剑指Offer笔记(java)
1、单例
//饿汉模式:线程安全,耗费资源。(线程安全的原因的是因为类加载初始化时就创建好一个静态对象了,
//以后线程若想使用实例化对象的话就直接使用就行了不必实例化了,因此不存在线程不安全的问题。)
public class Singleton {
private Singleton () {};
private static final Singleton instance=new Singleton();//一上来就直接创建对象实例
public static Singleton getInstance() {
return instance;
}
}
//懒汉模式1:线程不安全
public class Singleton {
private Singleton () {};
private static Singleton instance;
public static Singleton getInstance() {
if(instance==null) {//当前实例空的情况下,有可能出现两个线程同时创建实例对象,线程不安全
instance=new Singleton();
}
return instance;
}
}
//懒汉模式2:线程安全,给方法加锁,但是浪费资源
//优点:解决了多个实例对象的问题
//缺点:运行效率低下,下一个线程需要获取实例对象,必须等待上一个线程释放锁之后才能继续运行
public class Singleton {
private Singleton () {};
private static Singleton instance;
//同步机制保证一个线程在创建实例的同时其他线程只能等待,虽然线程安全,但这样会浪费资源
public synchronized static Singleton getInstance() {
if(instance==null) {
instance=new Singleton();
}
return instance;
}
}
//懒汉模式3:线程安全,双重检查锁
优点:可以避免整个方法被锁,只对需要锁的代码部分加锁,可提高执行效率。
public class Singleton {
private Singleton () {};
private volatile static Singleton instance;//volatile 防止指令重排序
public static Singleton getInstance() {
if(instance==null) {
synchronized(Singleton.class) {
if(instance==null){
instance=new Singleton();
}
}
}
return instance;
}
}
//静态内部类模式:线程安全,延迟加载
//静态内部类来实现单例,能够达到延迟加载和多线程的目的
public class Singleton {
private Singleton () {
System.out.println("初始化成员");
}
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton ();
}
public static Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}
//枚举模式:输出结果都是bbb
public class Test {
public enum Singleton{
instance1;
String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
public static void main(String[] args) {
Singleton instance1=Singleton.instance1;
Singleton instance2=Singleton.instance1;
instance1.setName("aaa");
instance2.setName("bbb");
System.out.println(instance1.getName());
System.out.println(instance2.getName());
}
}
2、二维数组中查找目标值
思想:二维数组是有序的,从右上角来看,向左数字递减,向下数字递增。
因此从右上角开始查找,
当要查找数字比右上角数字大时,下移;
当要查找数字比右上角数字小时,左移;
如果出了边界,则说明二维数组中不存在该整数。
public class Test
{
static boolean isInArray(int [][] arr ,int target) {
if(arr.length==0||arr[0].length==0) {//若行数0或者列数为0,则false
return false;
}
int m=0;//第一行
int n=arr[0].length-1;//最后一列
int temp=arr[m][n];//以矩阵右上角的数为当前点开始找
while(target!=temp) {
//因为右上角为起始点找目标值是:目标值大的向下移;目标值小的向左移,因此只要当前数列坐标>0且行坐标<行数-1,即没有出界,就接着找
if(n>0&&mtemp) {
m=m+1;//目标值大的向下移,行数+1
}else if(target 输出:true
3、替换字符串中的空格
O(N^2)解法
最直观的做法是从头到尾扫描字符串,每一次碰到空格字符的时候做替换。由于是把1个字符替换成3个字符,我们必须要把空格后面所有的字符都后移两个字节,否则就有两个字符被覆盖了。
O(N)解法
1)先遍历一次字符串,这样就能统计出字符串中空格的总数,并可以由此计算出替换之后的字符串的总长度。以前面的字符串"We are happy."为例,"We are happy."这个字符串的长度是14(包括结尾符号’\0’),里面有两个空格,因此替换之后字符串的长度是18。
2)从字符串的后面开始复制和替换。准备两个指针,P1和P2。P1指向原始字符串的末尾,而P2指向替换之后的字符串的末尾。接下来向前移动指针P1,逐个把它指向的字符复制到P2指向的位置,直到碰到第一个空格为止。接着向前复制,直到碰到第二、三或第n个空格。
public class Test7
{
public static String replaceSpace(StringBuffer str) {
int spaceNum=0;//空格数
for(int i=0;i=0) {//若前指针没有遍历完
if(str.charAt(front)==' ') {//前指针遇到空格
str.setCharAt(tail--, '0');
str.setCharAt(tail--, '2');
str.setCharAt(tail--, '%');
}else {//前指针没有遇到空格
str.setCharAt(tail--, str.charAt(front));
}
front--;
}
return str.toString();
}
public static void main(String args[]) {
StringBuffer s=new StringBuffer("It is Friday today.");
System.out.println(replaceSpace(s));
}
}
4、输入一个链表,从尾到头打印链表每个节点的值。
借助栈实现,或使用递归的方法。
(1)使用栈的方法:
import java.util.ArrayList;
import java.util.Stack;
class ListNode{
