机器学习 - GMM参数估计的EM算法
博客内容源于《统计机器学习》一书的阅读笔记。Python的源码实现来源于互联网(作者不详)。
看理论之前先来【举个例子】:
对于一个未知参数的模型,我们观测他的输出,得到下图这样的直方图:
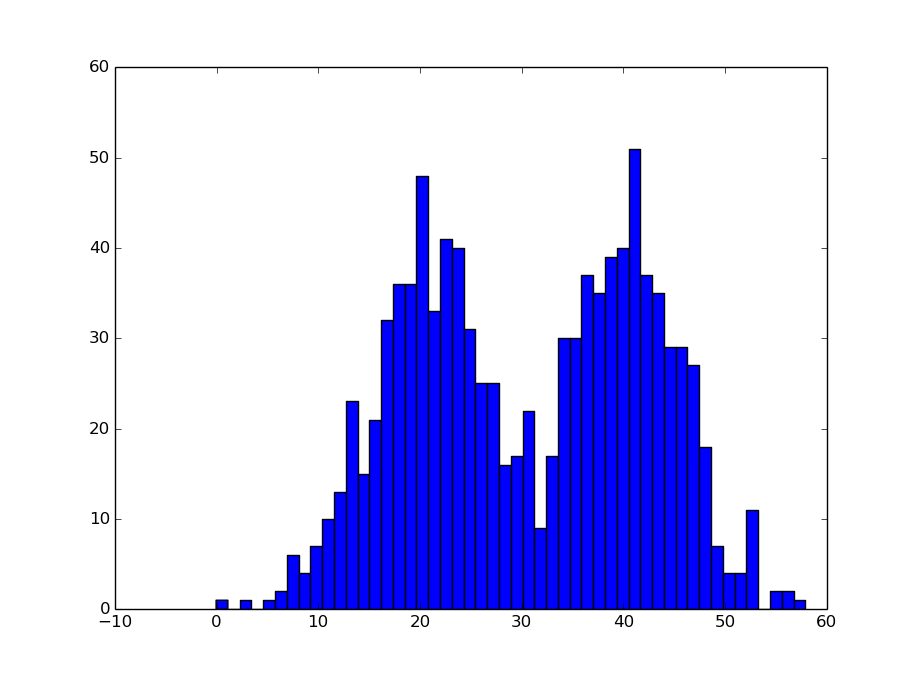
我们先假设它是由两个高斯分布混合叠加而成的,那么我们该怎么去得到这两个高斯分布的参数呢?
EM算法!!
1. 高斯混合模型
假设观测数据 y1,y2,...,yN 是由高斯混合模型生成的。
P(y|θ)=∑k=1Kαkθ(y|θk)
其中, θ={α1,α2,...,αk;θ1,θ2,...,θk} 。表示的是高斯模型的参数,EM算法也正是要用来估计高斯混合模型的这个参数。
2. 算法步骤
2.1 写出完全对数似然函数(弄清楚隐变量)
还是以上面的例子来说,对于我们的观测数据 yi,i=1,2,...,N 来说,该数据肯定是由分模型的数据叠加得到的。那么我们设想 yi 是这样产生的:
1> 首先依概率 αk 选择第 k 个高斯模型 ϕ(y|θk) ;
2> 然后依第 k 个分模型的概率分布 ϕ(y|θk) 生成观测数据。
这时候观测数据是已知的,反应观测数据 yj 来自第 k 个分模型的数据是未知的, k=1,2,...,K , 以隐变量 γjk 来表示。

可以得到完全似然函数:

2.2 EM算法的E步:确定Q函数
Q(θ,θ(i))=E[logP(y,γ|θ)|y,θ(i)]
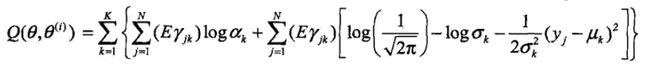
讲 Eγjk 和 ∑Nj=1Eγjk 替换,得到Q函数。 Eγjk 表示分模型 k 对观测数据 yj 的响应度。
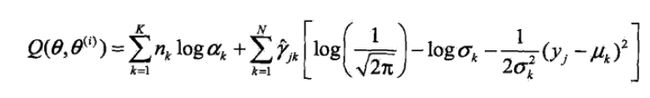
2.2 EM算法的M步:迭代计算
迭代M步就是求函数 Q(θ,θ(i)) 对 θ 的极大值,即求新一轮迭代的模型参数:
θ(i+1)=argmaxθQ(θ,θ(i))
每一次迭代中参数计算公式表示可得到:
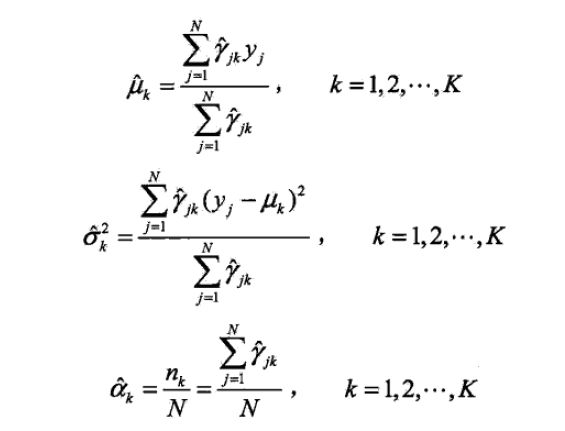
最终迭代计算到参数没有明显的变化时为止。
实例代码:
import math
import copy
import numpy as np
import matplotlib.pyplot as plt
isdebug = False
# 指定k个高斯分布参数,这里k=2。2个高斯分布具有相同均方差Sigma,均值分别为Mu1,Mu2。
def ini_data(Sigma,Mu1,Mu2,k,N):
global X
global Mu
global Expectations
X = np.zeros((1,N))
