MapReduce详细的工作流程(MapReduce2)
上一篇详细讲了MapReduce1的工作流程,这一篇主要讲基于YARN系统的MapReduce 2的工作流程。
对于大于4000个节点的集群来说,MapReduce1系统将会产生一个规模瓶颈,因此Yahoo在2010年开始设计下一代的MapReduce,因此产生了YARN。YARN通过把jobTracker的责任划分为几个独立的模块修复了MapReduce1的缺点。jobTracker需要管理job的安排(scheduling)(用taskTracker来匹配任务)和任务进度监视(追踪进度,重启失败的、慢的任务,写任务记录比如counter)。
YARN把这两个角色分为两个独立的模块:资源管理器(resource manager)来管理集群资源的利用,主应用(application master)来管理在集群上运行的应用的生命周期。主程序与资源管理器协商集群资源。这些集群资源就是一些拥有内存限制的容器(containers),可以运行在这些容器中运行应用进程。这些容器被运行在集群节点上面的节点管理器(node manager)监视,确保应用只能使用被分配的资源。相对于jobTracker来说,每一个应用的实例(一个MapReduce Job)有一个专用的主应用(application master),它在该应用运行的时候执行。
正如描述的那样,YARN比MapReduce更普通,事实上,MapReduce是YARN的一种类型。YARN设计之美在于不同的YARN应用能够在一个集群上共存,因此一个MapReduce程序能够作为一个MPI程序运行,这对集群的可管理性和利用率带来了很大的提升。而且,用户非常有可能运行不同版本的MapReduce在他噢乖一个YARN集群上面,这使得MapReduce的升级更容易管理。YARN的MapReduce牵扯到跟多的实体:
- The Client 提交MapReduce Job
- YARN resource manager 协调集群上面的电脑资源的分配
- YARN node manager 运行和监视集群电脑里面的container
- Application Master 协调运行MapReduce job的任务。application master 和MapReduce task 运行在resource manager分配的containers中。resource manager 被node manager管理。
- HDFS 用来在不同模块间共享文件的
处理过程如图6-4所示:
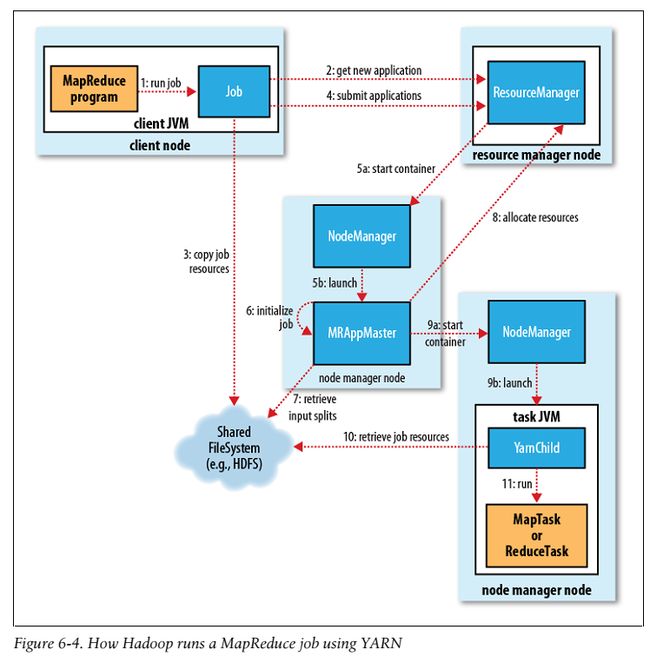
Job 提交
在MapReduce2中提交Job和MapReduce1中调用的API是相同的。(step1) MapReduce2需要配置ClientProtocol,把mapreduce.framework.name设为yarn。提交过程和MapReduce1非常相似。新的job ID 是从资源管理器中获取的(不是JobTracker),在YARN中叫做 application ID。(step2)*Job client核对job的输出规范,计算输入划分(input split),复制job resource(包括job JAR、配置文件和划分信息) 到HDFS(step3)。最后通过调用资源管器的submitApplication()来提交job(step4)*。
Job 初始化
当资源管理器收到一个submitApplication()请求,它会原封不动的传给scheduler。scheduler 分配一个容器,然后资源管理器运行主程序(application master)进程,在节点管理器的管理下(step5a and 5b)。
MapReduce jobs的application master 是一个主类为MRAppMaster的java程序。它通过创建一些保存job进度的对象来初始化job,同样的它将会收到从task提交的进度和完成报告。(step6)下一步,他检索从HDFS复制的客户端计算的输入分割(input split)(step7)。然后,它为每一个split 创建一个map task,而reduce task的个数是由mapreduce.job.reduces来确定的。application master 接下来会决定如何运行组成MapReduce job的任务。