int val; //当前链表节点的值
ListNode nextNode=null; //下一个链表节点
ListNode(int val){
this.val=val;
}
}
public class Test
{
public static ArrayList printListFromTailToHead(ListNode ld){
ArrayList array=new ArrayList();//定义一个空链表用于存储栈顶弹出来的值
Stack stack=new Stack();
while(ld!=null) {//当前节点不为空的话
stack.push(ld.val);//将当前节点的值压进栈
ld=ld.nextNode;//节点后移
}
while(!stack.isEmpty()) {//栈不为空的话
array.add(stack.pop());//将栈顶的数值弹出加入链表中
}
return array;
}
public static void main(String args[]) {
ListNode head=new ListNode(-1);
ListNode node1=new ListNode(0);
ListNode node2=new ListNode(1);
ListNode node3=new ListNode(2);
head.nextNode=node1;
node1.nextNode=node2;
node2.nextNode=node3;
node3.nextNode=null;
ArrayList a=printListFromTailToHead(head);
for(int i=0;i 输出:2 1 0 -1
(2)利用Collections.reverse()
import java.util.ArrayList;
import java.util.Collections;
import java.util.Stack;
class ListNode{
int val; //当前链表节点的值
ListNode nextNode=null; //下一个链表节点
ListNode(int val){
this.val=val;
}
}
public class Test
{
public static ArrayList printListFromTailToHead(ListNode ld){
ArrayList array=new ArrayList();
while(ld!=null) {//当前节点不为空的话
array.add(ld.val);
ld=ld.nextNode;//节点后移
}
Collections.reverse(array);
return array;
}
public static void main(String args[]) {
ListNode head=new ListNode(-1);
ListNode node1=new ListNode(0);
ListNode node2=new ListNode(1);
ListNode node3=new ListNode(2);
head.nextNode=node1;
node1.nextNode=node2;
node2.nextNode=node3;
node3.nextNode=null;
ArrayList a=printListFromTailToHead(head);
for(int i=0;i 输出:2 1 0 -1
(3)利用递归方法
import java.util.ArrayList;
import java.util.Collections;
import java.util.Stack;
class ListNode{
int val; //当前链表节点的值
ListNode nextNode=null; //下一个链表节点
ListNode(int val){
this.val=val;
}
}
public class Test
{
public static ArrayList printListFromTailToHead(ListNode listNode) {
ArrayList arr = new ArrayList();
if(listNode != null){
arr = printListFromTailToHead(listNode.nextNode);//传入-1,0,1,2后终止,才执行下一条语句
arr.add(listNode.val);
}
return arr;
}
public static void main(String args[]) {
ListNode head=new ListNode(-1);
ListNode node1=new ListNode(0);
ListNode node2=new ListNode(1);
ListNode node3=new ListNode(2);
head.nextNode=node1;
node1.nextNode=node2;
node2.nextNode=node3;
node3.nextNode=null;
ArrayList a=printListFromTailToHead(head);
for(int i=0;i 输出:2 1 0 -1
5、由前序和中序遍历重建二叉树
题目描述
输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7,2,1,5,3,8,6},则重建二叉树并返回。
先来分析一下前序遍历和中序遍历得到的结果,
前序遍历第一位是根节点;
中序遍历中,根节点左边的是根节点的左子树,右边是根节点的右子树。
例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7,2,1,5,3,8,6}。
首先,根节点 是{ 1 };
左子树是:前序{ 2,4,7 } ,中序{ 4,7,2 };
右子树是:前序{ 3,5,6,8 } ,中序{ 5,3,8,6 };
这时,如果我们把左子树和右子树分别作为新的二叉树,则可以求出其根节点,左子树和右子树。
这样,一直用这个方式,就可以实现重建二叉树。
import java.util.LinkedList;
import java.util.Queue;
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) { val = x; }
TreeNode(){}
}
public class Test {
public static TreeNode reConstructBinaryTree(int [] preOrder,int [] inOrder)
{
int pLen = preOrder.length;
int iLen = inOrder.length;
if(pLen==0 || iLen==0 || pLen!=iLen)
{
return null;
}
return btConstruct( preOrder, inOrder, 0, pLen-1,0, iLen-1);
}
//构建方法,pStart和pEnd分别是前序遍历序列数组的第一个元素和最后一个元素;
//iStart和iEnd分别是中序遍历序列数组的第一个元素和最后一个元素。
public static TreeNode btConstruct(int[] preOrder, int[] inOrder, int pStart, int pEnd,int iStart,int iEnd)
{
//前序遍历根节点
TreeNode tree = new TreeNode(preOrder[pStart]);
