Hive1.2.1
pom:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.neu.edugroupId>
<artifactId>UDFartifactId>
<version>1.0-SNAPSHOTversion>
<dependencies>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-execartifactId>
<version>1.2.1version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.8.0version>
dependency>
dependencies>
project>1.UDF
参考:https://cwiki.apache.org/confluence/display/Hive/HivePlugins
实现大小写转换
事先创建好people表:
CREATE TABLE `people`(
`name` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
WITH SERDEPROPERTIES (
'escape.delim'=' ')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://172.17.11.85:9000/user/hive/warehouse/people'
TBLPROPERTIES (
'COLUMN_STATS_ACCURATE'='true',
'numFiles'='1',
'totalSize'='48',
'transient_lastDdlTime'='1498961850')新建Maven项目,然后新建类:
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
/**
* @version 2017/7/2.10:07
*/
public class ULower extends UDF {
public Text evaluate(final Text s) {
if (s == null) {
return null;
}
return new Text(s.toString().toLowerCase());
}
}
之后打包,上传到Linux集群中任何一个地方,
进入hive CLI:
add jar /root/UDF-1.0-SNAPSHOT.jar;
list jars;
create temporary function my_lower as 'ULower';
select my_lower(name) from people;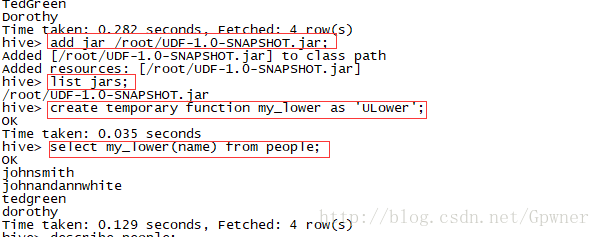
删除UDF:DROP FUNCTION [IF EXISTS] function_name;
2.UDAF:
参考:https://cwiki.apache.org/confluence/display/Hive/GenericUDAFCaseStudy
求和
public static enum Mode {
PARTIAL1, //从原始数据到部分聚合数据的过程(map阶段),将调用iterate()和terminatePartial()方法。
PARTIAL2, //从部分聚合数据到部分聚合数据的过程(map端的combiner阶段),将调用merge() 和terminatePartial()方法。
FINAL, //从部分聚合数据到全部聚合的过程(reduce阶段),将调用merge()和 terminate()方法。
COMPLETE //从原始数据直接到全部聚合的过程(表示只有map,没有reduce,map端直接出结果),将调用merge() 和 terminate()方法。
};
getNewAggregationBuffer():返回存储临时聚合结果的AggregationBuffer对象。
reset(AggregationBuffer agg):重置聚合结果对象,以支持mapper和reducer的重用。
iterate(AggregationBuffer agg,Object[] parameters):迭代处理原始数据parameters并保存到agg中。
terminatePartial(AggregationBuffer agg):以持久化的方式返回agg表示的部分聚合结果,这里的持久化意味着返回值只能Java基础类型、数组、基础类型包装器、Hadoop的Writables、Lists和Maps。
merge(AggregationBuffer agg,Object partial):合并由partial表示的部分聚合结果到agg中。
terminate(AggregationBuffer agg):返回最终结果。Java code
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.parse.SemanticException;
import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFParameterInfo;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
/**
* @version 2017/7/2.10:43
*/