Mu = np.random.random(2)
Expectations = np.zeros((N,k))
for i in xrange(0,N):
if np.random.random(1) > 0.5:
X[0,i] = np.random.normal()*Sigma + Mu1
else:
X[0,i] = np.random.normal()*Sigma + Mu2
if isdebug:
print "***********"
print u"初始观测数据X:"
print X
# EM算法:步骤1,计算E[zij]
def e_step(Sigma,k,N):
global Expectations
global Mu
global X
for i in xrange(0,N):
Denom = 0
for j in xrange(0,k):
Denom += math.exp((-1/(2*(float(Sigma**2))))*(float(X[0,i]-Mu[j]))**2)
for j in xrange(0,k):
Numer = math.exp((-1/(2*(float(Sigma**2))))*(float(X[0,i]-Mu[j]))**2)
Expectations[i,j] = Numer / Denom
if isdebug:
print "***********"
print u"隐藏变量E(Z):"
print Expectations
# EM算法:步骤2,求最大化E[zij]的参数Mu
def m_step(k,N):
global Expectations
global X
for j in xrange(0,k):
Numer = 0
Denom = 0
for i in xrange(0,N):
Numer += Expectations[i,j]*X[0,i]
Denom +=Expectations[i,j]
Mu[j] = Numer / Denom
# 算法迭代iter_num次,或达到精度Epsilon停止迭代
def run(Sigma,Mu1,Mu2,k,N,iter_num,Epsilon):
ini_data(Sigma,Mu1,Mu2,k,N)
print u"初始:" , Mu
for i in range(iter_num):
Old_Mu = copy.deepcopy(Mu)
e_step(Sigma,k,N)
m_step(k,N)
print i,Mu
if sum(abs(Mu-Old_Mu)) < Epsilon:
break
if __name__ == '__main__':
run(6,40,20,2,1000,1000,0.0001)
plt.hist(X[0,:],50)
plt.show()