如果job非常小,application master 将会选择在一个JVM中运行这些任务。在这种情况下,平行运行这些任务与顺序运行这些任务的消耗之差比分配和在新container中运行任务的消耗要小。这样的一个job成为一个超级job(uber tassk)。什么是一个小job呢?默认情况下,一个job的map task小于10个,reduce task只有一个,并且input size 小于HDFS block。你可以通过设置mapreduce.job.ubertask.enable为false来禁用 uber task。在任何任务运行之前,创建输出目录的job setup方法将会被调用。
任务分配
如果一个任务不是uber task,application master 将会从资源管理器为job中所有的map reduce task 请求container。(step8) 所有的请求都被封装到心跳调用中(heartbeat calls),包括每一个map task 数据本地化的信息,特别的还有主机文件和输入分割所在的rack。scheduler 利用这些信息来决定调度。在理想情况下,它尝试把这些任务放到data–local节点上,如果不行的话,scheduler尽力把这些任务放到rack–local节点。请求会为任务指定内存需求。默认的情况下,map和reduce task都被分配1024M内存。这个数据可以通过mapreduce.map.memory.mb和mapreduce.map.memory.mb来配置。
在内存分配方面,mapreduce1 的taskTracker 有固定数目的插槽(slots),数目是由集群配置的时候设定的,每一个任务运行在一个独立的插槽中。slots有一个最大的内存分配值,对一个集群来说这个值也是固定的,这样的话,就会造成小任务内存浪费,大任务内存不够的情况。在YARN中,资源被分为更小的块,因此上述问题就会迎刃而解。默认的内存分配额是由scheduler指定的,最小为1024M,最大是10240M,因此任务能够请求的内存为1G-10G(多个1G块)。
任务执行
当一个任务被资源管理器的scheduler分配完container之后,application master将会与node manager 联系来启动container。(step9a和9b)这个任务被一个主类是YarnChild的JAVA 程序执行。在运行这个任务之前,它需要从HDFS复制运行任务需要的JAR 文件,配置文件等(step10)。最后他才会开始运行map或者reduce task。(step11)
YarnChild运行在一个指定的JVM中,和MapReduce1一样为了把用户代码和长时间运行的系统守护进程隔离开来。但是与mapReduce1不同的是,YARN不进行JVM重用,因此每一个任务都是运行在一个新的JVM中。流(streaming)和管道(pipes)进程工作的方式和MapReduce1一样。流的通信方式依然是标准的输入输出,管道的还是socket。
进度和状态更新
在YARN架构下运行,task向application master提交它的进度和状态,application master 每隔三秒通过中央接口合并job的进度状态视图。过程如图6-5所示。

客户端每秒钟询问application master进度。在MapReduce1 中jobTracker 的网络视图展示一系列正在运行的任务进度,在YARN中,application master 的网络视图展示这些任务以及任务的详细进度。
Job 完成
客户端每隔五秒调用waitForCompletion()核对job是否已经完成。这个时间可以通过maoreduce.client.completion.pollinterval来设置。想MapReduce1一样,job 完成的通知也支持HTTP callback,擦亮了吧产看、是由application master初始化的。
在Job完成时,application master和task container 清除它们的工作状态,同时OutputCommitter的job的cleanup方法被调用。Job信息由job历史服务器记录,确保之后想要查询时可以找的得到。
至此,两种架构的工作流程已讲解完成。