memcached源码分析-----get命令处理流程
转载请注明出处:http://blog.csdn.net/luotuo44/article/details/44217383
本文以get命令为例子,探讨memcached是如何处理命令的。本文只是探讨memcached处理命令的工作流程,具体的代码细节在不影响阅读的前提下能省略的就省略、能取默认值就取默认值、内存是足够的(不需要动态申请空间就够用了)。涉及到数组、缓存区的就假设已经分配好了。
现在假定memcached里面有了一个键值为”tk”的item,此时我们使用命令”get tk”获取对应item的内容。
《网络模型》展示了当memcached进程accept一个新客户端连接时,会把该连接的一些信息封装成一个conn结构体,并且把新连接的初始状态设置成conn_new_cmd。此时,worker线程等待客户端命令的到来。conn结构体有很多成员变量,后文只会列出使用到的成员。
读取命令:
等待有数据可读:
当客户端发送get命令后,memcached的event_base就会监听到客户端对应的socket fd变成可读了,接着就会调用回调函数event_handler处理这个可读事件。实际上回调函数event_handler只是一个傀儡函数,它会调用drive_machine函数进行处理。drive_machine是一个有限状态机,在真正读数据之前它会在几个状态中跳转。
void event_handler(const int fd, const short which, void *arg) {
conn *c;
c = (conn *)arg;
c->which = which;
/* sanity */
if (fd != c->sfd) {
conn_close(c);
return;
}
drive_machine(c);
/* wait for next event */
return;
}
struct conn {
int sfd;//该conn对应的socket fd
enum conn_states state;//当前状态
struct event event;//该conn对应的event
short ev_flags;//event当前监听的事件类型
short which; /** which events were just triggered */ //触发event回调函数的原因
//读缓冲区
char *rbuf; /** buffer to read commands into */
//有效数据的开始位置。从rbuf到rcurr之间的数据是已经处理的了,变成无效数据了
char *rcurr; /** but if we parsed some already, this is where we stopped */
//读缓冲区的总长度
int rsize; /** total allocated size of rbuf */
//有效数据的长度。初始值为0
int rbytes; /** how much data, starting from rcur, do we have unparsed */
...
LIBEVENT_THREAD *thread;//这个conn属于哪个worker线程
};
static void drive_machine(conn *c) {
bool stop = false;
int sfd;
int nreqs = settings.reqs_per_event;//20
int res;
const char *str;
//drive_machine被调用会进行状态判断,并进行一些处理。但也可能发生状态的转换
//此时就需要一个循环,当进行状态转换时,也能处理
while (!stop) {
switch(c->state) {
...
case conn_waiting://等待socket变成可读的
if (!update_event(c, EV_READ | EV_PERSIST)) {//更新监听事件失败
conn_set_state(c, conn_closing);
break;
}
conn_set_state(c, conn_read);
//居然stop循环,不过没关系,因为event的可读事件是水平触发的。
//马上又会再次进入有限状态机,并且进入下面的conn_read case中。
stop = true;
break;
case conn_new_cmd:
--nreqs;
if (nreqs >= 0) {//简单起见,不考虑nreqs小于0的情况
//如果该conn的读缓冲区没有数据,那么将状态改成conn_waiting
//如果该conn的读缓冲区有数据, 那么将状态改成conn_pase_cmd
reset_cmd_handler(c);
}
break;
...
}
}
return;
}
static void reset_cmd_handler(conn *c) {
c->cmd = -1;
...
//为了简单,这里假设没有数据
if (c->rbytes > 0) {//读缓冲区里面有数据
conn_set_state(c, conn_parse_cmd);//解析读到的数据
} else {
conn_set_state(c, conn_waiting);//否则等待数据的到来
}
}
//设置conn的状态
static void conn_set_state(conn *c, enum conn_states state) {
...
if (state != c->state) {
c->state = state;
}
}
读取数据:
在前面,conn的状态跳转到了conn_read。在case conn_read中,worker线程会调用try_read_network函数读取客户端发送的数据。try_read_network函数会尽可能地把所有的数据都读进conn的读缓存区中(当然也是有一个最大限度的)。
static void drive_machine(conn *c) {
bool stop = false;
int sfd;
int nreqs = settings.reqs_per_event;//20
int res;
const char *str;
//drive_machine被调用会进行状态判断,并进行一些处理。但也可能发生状态的转换
//此时就需要一个循环,当进行状态转换时,也能处理
while (!stop) {
switch(c->state) {
...
case conn_read:
//这里假定为TCP
res = IS_UDP(c->transport) ? try_read_udp(c) : try_read_network(c);
switch (res) {
…
case READ_DATA_RECEIVED://读取到了数据,接着就去解析数据
conn_set_state(c, conn_parse_cmd);
break;
…
}
break;
...
}
}
return;
}
//尽可能把socket的所有数据都读进c指向的一个缓冲区里面
static enum try_read_result try_read_network(conn *c) {
enum try_read_result gotdata = READ_NO_DATA_RECEIVED;
int res;
...
while (1) {
...
int avail = c->rsize - c->rbytes;
res = read(c->sfd, c->rbuf + c->rbytes, avail);
if (res > 0) {
...
gotdata = READ_DATA_RECEIVED;
c->rbytes += res;
if (res == avail) {//可能还有数据没有读出来
continue;
} else {
break;//socket暂时还没数据了(即已经读取完)
}
}
...
}
return gotdata;
}
解析命令:
前面已经展示了,worker线程怎么读取数据(命令),并且在读取完毕后会把conn的状态设置为conn_parse_cmd。为了简单起见,我们假设经过一次读取就已经成功读取了一条完整的get命令。
static void drive_machine(conn *c) {
int res;
while (!stop) {
switch(c->state) {
case conn_parse_cmd :
//返回1表示正在处理读取的一条命令
//返回0表示需要继续读取socket的数据才能解析命令
//如果读取到了一条完整的命令,那么函数内部会去解析,
//并进行调用process_command函数进行一些处理.
//像set、add、replace、get这些命令,会在处理的时候调用
//conn_set_state(c, conn_nread)
if (try_read_command(c) == 0) {
/* wee need more data! */
conn_set_state(c, conn_waiting);
}
break;
}
}
return;
}
/*
* if we have a complete line in the buffer, process it.
*/
static int try_read_command(conn *c) {
...
char *el, *cont;
el = memchr(c->rcurr, '\n', c->rbytes);
if (!el) {//没有读取到一条完整的命令
...//为了简单,不考虑这种情况。
return 0;//返回0表示需要继续读取socket的数据才能解析命令
}
//来到这里,说明已经读取到至少一条完整的命令
cont = el + 1;//用cont指向下一行的开始,无论行尾是\n还是\r\n
//不同的平台对于行尾有不同的处理,有的为\r\n有的则是\n。所以memcached
//还要判断一下\n前面的一个字符是否为\r
if ((el - c->rcurr) > 1 && *(el - 1) == '\r') {
el--;//指向行尾的开始字符
}
//'\0',C语言字符串结尾符号。结合c->rcurr这个开始位置,就可以确定
//这个命令(现在被看作一个字符串)的开始和结束位置。rcurr指向了一个字符串
//注意,下一条命令的开始位置由前面的cont指明了
*el = '\0';
c->last_cmd_time = current_time;
//处理这个命令
process_command(c, c->rcurr);//命令字符串由c->rcurr指向
...
return 1;//返回1表示正在处理读取的一条命令
}
上面的try_read_command函数,以\n或者\n\r为作为一条数据的结尾。并且会把数据的结尾赋值为’\0’,这样conn的rcurr指针就相当于指向一个以’\0’结尾的字符串。接着就会调用process_command函数处理这个字符串,在处理之前还要解析出这个字符串具体是什么命令。
符号化命令内容:
在执行命令之前,必须要知道接收到的字符串是什么命令以及参数是什么。为此,memcached会调用tokenize_command函数处理命令字符串,将字符串符号化。比如命令字符串"set tt 3 0 10",将符号化为”set”、”tt”、”3”、”0”和”10”(后面会将这些称为token)。此外tokenize_command还会清除命令字符串里面的多余空白符。Memcached定义了一个token_t结构体(如下面代码所示)。memcached还为每一条字符串命令定义一个token_t数组,数组每一个元素的value成员指向对应token的开始位置,length成员则记录该token的长度。
#define COMMAND_TOKEN 0
#define SUBCOMMAND_TOKEN 1
#define KEY_TOKEN 1
#define MAX_TOKENS 8
typedef struct token_s {
char *value;
size_t length;
} token_t;
//command指向这条命令(该命令以字符串的形式表示)
static void process_command(conn *c, char *command) {
token_t tokens[MAX_TOKENS];
size_t ntokens;
int comm;
...
//将一条命令分割成一个个的token,并用tokens数组一一对应的指向
//比如命令"set tt 3 0 10",将被分割成"set"、"tt"、"3"、"0"、"10"
//并用tokens数组的5个元素对应指向。token_t类型的value成员指向对应token
//在command字符串中的位置,length则指明该token的长度。
//该函数返回token的数量,数量是用户敲入的命令token数 + 1.
//上面的set命令例子,tokenize_command会返回6。 最后一个token是无意义的
ntokens = tokenize_command(command, tokens, MAX_TOKENS);//将命令记号化
//对于命令"get tk",那么tokens[0].value 等于指向"get"的开始位置
//tokens[1].value 则指向"tk"的开始位置
if (ntokens >= 3 &&
((strcmp(tokens[COMMAND_TOKEN].value, "get") == 0) ||
(strcmp(tokens[COMMAND_TOKEN].value, "bget") == 0))) {
process_get_command(c, tokens, ntokens, false);
}
else
{
...//根据tokens判断是否为其他命令,并进行对应的处理
}
}
执行命令:
回应信息的存储:
process_get_command函数在处理get命令时,并不是直接拷贝一份item的数据(考虑一下效率和内存),所以memcached是直接使用item本身的数据,用iovec结构体的成员变量指向item里面的数据。这样能省去拷贝数据内存,也能提高效率。但memcached里面的item可能随时被删除(归还给slab内存分配器),可以通过占用这个item,防止item被删除。在《item引用计数》中说到,只要增加item的引用计数就能防止这个item被删除。于是在process_get_command函数中会占有item,并用一个item指针数组记录其占用了哪些item(这个数组在conn结构体中)。当memcached将item的数据返回给客户端后,就会释放对item的占用。
前面说到memcached使用iovec结构体的成员变量指向item的数据,但memcached并不是使用writev函数向客户端写数据的,而是使用sendmsg函数。sendmsg函数使用msghdr结构体指针作为参数。因为sendmsg函数中msghdr结构体中的iovec数组长度是有限制的,所以conn结构体中有一个msghdr数组。数组中每一个msghdr结构体带有IOV_MAX个iovec结构体。通过动态申请msghdr数组,可以使得有很多个iovec结构体,不再受IOV_MAX的限制。当然前面说到的iovec结构体个数也是要有足够多,所以conn结构体里面还是有一个iovec指针用来动态申请iovec结构体。现在来看一下conn结构体对应的成员。
struct conn {
struct iovec *iov;//iovec数组指针
//数组大小
int iovsize; /* number of elements allocated in iov[] */
//已经使用的数组元素个数
int iovused; /* number of elements used in iov[] */
//因为msghdr结构体里面的iovec结构体数组长度是有限制的。所以为了能
//传输更多的数据,只能增加msghdr结构体的个数.add_msghdr函数负责增加
struct msghdr *msglist;//指向msghdr数组
//数组大小
int msgsize; /* number of elements allocated in msglist[] */
//已经使用了的msghdr元素个数
int msgused; /* number of elements used in msglist[] */
//正在用sendmsg函数传输msghdr数组中的哪一个元素
int msgcurr; /* element in msglist[] being transmitted now */
//msgcurr指向的msghdr总共有多少个字节
int msgbytes; /* number of bytes in current msg */
//worker线程需要占有这个item,直至把item的数据都写回给客户端了
//故需要一个item指针数组记录本conn占有的item
item **ilist; /* list of items to write out */
int isize;//数组的大小
item **icurr;//当前使用到的item(在释放占用item时会用到)
int ileft;//ilist数组中有多少个item需要释放
};
在process_command函数中,memcached会增加msglist数组的大小。
static void process_command(conn *c, char *command) {
c->msgcurr = 0;
c->msgused = 0;
c->iovused = 0;
if (add_msghdr(c) != 0) {
out_of_memory(c, "SERVER_ERROR out of memory preparing response");
return;
}
...
}
/*
* Adds a message header to a connection.
*
* Returns 0 on success, -1 on out-of-memory.
*/
static int add_msghdr(conn *c)
{
struct msghdr *msg;
assert(c != NULL);
if (c->msgsize == c->msgused) {//已经用完了
msg = realloc(c->msglist, c->msgsize * 2 * sizeof(struct msghdr));
if (! msg) {
return -1;
}
c->msglist = msg;
c->msgsize *= 2;
}
msg = c->msglist + c->msgused;//msg指向空闲的节点
/* this wipes msg_iovlen, msg_control, msg_controllen, and
msg_flags, the last 3 of which aren't defined on solaris: */
memset(msg, 0, sizeof(struct msghdr));
msg->msg_iov = &c->iov[c->iovused];//指向空闲的iovec
c->msgbytes = 0;
c->msgused++;
return 0;
}
前面说到memcached使用iovec结构体的成员变量指向item的数据,实际上除了item数据,所有回应客户端的数据(包括错误信息)都是通过iovec结构体指向的。memcached通过add_iov函数把要回应的字符串加入到iovec中。
static int add_iov(conn *c, const void *buf, int len) {
struct msghdr *m;
int leftover;
bool limit_to_mtu;
assert(c != NULL);
//在process_command函数中,一开始会调用add_msghdr函数,而add_msghdr会把
//msgused++,所以msgused会等于1,即使在conn_new函数中它被赋值为0
do {
m = &c->msglist[c->msgused - 1];
/*
* Limit UDP packets, and the first payloads of TCP replies, to
* UDP_MAX_PAYLOAD_SIZE bytes.
*/
limit_to_mtu = IS_UDP(c->transport) || (1 == c->msgused);
/* We may need to start a new msghdr if this one is full. */
if (m->msg_iovlen == IOV_MAX ||//一个msghdr最多只能有IOV_MAX个iovec结构体
(limit_to_mtu && c->msgbytes >= UDP_MAX_PAYLOAD_SIZE)) {
add_msghdr(c);
m = &c->msglist[c->msgused - 1];
}
//保证iovec数组是足够用的。调用add_iov函数一次会消耗一个iovec结构体
//所以可以在插入数据之前保证iovec数组是足够用的
if (ensure_iov_space(c) != 0)
return -1;
/* If the fragment is too big to fit in the datagram, split it up */
if (limit_to_mtu && len + c->msgbytes > UDP_MAX_PAYLOAD_SIZE) {
leftover = len + c->msgbytes - UDP_MAX_PAYLOAD_SIZE;
len -= leftover;
} else {
leftover = 0;
}
m = &c->msglist[c->msgused - 1];
//用一个iovec结构体指向要回应的数据
m->msg_iov[m->msg_iovlen].iov_base = (void *)buf;
m->msg_iov[m->msg_iovlen].iov_len = len;
c->msgbytes += len;
c->iovused++;
m->msg_iovlen++;
buf = ((char *)buf) + len;
len = leftover;
} while (leftover > 0);
return 0;
}
/*
* Ensures that there is room for another struct iovec in a connection's
* iov list.
*
* Returns 0 on success, -1 on out-of-memory.
*/
static int ensure_iov_space(conn *c) {
assert(c != NULL);
//已经使用完了之前申请的
if (c->iovused >= c->iovsize) {
int i, iovnum;
struct iovec *new_iov = (struct iovec *)realloc(c->iov,
(c->iovsize * 2) * sizeof(struct iovec));
if (! new_iov) {
return -1;
}
c->iov = new_iov;
c->iovsize *= 2;
/* Point all the msghdr structures at the new list. */
//因为iovec数组已经重新分配在别的空间了,而msglist数组元素指向这个iovec
//数组,所以需要修改msglist数组元素的值
for (i = 0, iovnum = 0; i < c->msgused; i++) {
c->msglist[i].msg_iov = &c->iov[iovnum];
iovnum += c->msglist[i].msg_iovlen;
}
}
return 0;
}
看了上面的代码,可能读者还不是很明白前面列出的conn结构体成员的关联。不懂的,可以参考下图:
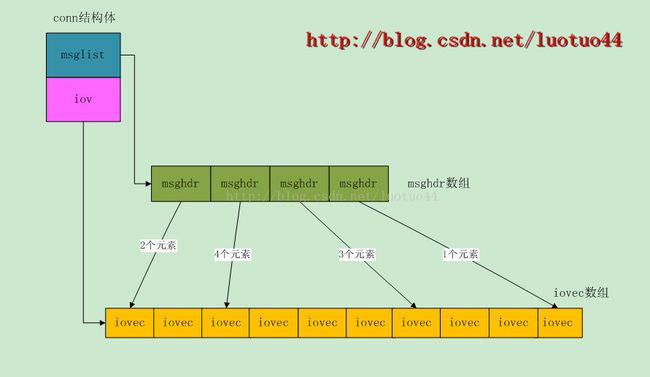
处理get命令:
有了上面的说明和代码,现在来看一下process_get_command函数。当然我们这里也是假设上面三个数组都是分配了内存。在process_get_command函数中会涉及到item的哈希表查找和删除(超时懒惰删除),关于这两点可以分别参考《哈希表查找item》和《删除item》。
item *item_get(const char *key, const size_t nkey) {
item *it;
uint32_t hv;
hv = hash(key, nkey);
item_lock(hv);
it = do_item_get(key, nkey, hv);
item_unlock(hv);
return it;
}
/** wrapper around assoc_find which does the lazy expiration logic */
//调用do_item_get的函数都已经加上了item_lock(hv)段级别锁或者全局锁
item *do_item_get(const char *key, const size_t nkey, const uint32_t hv) {
//mutex_lock(&cache_lock);
item *it = assoc_find(key, nkey, hv);//assoc_find函数内部没有加锁
...
//mutex_unlock(&cache_lock);
if (it != NULL) {
if (...) {
...
} else if (it->exptime != 0 && it->exptime <= current_time) {//该item已经过期失效了
do_item_unlink(it, hv);//引用计数会减一
do_item_remove(it);//引用计数减一,如果引用计数等于0,就删除
it = NULL;
} else {
//把这个item标志为被访问过的
it->it_flags |= ITEM_FETCHED;
}
}
return it;
}
/* ntokens is overwritten here... shrug.. */
static inline void process_get_command(conn *c, token_t *tokens, size_t ntokens, bool return_cas) {
char *key;
size_t nkey;
int i = 0;
item *it;
token_t *key_token = &tokens[KEY_TOKEN];
char *suffix;
assert(c != NULL);
do {
//因为一个get命令可以同时获取多条记录的内容
//比如get key1 key2 key3
while(key_token->length != 0) {
key = key_token->value;
nkey = key_token->length;
it = item_get(key, nkey);
if (it) {
/*
* Construct the response. Each hit adds three elements to the
* outgoing data list:
* "VALUE "
* key
* " " + flags + " " + data length + "\r\n" + data (with \r\n)
*/
if (return_cas)
{
...//不是cas
}
else
{
//填充要返回的信息
if (add_iov(c, "VALUE ", 6) != 0 ||//如果add_iov成功,则返回0
add_iov(c, ITEM_key(it), it->nkey) != 0 ||
add_iov(c, ITEM_suffix(it), it->nsuffix + it->nbytes) != 0)
{
item_remove(it);//引用计数减一
break;
}
}
//刷新这个item的访问时间以及在LRU队列中的位置
item_update(it);
//并不会马上放弃对这个item的占用。因为在add_iov函数中,memcached并不为
//复制一份item,而是直接使用item结构体本身的数据。故不能马上解除对
//item的引用,不然其他worker线程就有机会把这个item释放,导致野指针
*(c->ilist + i) = it;//把这个item放到ilist数组中,日后会进行释放的
i++;
}
key_token++;
}
//因为调用一次tokenize_command最多只可以解析MAX_TOKENS-1个token,但
//get命令的键值key个数可以有很多个,所以此时就会出现后面的键值
//不在第一次tokenize的tokens数组中,此时需要多次调用tokenize_command
//函数,把所有的键值都tokenize出来。注意,此时还是在get命令中。
//当然在看这里的代码时直接忽略这种情况,我们只考虑"get tk"命令
if(key_token->value != NULL) {
ntokens = tokenize_command(key_token->value, tokens, MAX_TOKENS);
key_token = tokens;
}
} while(key_token->value != NULL);
c->icurr = c->ilist;
c->ileft = i;
/*
If the loop was terminated because of out-of-memory, it is not
reliable to add END\r\n to the buffer, because it might not end
in \r\n. So we send SERVER_ERROR instead.
*/
if (key_token->value != NULL || add_iov(c, "END\r\n", 5) != 0
|| (IS_UDP(c->transport) && build_udp_headers(c) != 0)) {
out_of_memory(c, "SERVER_ERROR out of memory writing get response");
}
else {
conn_set_state(c, conn_mwrite);//更改conn的状态
c->msgcurr = 0;
}
}
回应命令:
前面的process_get_command函数已经把要写的数据都通过iovec结构体指明了,并且把conn的状态设置为conn_mwrite。现在来看一下memcached具体是怎么写数据的。
static void drive_machine(conn *c) {
bool stop = false;
while (!stop) {
switch(c->state) {
...
case conn_mwrite:
...
switch (transmit(c)) {//发送数据给c->sfd指明的客户端
case TRANSMIT_COMPLETE://发送数据完毕
if (c->state == conn_mwrite) {
conn_release_items(c);//释放对item的占用
/* XXX: I don't know why this wasn't the general case */
if(c->protocol == binary_prot) {
conn_set_state(c, c->write_and_go);
} else {//我们只考虑文本协议
conn_set_state(c, conn_new_cmd);//又回到了一开始的conn_new_cmd状态
}
}
break;
case TRANSMIT_INCOMPLETE://还没发送完毕
break;
}
break;
}
}
return;
}
//通过s->sfd把数据写到对端
static enum transmit_result transmit(conn *c) {
if (c->msgcurr < c->msgused &&
c->msglist[c->msgcurr].msg_iovlen == 0) {//msgcurr指向的msghdr已经发送完毕
/* Finished writing the current msg; advance to the next. */
c->msgcurr++;
}
if (c->msgcurr < c->msgused) {//所有的数据都已经发送完毕
ssize_t res;
struct msghdr *m = &c->msglist[c->msgcurr];
res = sendmsg(c->sfd, m, 0);
if (res > 0) {
//通过sendmsg返回值确定已经写了多少个iovec数组。循环减去每一个iovec数组的每一个
//元素的数据长度即可
while (m->msg_iovlen > 0 && res >= m->msg_iov->iov_len) {
res -= m->msg_iov->iov_len;
m->msg_iovlen--;
m->msg_iov++;
}
//只写了iovec结构体的部分数据
if (res > 0) {
m->msg_iov->iov_base = (caddr_t)m->msg_iov->iov_base + res;
m->msg_iov->iov_len -= res;
}
return TRANSMIT_INCOMPLETE;
}
} else {
return TRANSMIT_COMPLETE;
}
}
可以看到,即使transmit函数一次把所有的数据都写到了客户端,还是会调用transmit函数两次才能返回TRANSMIT_COMPLETE。当memcached把所有的数据都写回客户端后,就会调用conn_release_items函数释放对item的占用。
static void conn_release_items(conn *c) {
...
while (c->ileft > 0) {
item *it = *(c->icurr);
assert((it->it_flags & ITEM_SLABBED) == 0);
item_remove(it);
c->icurr++;
c->ileft--;
}
...
c->icurr = c->ilist;
}