前言
由于我司的系统已存在稳定的Hive on Hadoop集群以及Spark集群,随着业务发展,需要打通这两者,并能方便大家在其上进行开放,于是有了本文。本文实际是关于"Hive with Spark" 的,因为本文着重点在于阐述Hive与Spark的关系,并提供了在不改变当前已有的Spark、Hive、Hadoop系统的情况下打通各系统的调用方式,方便系统过渡,最后给出升级到Hive on Spark所需工作。
集群环境
本文采用Hadoop2.5,Spark2.1,Hive1.2.2(需Hive0.13.1版本以上),以及4台虚拟主机来组成集群环境。具体安装本文不再做过多阐述,可以参考网上安装集群文章。
Hive 概述
Apache Hive是一种建立在Hadoop文件系统上的数据仓库架构软件,并能对存储在HDFS中的数据进行分析和管理。
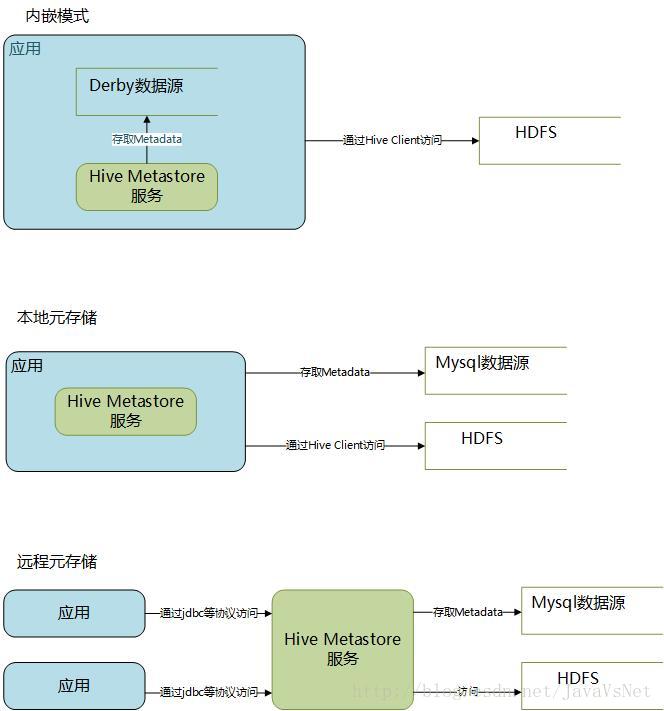
关于Hive的架构配置,关键是需要弄懂两个概念:Metadata,Metastore。
Metadata即元数据。元数据包含用Hive创建的database、tabel等的元信息。元数据存储在关系型数据库中。如Derby、MySQL等。
Metastore的作用是:客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore服务即可。
连接Hive的架构就主要有三种,分别是:
内嵌模式,使用的是内嵌的Derby数据库来存储元数据,也不需要额外起Metastore服务。这个是默认的,配置简单,但是一次只能一个客户端连接,适用于用来实验,不适用于生产环境。
本地元存储,和远程元存储都采用外部数据库来存储元数据,目前支持的数据库有:MySQL、Postgres、Oracle、MS SQL Server.在这里我们使用MySQL。
远程元存储,和本地元存储的区别是:本地元存储不需要单独起Metastore服务,用的是跟hive在同一个进程里的metastore服务。远程元存储需要单独起Metastore服务,然后每个客户端都在配置文件里配置连接到该metastore服务。远程元存储的Metastore服务和hive运行在不同的进程里。
具体可参考:Hive官网Wiki、Hive安装配置指北
Spark SQL 概述
从底层来说,Spark SQL经历了三步:读入数据 -> 对数据进行处理 -> 写入最后结果。主要涉及三个类:读入数据和写入最后结果用到两个类HiveContext和SQLContext,对数据进行处理用到的是DataFrame类。
对于HiveContext和SQLContext,Spark2.0已做了很好的封装,我们只需要通过设置SparkConf(Spark参数集,可控制Spark所有行为包括是否启用Hive),然后使用SparkSession.sql方法即可让Spark底层帮我们自动切换两者。
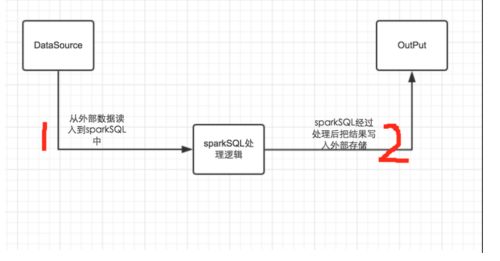
具体框架可以参考sparkSQL的整体实现框架。
方案比较
方法一,功能有限,不适用。
方法二,可以无需在代码中配置jdbc等连接参数,且做到代码中直接使用SparkSession.sql方式即可访问开发,测试,生产环境。
方法三,需要额外部署Metastore服务,且如果使用service hive-metastore start方式启动则因其为单线程的,只能同时处理一个请求,如采用hive --service hiveserver2 方式启动,虽然能支持多线程响应,但需要加入jdbc等方式的连接代码。
为降低开发,降低调试、部署等步骤的复杂度,我们将采用Hive metastore本地元存储方式。
代码与配置
一、 Hive 的配置主要围绕hive-site.xml,在spark集群中(假设读者已有可用的spark集群),则需将该文件放置到所有机器上的$SPARK_HOME/conf/目录下。具体实例如下:
spark.sql.warehouse.dir
hdfs://HOSTNAME:9000/apps/svr/hive-0.13.1-cdh5.3.2/warehouse
hive.exec.scratdir
/apps/svr/hive-0.13.1-cdh5.3.2/tmp
hive.querylog.location
/apps/svr/hive-0.13.1-cdh5.3.2/log
javax.jdo.option.ConnectionURL
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
user
javax.jdo.option.ConnectionPassword
password
...
以上内容,只需将
二、修改$SPARK_HOME/conf/spark-env.sh,添加
export SPARK_DIST_CLASSPATH=$(/apps/svr/hadoop-2.5.0-cdh5.3.2/bin/hadoop classpath)
此外还需保证Class Path中包含mysql的驱动jar包mysql-connector-java-5.1.22.jar,如hadoop中本来就配置有该引用路径即可不配,否则需添加
export SPARK_CLASSPATH=$SPARK_CLASSPATH:/apps/svr/extLibs/mysql-connector-java-5.1.22.jar
三、如在Eclipse开发环境中使用本地模式(local[*])进行调试时,需在代码中增加Spark参数:
sparkConf.set("spark.sql.warehouse.dir", "hdfs://HOSTNAME:9000/apps/svr/hive-0.13.1-cdh5.3.2/warehouse/");
sparkConf.set("javax.jdo.option.ConnectionURL", "jdbc:mysql://10.199.244.19:3306/hive_spark?characterEncoding=UTF-8")
.set("javax.jdo.option.ConnectionDriverName", "com.mysql.jdbc.Driver")
.set("javax.jdo.option.ConnectionUserName", "user")
.set("javax.jdo.option.ConnectionPassword", "password");
除了硬代码方式外,也可以通过将hive-site.xml 文件放到src/main/resources或src/test/resources(使用junit等测试方式时生效)上实现相同效果,但这样容易不小心将该文件也打包到测试或生产环境,就可能覆盖了spark集群本身的hive-site.xml 文件,从而导致错误。
四、 Maven打包时需注意将hive包导入,这里使用Provided用于展示本地调试所需,且注意其版本号需与scala版本一致,否则可能导致运行不成功:
org.apache.spark
spark-hive_${scala.binary.version}
${spark.version}
provided
org.slf4j
slf4j-log4j12
Hive on Spark 改造
至此我们只需围绕配置hive-site.xml 则可顺利通过Spark分配Sql到Hive on Hadoop上执行,那我们进一步会问是否可以直接使用Spark 在Hive上执行Sql呢(即 Hive on Spark)?答案自然是可以的,但需要重新安装Spark系统 ,Spark官方提供的预编译版本,通常是不包含Hive支持的,需要采用源码编译,编译得到一个包含Hive支持的Spark版本。这块坑较多,有兴趣的同学可使用该文Spark2.1.0入门:连接Hive读写数据(DataFrame)提供的Spark安装包直接使用。