tree.left = null;//初始化左子树
tree.right = null;//初始化右子树
if(pStart == pEnd && iStart == iEnd)
{
return tree;
}
int root = 0;
//找中序遍历中的根节点
for(root=iStart; root0)
{
tree.left = btConstruct(preOrder, inOrder, pStart+1, pStart+leftLength, iStart, root-1);
}
//遍历右子树
if(rightLength>0)
{
tree.right = btConstruct(preOrder, inOrder, pStart+leftLength+1, pEnd, root+1, iEnd);
}
return tree;
}
public static void printFromTop2Bottom(TreeNode root) {//按层打印二叉树
if (root != null) {
Queue list = new LinkedList<>();
list.add(root);
//当前节点
TreeNode currentNode;
TreeNode last = root;
//下一行最后的节点
TreeNode mlast = new TreeNode();
while (!list.isEmpty()) {
currentNode = list.remove();
System.out.print(currentNode.val + " ");
if (currentNode.left != null) {
list.add(currentNode.left);
mlast = currentNode.left;
}
if (currentNode.right != null) {
list.add(currentNode.right);
mlast = currentNode.right;
}
if (currentNode == last) {
System.out.print("\n");
last = mlast;
}
}
}
}
public static void main(String args[]) {
int pre []= {1,2,4,6,7,5,3};
int in[]= {6,4,7,2,5,1,3};
TreeNode t=reConstructBinaryTree(pre,in);
printFromTop2Bottom(t);
}
}
输出:
1
2 3
4 5
6 7
6、用两个栈来实现一个队列,完成队列的Push和Pop操作。 队列中的元素为int类型。
import java.util.Stack;
public class StacksToQueue {
static Stack stack1=new Stack();
static Stack stack2=new Stack();
public static void addToTail(int x) {//加入队尾
stack1.push(x);
}
public static int delHead() {//删除队首
if(stack1.size()+stack2.size()!=0) {//若队列不为空(队列长度即两个栈的长度之和)
if(stack2.isEmpty()) {//栈2为空
while(!stack1.isEmpty()) {//栈1 非空
stack2.push(stack1.pop());//把栈1的全部压入栈2
}
}
return stack2.pop();//栈2非空时,弹出
}
System.out.println("队列为空!");//队列长度为0时,不能删除队首
return -1;
}
public static void main(String [] args) {
StacksToQueue stq=new StacksToQueue();
stq.addToTail(1);
stq.addToTail(2);
stq.addToTail(3);
stq.addToTail(4);
System.out.println(stq.delHead());
stq.addToTail(5);
System.out.println(stq.delHead());
System.out.println(stq.delHead());
System.out.println(stq.delHead());
System.out.println(stq.delHead());
}
}
输出:
1
2
3
4
5
7.旋转数组的最小数字
题目:把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个递增排序的数组的一个旋转,输出旋转数组的最小元素。例如数组{3,4,5,1,2}为{1,2,3,4,5}的一个旋转,该数组的最小值为1。
这道题最直观的解法并不难,从头到尾遍历数组一次,我们就能找出最小的元素。这种思路的时间复杂度显然是O(n)。但是这个思路没有利用输入的旋转数组的特性,肯定达不到面试官的要求。
我们注意到旋转之后的数组实际上可以划分为两个排序的子数组,而且前面的子数组的元素都大于或者等于后面子数组的元素。我们还注意到最小的元素刚好是这两个子数组的分界线。在排序的数组中我们可以用二分查找法实现O(logn)的查找。
解题思路:
Step1.和二分查找法一样,我们用两个指针分别指向数组的第一个元素和最后一个元素。
Step2.接着我们可以找到数组中间的元素:如果该中间元素位于前面的递增子数组,那么它应该大于或者等于第一个指针指向的元素。此时数组中最小的元素应该位于该中间元素的后面。我们可以把第一个指针指向该中间元素,这样可以缩小寻找的范围。移动之后的第一个指针仍然位于前面的递增子数组之中。如果中间元素位于后面的递增子数组,那么它应该小于或者等于第二个指针指向的元素。此时该数组中最小的元素应该位于该中间元素的前面。
Step3.接下来我们再用更新之后的两个指针,重复做新一轮的查找。
public class Test {
public static int getMinVal(int [] array) {
if(array.length == 0){
return -1;
}
int left = 0;
int right = array.length - 1;
int middle = -1;
while(array[left] >= array[right]){//确保左边的子数组中的元素均>=右边的子数组中的元素
if(right - left == 1){//若数组中只有两个元素
middle = right;//则右边的指针指向的元素为最小值
break;
}
middle = (right+left)/2;
if(array[middle] >= array[left]){
left = middle;
}
if(array[middle] <= array[right]){
right = middle;
}
}
return array[middle];
}
public static void main(String [] args) {
int [] arr= {2,3,4,5,1,2};
System.out.println(getMinVal(arr));
}
}
输出:1
9、现在要求输入一个整数n,请你输出斐波那契数列的第n项。
方法一:递归,效率不高
public class Test {
public static long fibonacci(int n) {
if(n==0)
return 0;
if(n==1)
return 1;
return fibonacci(n-1)+fibonacci(n-2);
}
public static void main(String [] args) {
System.out.println(fibonacci(5));
}
}
输出:5
方法二:循环方式,效率高一些
public class Test {
public static long fibonacci(int n) {
int result=0;
int preOne=1;
int preTwo=0;
if(n==0)
return 0;
if(n==1)
return 1;
for(int i=2;i<=n;i++) {
result=preOne+preTwo;
preTwo=preOne;
preOne=result;
}
return result;
}
public static void main(String [] args) {
System.out.println(fibonacci(7));
}
}
输出:13
10、二进制中1的个数
方法一:把整数右移,与1进行与操作,但是当输入的数为负数时,可能引起死循环
public class Test {
public static int NumberOf1(int n) {
int count=0;
while(n>0) {
if((n&1)==1) {//整数n与1进行与操作若为1的话,表示该整数最右边一位为1
count++;
}
n=n>>1;//已知右移n,直到n=0
}
return count;
}
public static void main(String [] args) {
System.out.println(NumberOf1(10));
}
}
输出:2
方法二:常规解法,我们不把整数右移,而是把1不断左移与整数进行与操作
public class Test {
public static int NumberOf1(int n) {
int count=0;
int flag=1;
while(flag>0) {
if((flag&n)>0) {
count++;
}
flag=flag<<1;
}
return count;
}
public static void main(String [] args) {
System.out.println(NumberOf1(7));
}
}
输出:3
方法三:最好的方法,把一个整数减去1,再和原整数做与运算,若一个整数中有多少个1,就可以进行多少次这样的操作
public class Test {
public static int NumberOf1(int n) {
int count=0;
while(n>0) {
++count;
n=n&(n-1);
}
return count;
}
public static void main(String [] args) {
System.out.println(NumberOf1(7));
}
}
输出:3
11、数值的整数次方
方法一:不考虑大数的情况,直接利用for循环,循环exp次。
public class Test {
public static double power(double base,int exp) {
double result=1;
for(int i=1;i<=exp;i++) {
result=result*base;
}
return result;
}
public static void main(String [] args) {
System.out.println(power(2,10));
}
}
输出:1024.0
方法二:鲁棒性好的算法
public class Test {
public static double power1(double base,int exp) {
double result=1;
for(int i=1;i<=exp;i++) {
result=result*base;
}
return result;
}
public static boolean equal(double a,double b) {
if(Math.abs(a-b)<0.0000001)
return true;
else
return false;
}
public static double power2(double base,int exp) {
double result=0.0;
if(equal(base,0.0)&&exp<0) {// 首先比较底数为0,指数为负数的情况,这种情况没有意义
try {
throw new Exception("输入有误!");
}catch(Exception e) {
e.printStackTrace();
}
}
if(exp==0) {
return 1.0;
}
else if(exp<0) {
result= power1(1/base,-exp);
}
else if(exp>0){
result= power1(base,exp);
}
return result;
}
public static void main(String [] args) {
System.out.println(power2(2,-3));
}
}
输出:0.125
12、打印1到最大的Ñ位数
方法一:不好的做法:未考虑大数
public class Test {
public static void printNumber(int n){
int number=1;
for(int i=0;i输出:1 2 3 4 5 6 7 8 9
方法二:用字符串解决大数问题
public class Test {
public void printBigNumber(int n) {
if(n<=0) {
System.out.println("输入的数没意义");
return;
}
//创建数组
char number []=new char[n];
//初始化数组
for(int i=0;i=0;i--) {
int curNum=number[i]-'0'+nTakeOver;//取到第i位的字符转换为数字 +进位符
if(i==number.length-1) {//末位自加1
curNum++;
}
if(curNum>=10) {
if(i==0) {//若最高为>=10
isOverflow=true;
}
else { //若其他位>=10
curNum=curNum-10;//当前数值-10
nTakeOver=1;//进位符置1
number[i]=(char)(curNum+'0');//将当前数值转换为字符型赋值给数组第i位
}
}
else {
number[i]=(char)(curNum+'0');//将当前数值转换为字符型赋值给数组第i位
break;//跳出循环
}
}
return isOverflow;//返回溢出标识符
}
public void printNumber(char [] number) {
boolean isBeginning0=true;//0开始标识符
for(int i=0;i 输出:
1
2
3
4
5
6
7
8
9
方法三:递归
public class Test {
public void printBigNumber(int n) {
if(n<=0) {
System.out.println("输入的数没意义");
return;
}
//创建数组
char number []=new char[n];
//初始化数组
for(int i=0;i输出:
1
2
3
4
5
6
7
8
9
13.O(1)时间删除链表节点
思路1:找到前一个指针pre,赋值pre->next = p->next,删掉p
思路2:目的是删除p,但是不删p,直接用p->next的值赋值给p,把p->next删除掉(好处:不用遍历找到p的前一个指针pre,O(1)时间内搞定)
于是,定位到思路2,但是思路2有两个特例:
1、删除的是尾节点,需要遍历找到前一个节点
2、整个链表就一个结点(属于删尾节点,但没法找到前面的节点,需要开小灶单独处理)
待删节点不是尾节点:待删节点的值先用待删节点的下一个节点的值覆盖,最后删掉待删节点的下一个节点。
待删节点是尾节点,且待删节点同时是头节点(链表唯一一个节点):删掉头节点。
待删节点是尾节点,但待删节点不是头节点:找到待删节点的前趋节点,前一个节点的next赋值为空,删掉待删节点。
class ListNode{
public int val;
ListNode next;
ListNode(int data){
this.val=data;
next=null;
}
}
public class Test {
public void delNode(ListNode head,ListNode delNode) {
if(head==null||delNode==null)
return;
if(delNode.next!=null) {//待删除节点不是尾节点
ListNode nextNode=delNode.next;
delNode.val=nextNode.val;
delNode.next=nextNode.next;
}else if(delNode==head) {//待删除节点是尾节点,且链表只有一个节点,即删除头(尾)节点
head=null;
delNode=null;
}else {//待删除节点是非头节点的尾节点
ListNode pNode=head;
while(pNode.next!=delNode) {
pNode=pNode.next;
}
pNode.next=null;
}
}
public static void main(String[] args) {
ListNode head=new ListNode(1);
ListNode l2=new ListNode(2);
ListNode l3=new ListNode(3);
ListNode l4=new ListNode(4);
ListNode l5=new ListNode(5);
head.next=l2;
l2.next=l3;
l3.next=l4;
l4.next=l5;
new Test().delNode(head,l3);
ListNode n=head;
while(n!=null) {
System.out.print(n.val+" ");
n = n.next;
}
System.out.println();
}
}
输出:1 2 4 5
14、使数组中的奇数位于偶数前面
要求:输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇数位于数组的前半部分,所有的偶数位于位于数组的后半部分,并保证奇数和奇数,偶数和偶数之间的相对位置不变。
思想:如果没有要求奇数之间、偶数之间的相对位置的话,可以直接用2个指针变量,左边往右扫到偶数就暂停,右边往左扫到奇数就暂停然后交换,依次往返,结束条件为两个指针变量的相遇。
但是这里有了这个要求,不能这样做了,考虑用空间换时间,如果遇到奇数就用一个数组存起来,遇到偶数再用另一个数组存起来就需要2个额外的数组,再最后合并到一个数组里,这是一个思路(或者2个队列也是同样的思路),现在这里优化一下,只申请一个额外的数组,将原来的数组从左往右扫,遇到奇数就存到新数组的左边,同时将原来的数组从右往左扫,遇到偶数就存到新数组的右边,这样就可以保证左边是奇数,右边是偶数,且奇数之间、偶数之间相对位置不变,再合并到原数组就ok了。
不考虑相对位置的情况:
public class Test {
public static void reorderArray(int[] array) {
if(array==null||array.length<=0)
return ;
int start=0;
int end=array.length-1;
while(start<=end) {
if((array[start]&1)==1&&((array[end]&1)==0)) {
start++;
end--;
}else if((array[start]%1==0)&&((array[end]&1)==0)) {
end--;
}else if(((array[start]&1)==0)&&((array[end]&1)==1)){
int temp=array[start];
array[start]=array[end];
array[end]=temp;
start++;
end--;
}else {
start++;
}
}
}
public static void main(String[] args){
int[] num= {3,4,1,2,5};
reorderArray(num);
for(int data:num) {
System.out.print(data+" ");
}
}
}
输出:3 5 1 2 4
考虑相对位置的情况:
public class Test {
public void reorderArray(int[] array) {
int[] newArray=new int[array.length];
int start=0;
int end=array.length-1;
for(int i=0;i输出:3 5 7 1 2 4 6
15、找链表中倒数第K个节点
思路:定义快慢指针,首先让快慢指针指向头节点,求倒数第K个节点,则先让快节点往前走k-1步,然后快慢指针再同步往后移,直到快指针指向最后一个节点的时候,慢指针指向的节点就是我们要求的节点。
class ListNode{
int data;
ListNode next;
public ListNode(int x){
this.data=x;
next=null;
}
}
class Test {
public static ListNode findKthElement(ListNode head,int k) {
if(head==null||k<=0)
return null;
ListNode fast=head;
ListNode slow=head;
for(int i=0;i输出:4
16.输入一个链表,反转链表后,输出链表的所有元素
class ListNode{
int data;
ListNode next;
public ListNode(int x){
this.data=x;
next=null;
}
}
class Test {
public static ListNode ReverseList(ListNode head) {
if(head==null||head.next==null)
return head;
//当链表超过两个及以上就需要反转
ListNode pre = null;//用于保存当前节点的前一个节点
ListNode cur = head;//cur保存当前节点
while(cur != null){
ListNode next = cur.next;//获取当前节点的下一个元素
cur.next = pre;//把当前节点的next指向前一个元素
pre = cur;//把当前节点改为前一个节点(其实就是前一个元素后移一位)。
cur = next;//把当前节点的下一个节点改为当前节点(其实就是前一个元素后移一位)。
}
//因为反转后pre是第一个节点,所以返回pre.
return pre;
}
public static void printList(ListNode head) {
ListNode cur=head;
while(cur!=null) {
System.out.print(cur.data+" ");
cur=cur.next;
}
System.out.println();
}
public static void main(String[] args) {
ListNode head=new ListNode(1);
ListNode l1=new ListNode(2);
ListNode l2=new ListNode(3);
ListNode l3=new ListNode(4);
ListNode l4=new ListNode(5);
head.next=l1;
l1.next=l2;
l2.next=l3;
l3.next=l4;
System.out.println("反转前的链表:");
printList(head);
ListNode reHead=ReverseList(head);
System.out.println("反转后的链表:");
printList(reHead);
}
}
输出:
反转前的链表:
1 2 3 4 5
反转后的链表:
5 4 3 2 1
17、合并两个有序链表
递归做法:
class ListNode{
int data;
ListNode next;
public ListNode(int x){
this.data=x;
next=null;
}
}
class Test {
/***************递归*****************/
public static ListNode Merge(ListNode l1, ListNode l2) {
if(l1 == null) return l2;
if(l2 == null) return l1;
if(l1.data <= l2.data){
l1.next = Merge(l1.next,l2);
return l1;
}
else{
l2.next = Merge(l2.next,l1);
return l2;
}
}
/*打印链表*/
public static void printList(ListNode head) {
ListNode cur=head;
while(cur!=null) {
System.out.print(cur.data+" ");
cur=cur.next;
}
System.out.println();
}
public static void main(String[] args) {
ListNode head=new ListNode(1);
ListNode l1=new ListNode(2);
ListNode l2=new ListNode(5);
ListNode l3=new ListNode(7);
ListNode l4=new ListNode(8);
head.next=l1;
l1.next=l2;
l2.next=l3;
l3.next=l4;
ListNode head2=new ListNode(3);
ListNode n1=new ListNode(4);
ListNode n2=new ListNode(6);
head2.next=n1;
n1.next=n2;
printList(Merge(head,head2));
}
}
输出:1 2 3 4 5 6 7 8
非递归做法:新建一个辅助链表,谁小谁先进新链表,然后归并。
class ListNode{
int data;
ListNode next;
public ListNode(int x){
this.data=x;
next=null;
}
}
class Test {
/***************非递归*****************/
public static ListNode Merge(ListNode l1,ListNode l2) {
ListNode XHead=new ListNode(0);
ListNode cur=XHead;
while(l1!=null && l2!=null) {
if(l1.data<=l2.data) {
cur.next=new ListNode(l1.data);
cur=cur.next;
l1=l1.next;
}else {
cur.next=new ListNode(l2.data);
cur=cur.next;
l2=l2.next;
}
}
while(l1!=null) {
cur.next=new ListNode(l1.data);
cur=cur.next;
l1=l1.next;
}
while(l2!=null) {
cur.next=new ListNode(l2.data);
cur=cur.next;
l2=l2.next;
}
return XHead.next;
}
/*打印链表*/
public static void printList(ListNode head) {
ListNode cur=head;
while(cur!=null) {
System.out.print(cur.data+" ");
cur=cur.next;
}
System.out.println();
}
public static void main(String[] args) {
ListNode head=new ListNode(1);
ListNode l1=new ListNode(2);
ListNode l2=new ListNode(5);
ListNode l3=new ListNode(7);
ListNode l4=new ListNode(8);
head.next=l1;
l1.next=l2;
l2.next=l3;
l3.next=l4;
ListNode head2=new ListNode(3);
ListNode n1=new ListNode(4);
ListNode n2=new ListNode(6);
head2.next=n1;
n1.next=n2;
printList(Merge(head,head2));
}
}
输出:1 2 3 4 5 6 7 8
18、判断二叉树A中是否包含子树B
思想:首先判断两个树的根节点是否为空,如果有一者为空,则返回false。否则在A树中遍历查找跟B树根节点值一样的节点R,找到的话,比较以R为根节点的子树是否包含B树。
class TreeNode{
int val;
TreeNode left;
TreeNode right;
public TreeNode(int x) {
this.val=x;
this.left=null;
this.right=null;
}
}
class Test {
public static boolean hasSubTree(TreeNode root1,TreeNode root2) {
boolean result=false;
if(root1!=null && root2!=null) {
if(root1.val==root2.val) {
result=hasSubTree2(root1,root2);
}
if(!result) {
result=hasSubTree(root1.left,root2)||hasSubTree(root1.right,root2);
}
}
return result;
}
public static boolean hasSubTree2(TreeNode A,TreeNode B) {
if(B==null) return true;
if(A==null) return false;
if(A.val!=B.val)
return false;
return hasSubTree2(A.left,B.left)&&hasSubTree2(A.right,B.right);
}
public static void main(String[] args) {
TreeNode root1=new TreeNode(6);
root1.left=new TreeNode(8);
root1.right=new TreeNode(7);
root1.left.left=new TreeNode(9);
root1.left.right=new TreeNode(2);
root1.left.right.left=new TreeNode(4);
root1.left.right.right=new TreeNode(7);
TreeNode root2=new TreeNode(8);
root2.left=new TreeNode(9);
root2.right=new TreeNode(2);
System.out.println(hasSubTree(root1,root2));
}
}
输出:true
19、二叉树的镜像
思想:先序遍历整个树的每个结点,如果遍历到的结点有子结点,就交换它的两个子结点。当交换完所有非叶子结点之后,就得到了树的镜像。
import java.util.ArrayList;
import java.util.LinkedList;
class TreeNode{
int val;
TreeNode left;
TreeNode right;
public TreeNode(int x) {
this.val=x;
this.left=null;
this.right=null;
}
}
class Test {
public static void MirrorTree(TreeNode root) {
if(root==null||(root.left==null&&root.right==null))
return ;
TreeNode temp=root.left;
root.left=root.right;
root.right=temp;
if(root.left!=null)
MirrorTree(root.left);
if(root.right!=null)
MirrorTree(root.right);
}
/*按层打印树节点*/
public static ArrayList printTreeByLayer(TreeNode root){
ArrayList list=new ArrayList();
if(root==null)
return list;
LinkedList queue=new LinkedList();
queue.offer(root);
while(!queue.isEmpty()) {
TreeNode n=queue.poll();
list.add(n.val);
if(n.left!=null) {
queue.offer(n.left);
}
if(n.right!=null) {
queue.offer(n.right);
}
}
return list;
}
public static void main(String[] args) {
TreeNode root1=new TreeNode(8);
root1.left=new TreeNode(8);
root1.right=new TreeNode(7);
root1.left.left=new TreeNode(9);
root1.left.right=new TreeNode(2);
root1.left.right.left=new TreeNode(4);
root1.left.right.right=new TreeNode(7);
System.out.println("镜像前:");
ArrayList list=printTreeByLayer(root1);
for(int i=0;i list2=printTreeByLayer(root1);
for(int i=0;i 输出:
镜像前:
8 8 7 9 2 4 7
镜像前:
8 7 8 2 9 7 4
20、顺时针打印矩阵
class Test {
public static void printMatrixClockwisely(int[][] num,int row,int column) {
if(num==null||row<=0||column<=0)
return;
int start=0;
while(row>2*start&&column>2*start) {
printMatrixInCircle(num,row,column,start);
start++;
}
}
public static void printMatrixInCircle(int[][] num,int row,int column,int start) {
int endX=column-1-start;//终止列号
int endY=row-1-start;//终止行号
//从左到右打印一行
for(int i=start;i<=endX;i++) {
System.out.print(num[start][i]+" ");
}
//从上往下打印一列:满足条件为终止行号必须大于起始行号
if(endY>start) {
for(int i=start+1;i<=endY;i++) {
System.out.print(num[i][endX]+" ");
}
}
//从右往左打印一行:满足条件为要打印的数组必须至少有2行2列
if(endX>start&&endY>start) {
for(int i=endX-1;i>=start;i--) {
System.out.print(num[endY][i]+" ");
}
}
//从下往上打印一列:满足条件为要打印数组必须至少有3行2列
if(endY-1>start&&endX>start) {
for(int i=endY-1;i>start;i--) {
System.out.print(num[i][start]+" ");
}
}
}
public static void main(String[] args) {
int[][] num= {{1,2,3},{4,5,6},{7,8,9}};
printMatrixClockwisely(num,3,3);
}
}
输出:1 2 3 6 9 8 7 4 5
另一种简短的写法:
public class Test{
public static void print(int[][] matrix) {
int LR=0;//左上角坐标的行
int LC=0;//左上角坐标的列
int RR=matrix.length-1;//右下角坐标的行
int RC=matrix[0].length-1;//右下角坐标的列
while(LR<=RR && LC<=RC) {
printEdge(matrix,LR++,LC++,RR--,RC--);
}
}
public static void printEdge(int[][] m,int LR,int LC,int RR,int RC) {
if(LR==RR) {//当左上角的行等于右下角的行
for(int i=LC;i<=RC;i++) {
System.out.print(m[LR][i]+" ");
}
}else if(LC==RC) {//当左上角的列等于右下角的列
for(int i=LR;i<=RR;i++) {
System.out.print(m[i][LC]+" ");
}
}else {
int curC=LC;
int curR=LR;
//打印上边框
while(curC!=RC) {
System.out.print(m[LR][curC]+" ");
curC++;
}
//打印右边框
while(curR!=RR){
System.out.print(m[curR][RC]+" ");
curR++;
}
//打印下边框
while(curC!=LC) {
System.out.print(m[RR][curC]+" ");
curC--;
}
//打印左边框
while(curR!=LR) {
System.out.print(m[curR][LC]+" ");
curR--;
}
}
}
public static void main(String[] args) {
int[][] matrix= {{1,2,3},{4,5,6},{7,8,9}};
print(matrix);
}
}
输出:1 2 3 6 9 8 7 4 5
21、包含min函数的栈
思想:
这题关键在于用辅助栈储存什么值。要保证辅助栈的top是最小值,pop之后的顶部仍然是最小值。也就是说辅助栈从上到下存储的应该是最小值->次小值->次次小值……
当两个栈为空时,push进去的第一个值即为最小值;
push第二个元素时,若push的值<辅助栈顶元素(此处即第一个值),则将此值压进辅助栈;
若push的值大于等于辅助栈顶元素,则将辅助栈顶元素再次push进去。
import java.util.Stack;
class Test {
Stack data=new Stack();//数据栈,普通的栈
Stack min=new Stack();//辅助栈,用于存储最小元素
//压栈
public void push(int node) {
data.push(node);
if(min.isEmpty()) {
min.push(node);//当两个栈为空时,push进去的第一个值即为最小值
}else {
if(node 输出:
3
6
3
22、判断一个栈是否是另一个栈的弹出序列
【参考思路】借用一个辅助栈,遍历压栈顺序,先将第一个放入栈中,这里是1,然后判断栈顶元素是不是出栈顺序的第一个元素,这里是4,很显然1≠4,所以我们继续压栈,直到相等以后开始出栈。出栈一个元素,则将出栈顺序向后移动一位,这样循环等压栈顺序遍历完成,如果辅助栈还不为空,说明弹出序列不是该栈的弹出顺序。
举例:
入栈1,2,3,4,5
出栈4,5,3,2,1
首先1入辅助栈,此时栈顶1≠4,继续入栈2
此时栈顶2≠4,继续入栈3
此时栈顶3≠4,继续入栈4
