ln此时为输出层名称,向前传播,得到检测结果
'''''
解码过程,就是对检测结果进行处理与显示
在检测结果中会有很多每个类的置信度为0的矩形框,要把这些与置信度较低的框去掉
'''''
boxes, confidences, classIDs = [], [], []
for output in layerOutputs: #对三个输出层 循环
for detection in output: #对每个输出层中的每个检测框循环
# [5:] 代表从第6个开始分割
scores = detection[5:] #detection=[x,y,h,w,c,class1,class2,class3,class4。。。。。。]
classID = np.argmax(scores) #找出最大值的索引,即哪一类是最大值
confidence = scores[classID] #得到置信度的最大值
#根据置信度筛选
if confidence > args['confidence']:
# 得到box框的(x,y,h,w)
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int")
# 把预测框中心坐标转换成框的左上角坐标(x,y)
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
classIDs.append(classID)
# 提取出来的框有重复,所以要进行非极大值抑制处理
#[1.需要操作的各矩形框 2.矩形框对应的置信度 3.置信度的阈值,低于这个阈值的框直接删除 4.NMS的阈值]
idxs = cv2.dnn.NMSBoxes(boxes, confidences, args["confidence"],args["threshold"])
print('idxs形状为:',idxs.shape)
if len(idxs) > 0 :
for i in idxs.flatten():# indxs是二维的,第0维是输出层,所以这里把它展平成1维
(x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
color = [int(c) for c in COLORS[classIDs[i]]]
cv2.rectangle(image,(x,y),(x+w,y+h),color,2)
text = "{}: {:.4f}".format(LABELS[classIDs[i]], confidences[i])
cv2.putText(image, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX,0.5, color, 2)
print('程序运行时间:', time.time() - start,'秒')
cv2.imshow('Image',image)
cv2.waitKey(0)运行结果: