读书笔记-OpenCL编程指南 简介
OpenCL是Open Computing Language(开放语言的缩写)。设立OpenCL的目的就是为日益庞大的并行计算市场提供一个开放的、免费的行业标准。它让开发人员能够利用CPU、GPU等计算设备内部巨大的并行计算能力。为了保证通用计算,OpenCL在五个方面进行了规定:
- 系统调用全部的硬件资源
- 将C语言作为并行程序模型的基础,加快OpenCL程序的研发速度以及保证可移植性
- 做到与现有软件体系结构通用
- 实现硬件平台上的通用
- 提供承前启后,向前兼容的通用支持
OpenCL 1.1语言
OpenCL通过公布硬件来提供高度的可移植性,而不是将硬件隐藏在精巧的抽象之下。这说明OpenCL程序员必须显式地定义平台、上下文,以及在不同设备上调度工作。并不是所有程序员都需要OpenCL提供的详细控制。没关系,如果可以做其他选择,高层模型往往是更好的方法。不过,即使是高层编程模型,也需要一个牢固(且可移植)的基础,OpenCL就可以作为这个基础。
两个并行程序设计模型:任务并行和数据并行
在数据并行程序设计模型中,程序员从可以并发更新的数据元素集合角度来考虑问题。并行性表述为将相同的指令流并发地应用到各个数据元素,并行性体现在数据中。
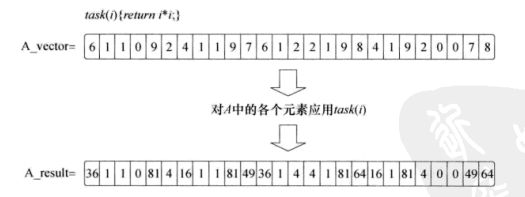
在任务并行程序设计模型中,程序员直接定义和处理并发任务。问题分解为可以并发运行的任务,然后再映射到一个并行计算机的处理单元(Prossing Element,PE)来执行。如果任务是独立的,使用这个模型最为容易,不过这个O型也可以用于共享数据的任务。如果要利用一组任务来计算,只有当最后一个任务完成时这个计算才算完成。因为任务的计算需求差别很大,合理地分布使它们能够在大致相同的时间完成可能很困难,这是一个负载平衡的问题。
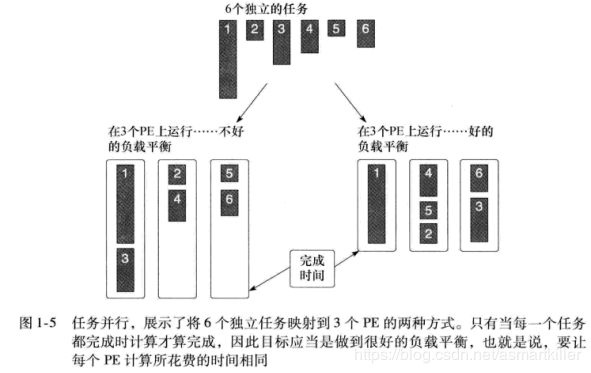
作为通用的编程框架OpenCL,同时支持这两种模型。
OpenCL概念基础
面向异构平台的应用都必须完成以下步骤:

这些步骤通过OpenCL中的一系列API加上一个面向kernel的编程环境来完成。我们将采用一种分而治之的策略解释以上步骤的所有攻击。将问题分解为以下模型:

平台模型
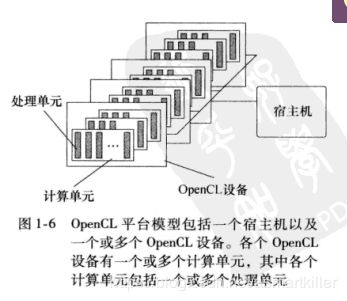
执行模型
内核
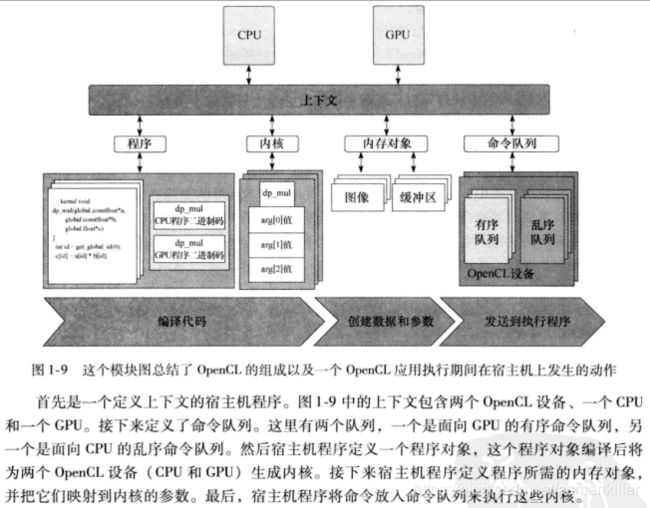
OpenCL应用由两个不同部分组成:一个宿主机程序以及一个或多个内核组成的集合。内核中OpenCL设备上执行。它们完成OpenCL应用的具体工作。内核通常是一些简单的函数,将输入内存对象转换为输出内存对象。OpenCL定义了两类内核:

内核如何在OpenCL设备上执行
内核在宿主机上定义。宿主机程序发出一个命令,提交内核在一个OpenCL设备上执行。由宿主机发出这个命令时,OpenCL运行时系统会创建一个整数索引空间。对应这个索引空间中的各个点将分别执行内核的一个实例。将执行内核的各个实例称为一个工作项(work-item)。工作项由它在索引空间中的坐标来标识。这些坐标就是工作项的全局ID。
提交内核执行的命令相应地会创建一个工作项集合,其中各个工作项使用内核定义的同样的指令序列。尽管指令序列是相同的,但是由于代码中的分支语句或者通过全局ID选择的数据可能不同,因此各个工作项的行为可能不同。
工作项组织为工作组work-group。工作组提供了对索引空间更粗粒度的分解,跨越整个全局索引。工作组在相应维度的大小相同,这个大小可以整除各维度中的全局大小。为工作组指定一个唯一的ID,这个ID与工作项使用的索引空间有相同的维度。另外为工作项指定一个局部ID,这个局部ID在工作组中是唯一的,这样就能由其全局ID或者由其局部ID和工作组ID唯一地标识一个工作项。
我的理解------------------------------------------------------------------------------------------------------------
内核 注:下面的类比以一维作为潜台词
工作项(work-item):执行内核的各个实例 --------> 内核相当于kernel类,内核的实例相当于kernel类实例化的对象,工作项就相当于这些对象
内核的各个实例对应于索引空间的各个点 --------> 索引空间相当于vector
工作项由它在索引空间中的坐标来标识,这些坐标就是工作项的全局ID --------> 索引空间中的坐标相当于vector
命令
工作项:内核定义的相同的指令序列 --------> 宿主机代码提交的命令队列相当于queue
工作集合:工作集合是一组相同的工作项的集合 --------> 工作集合相当于命令队列的数组,即vector
| 内核 | 命令队列 | |
|---|---|---|
| 工作项 | kernel | queue |
| 工作项集合 | vector |
vector |
内核实例和命令队列实例对应情况:
| 执行者 | kernel_instance_1 | kernel_instance_2 | … | kernel_instance_N |
|---|---|---|---|---|
| 操作指令 | queue |
queue |
… | queue |
工作组的意思就是依据一个维度对工作项进行分组。用工作组指定一个唯一ID,替代工作组所拥有工作项在全局索引空间中原来的ID。给工作组中的工作项指定局部ID,这样就可以通过工作组ID+局部ID索引到相应的工作项(工作组中的索引空间称为局部索引空间)。这样就方便了对拥有多个处理单元的计算单元分配任务,也就是工作组中的每个工作项对应计算单元中的一个处理单元。依据上面所述的模型,OpenCL只能保证一个工作组中的工作项并发执行,并不会保证各个工作组之间会并发执行。
索引空间是一个N维的值网格,因此也称为NDRange。目前这个N维索引空间中的N可以是1,2,3。在一个OpenCL程序中,NDRange由一个长度为N的整数数组定义,N指定索引空间各维度的大小。各个工作项的全局和局部ID都是一个N维元祖。
考虑一个2维的NDRange,使用小写字母g表示给定下标x或y时各维度中一个工作项的全局ID。大写字母G指示索引空间各维度的大小。各工作项在全局NDRange索引空间中有一个坐标(gx,gy),全局索引空间的大小为(Gx,Gy),工作项坐标取值范围为[0, (Gx -1), 0 , (Gy-1)]。第一维工作项的数量为Gx,第二维工作项的数量为Gy。
小写字母w表示工作组ID,大写字母W表示各个维度中工作组的个数。局部索引空间中各个维度的工作项数量用大写字母L表示,工作组中局部ID使用小写字母l表示。大小为GxGy的NDRange索引空间将划分为WxWy空间上的工作组,其索引为(wx,wy)。各个工作组的大小为Lx*Ly。
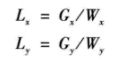
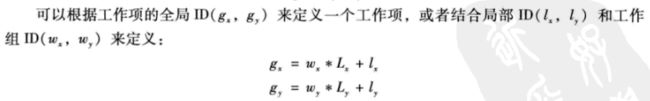
其中
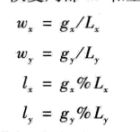


关于工作项的分组:如果分组第一维包含m个工作项,第二维包含n个工作项,而索引空间是2维分别包含N和R个工作项,那么N%m == 0 且 R%n ==0。比如索引空间的两个维度有4个、8个工作项,分组包含各个维度2个工作项,整个也就是4个工作项。各个维度都可以整除。总共可以分配成8个工作组。
上下文
上下文定义一个环节,内核就在这个环境中定义和执行。由一下资源定义上下文:

程序对象包含内核的代码,可以类比为动态库,可以从中取出内核使用的函数。
我的理解---------------------------------------------------------------------------------------------
| OpenCL概念 | –> | 编程语言概念 |
|---|---|---|
| platfrom | –> | 计算机 |
| Context | –> | 操作系统 |
| OpenCL device | –> | 虚拟机 |
| kernel | –> | 类 |
| program object | –> | 类中的方法 |
| memory object | –> | 类中的数据成员 |
命令队列
宿主机与OpenCL设备之间的交互是通过命令完成的。这些命令由宿主机提交给命令队列。这些命令会在命令队列中等待,直到在OpenCL设备上执行。命令队列由宿主机创建,并在定义上下文之后关联到一个OpenCL设备。宿主机将命令队列,然后调度这些命令在关联设备上执行。


命令总是与宿主机程序异步执行。宿主机程序向命令队列提交命令,然后继续工作,而不必等待命令完成。如果有必要让宿主机等待一个命令,可以利用一个同步命令显式建立约束。



内存模型



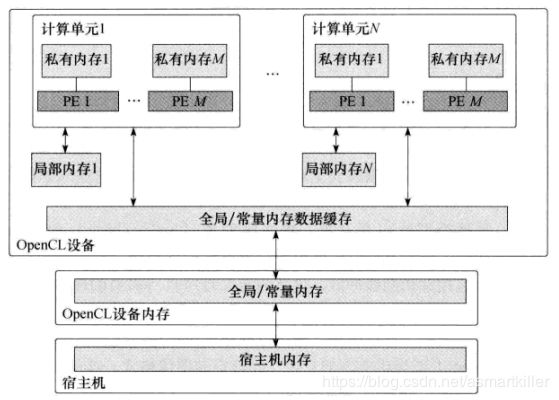
大多数情况下,宿主机和OpenCL设备内存模型是独立的。内存之间的交互有两种方式:显式复制数据或映射和解映射内存对象的内存区域。

当涉及并发时,内存就会成为竞争对象,这是内存一致性问题。


编程模型
使用编程模型将并行算法映射到OpenCL:任务并行和数据并行,以及包含数据并行的任务。
数据并行编程模型
将一个逻辑指令序列并发地应用到数据结构上。关键是执行一个内核时定义的NDRange,算法设计者要保证问题中的数据结构与NDRange索引空间一致,将它们映射到OpenCL内存对象。内核定义了OpenCL计算中作为工作项并发应用的指令序列。
在更复杂的数据并行问题中,一个工作组中的工作项需要共享数据。这要通过存储在局部内存区域中的数据来支持。只要工作项之间引入了依赖性,就必须特别当心,不论工作项以什么顺序完成,都要生成相同的结果。换句话,工作项的执行需要同步。一个工作组中的工作项可能参与一个工作组栅栏。一个工作组中的所有工作项必须先先执行这个栅栏,之后才允许跨过这个栅栏继续执行。工作组中执行内核的所有工作项都遇到工作组栅栏,或者都不会遇到这个栅栏。对于执行一个内核时不同工作组的工作项之间如何同步,OpenCL 1.1并未提供任何机制。
OpenCL提供了层次结构的数据并行性:工作组中的工作项的数据并行再加上工作组层次的数据并行。OpenCL规范讨论了这种数据并行形式的两个变种。在显式模式(explicit model)中,程序员负责显式地定义工作组的大小。利用第二个模型,即隐式模型(implicit model),程序员只需定义NDRange空间,由系统选择工作组。
任务并行编程模型
OpenCL执行模型被设计为以数据并行作为主要目标。不过这个模型还支持大量任务并行算法。
OpenCL将任务定义为单个工作项执行的内核,而不考虑OpenCL应用中其他内核使用的NDRange。如果程序员所希望的并发性来自于任务,就会使用这个模型。例如,并发性可能只是通过矢量类型上的矢量操作来表述。或者任务可能使用原生内核接口定义的一个内核,并行性使用OpenCL之外的一个编程环境来表述。
任务并行的另一个版本就是内核作为任务提交,利用一个乱序队列同时执行这些任务。比如,在一个四核CPU上,一个核可能是宿主机,另外3个核配置为一个OpenCL设备中的计算单元。OpenCL应用可以将所有6个任务入队,由计算单元动态调度工作,以达到负载平衡用时最短的效果。
任务并行的第三个版本是使用OpenCL的事件模型连接到一个任务图。提交到时间队列的命令有可能生成事件。后续的命令在执行之前可能等待这些事件。与支持乱序执行模型的命令队列结合使用,就允许OpenCL程序员在OpenCL中定义静态任务图,图中的节点表示任务,边为节点之间的依赖(由事件管理)。
其他编程模型

难点:事件+内存一致性+kernel编程
API