public class SumUDAF extends AbstractGenericUDAFResolver {
static final Log LOG = LogFactory.getLog(SumUDAF.class.getName());
@Override
public GenericUDAFEvaluator getEvaluator(GenericUDAFParameterInfo info) throws SemanticException {
return new TotalNumOfLettersEvaluator();
}
public static class TotalNumOfLettersEvaluator extends GenericUDAFEvaluator {
PrimitiveObjectInspector inputOI;
ObjectInspector outputOI;
PrimitiveObjectInspector integerOI;
int total = 0;
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters)
throws HiveException {
assert (parameters.length == 1);
super.init(m, parameters);
// init input object inspectors
if (m == Mode.PARTIAL1 || m == Mode.COMPLETE) {
inputOI = (PrimitiveObjectInspector) parameters[0];
} else {
integerOI = (PrimitiveObjectInspector) parameters[0];
}
// init output object inspectors
outputOI = ObjectInspectorFactory.getReflectionObjectInspector(Integer.class,
ObjectInspectorFactory.ObjectInspectorOptions.JAVA);
return outputOI;
}
/**
* class for storing the current sum of letters
*/
static class SumBuffer implements AggregationBuffer {
int sum = 0;
void add(int num) {
sum += num;
}
}
@Override
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
SumBuffer result = new SumBuffer();
return result;
}
@Override
public void reset(AggregationBuffer agg) throws HiveException {
SumBuffer myagg = new SumBuffer();
}
@Override
public void iterate(AggregationBuffer agg, Object[] parameters)
throws HiveException {
assert (parameters.length == 1);
if (parameters[0] != null) {
SumBuffer myagg = (SumBuffer) agg;
Object p1 = inputOI.getPrimitiveJavaObject(parameters[0]);
myagg.add(Integer.parseInt(String.valueOf(p1)));
}
}
@Override
public Object terminatePartial(AggregationBuffer agg) throws HiveException {
SumBuffer myagg = (SumBuffer) agg;
total += myagg.sum;
return total;
}
@Override
public void merge(AggregationBuffer agg, Object partial)
throws HiveException {
if (partial != null) {
SumBuffer myagg1 = (SumBuffer) agg;
Integer partialSum = (Integer) integerOI.getPrimitiveJavaObject(partial);
myagg1.add(partialSum);
}
}
@Override
public Object terminate(AggregationBuffer agg) throws HiveException {
SumBuffer myagg = (SumBuffer) agg;
return myagg.sum;
}
}
}
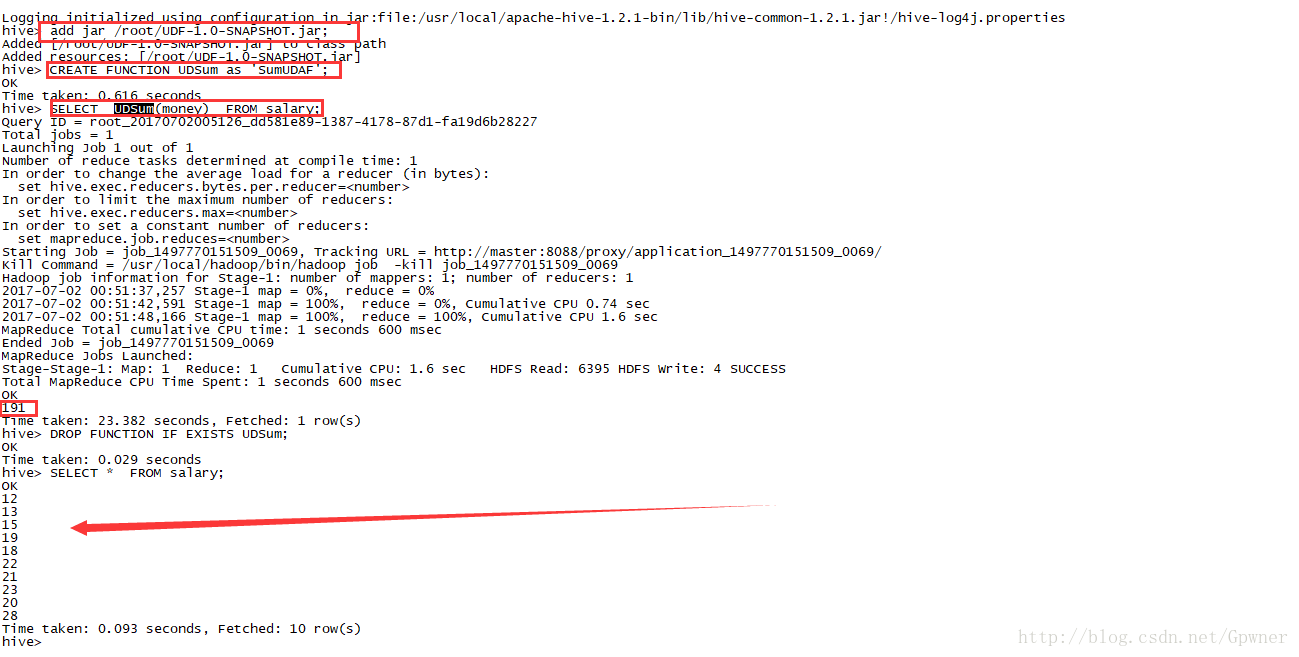
add jar /root/UDF-1.0-SNAPSHOT.jar;
CREATE FUNCTION UDSum as 'SumUDAF';
SELECT UDSum(money) FROM salary;
DROP FUNCTION IF EXISTS UDSum;