此时栈顶4=4,出栈4,弹出序列向后移一位,此时为5,辅助栈里面是1,2,3
此时栈顶3≠5,继续入栈5
此时栈顶5=5,出栈5,弹出序列向后一位,此时为3,,辅助栈里面是1,2,3
import java.util.Stack;
class Test {
public static boolean isOrder(int[]in,int[]out) {
Stack tempStack=new Stack();
int index=0;
for(int i=0;i 输出:true
23、层序遍历二叉树
方法1:
import java.util.ArrayList;
import java.util.LinkedList;
class TreeNode{
int val;
TreeNode left;
TreeNode right;
public TreeNode(int v) {
this.val=v;
this.left=null;
this.right=null;
}
}
class Test {
public static ArrayList printTreeByLayer(TreeNode root){
ArrayList list=new ArrayList();
if(root==null)
return list;
LinkedList queue=new LinkedList();
queue.offer(root);
while(!queue.isEmpty()) {
TreeNode n=queue.pop();
list.add(n.val);
if(n.left!=null) {
queue.offer(n.left);
}
if(n.right!=null) {
queue.offer(n.right);
}
}
return list;
}
public static void main(String[] args) {
TreeNode root=new TreeNode(1);
root.left=new TreeNode(2);
root.right=new TreeNode(5);
root.left.left=new TreeNode(4);
root.right.right=new TreeNode(7);
ArrayList res=printTreeByLayer(root);
System.out.println(res);
}
}
输出:[1, 2, 5, 4, 7]
方法2:
import java.util.LinkedList;
import java.util.Queue;
class TreeNode{
int val;
TreeNode left;
TreeNode right;
public TreeNode(int v) {
this.val=v;
this.left=null;
this.right=null;
}
public TreeNode() {}
}
public class Test {
public static void printFromTop2Bottom(TreeNode root) {//按层打印二叉树
if (root != null) {
Queue list = new LinkedList<>();
list.add(root);
//当前节点
TreeNode currentNode;
TreeNode last = root;
//下一行最后的节点
TreeNode mlast = new TreeNode();
while (!list.isEmpty()) {
currentNode = list.remove();
System.out.print(currentNode.val + " ");
if (currentNode.left != null) {
list.add(currentNode.left);
mlast = currentNode.left;
}
if (currentNode.right != null) {
list.add(currentNode.right);
mlast = currentNode.right;
}
if (currentNode == last) {
System.out.print("\n");
last = mlast;
}
}
}
}
public static void main(String[] args) {
TreeNode root=new TreeNode(1);
root.left=new TreeNode(2);
root.right=new TreeNode(5);
root.left.left=new TreeNode(4);
root.right.right=new TreeNode(7);
printFromTop2Bottom(root);
}
}
输出:
1
2 5
4 7
方法3:
import java.util.ArrayList;
import java.util.LinkedList;
class TreeNode{
int val;
TreeNode left;
TreeNode right;
public TreeNode(int v) {
this.val=v;
this.left=null;
this.right=null;
}
public TreeNode() {}
}
public class Test {
static ArrayList> Print(TreeNode root) {
ArrayList> res=new ArrayList>();
if(root==null)
return res;
LinkedList list=new LinkedList();
ArrayList layerRes=new ArrayList();
list.add(root);
int start=0;
int end=1;
while(!list.isEmpty()){
TreeNode curNode=list.poll();
layerRes.add(curNode.val);
start++;
if(curNode.left!=null){
list.add(curNode.left);
}
if(curNode.right!=null){
list.add(curNode.right);
}
if(start==end){
res.add(layerRes);
start=0;
end=list.size();
layerRes=new ArrayList();
}
}
return res;
}
public static void main(String[] args) {
TreeNode root=new TreeNode(1);
root.left=new TreeNode(2);
root.right=new TreeNode(5);
root.left.left=new TreeNode(4);
root.right.right=new TreeNode(7);
System.out.println(Print(root));
}
}
输出:[[1], [2, 5], [4, 7]]
24、二叉树中和为某值的路径
题目:输入一棵二叉树和整数,打印出二叉树中节点值得和为输入整数的所有路径。从树的根节点开始往下一直到叶节点所经过的节点形成一条路径。
解题思路:路径从根节点开始,应该用类似于前序遍历的方式访问树节点。我们需要整个路径,就需要一个容器保存经过路径上的节点,以及一个变量记录当前已有节点元素的和。当前序遍历到某一个节点时,添加该节点到路径,累加节点值。如果该节点为叶子节点并节点值累计等于目标整数,则找到一条路径。如果不是叶子节点,则继续访问子节点。一个节点访问结束后,递归函数自动回到其父节点。
import java.util.ArrayList;
class TreeNode{
int val;
TreeNode left;
TreeNode right;
public TreeNode(int x) {
this.val=x;
this.left=null;
this.right=null;
}
}
class Test {
ArrayList> pathList=new ArrayList>();// pathList存所有可能路径
ArrayList path=new ArrayList(); // path用来保存路径的数据结构
public ArrayList> findPath(TreeNode root,int sum){
if(root==null)
return pathList;
path.add(root.val);
sum-=root.val;
if(sum==0&&root.left==null&&root.right==null) {// 路径值等于0,且当前节点是叶子节点 则找到一条路径
pathList.add(new ArrayList(path));
}
if(root.left!=null) {//递归左子树
findPath(root.left,sum);
}
if(root.right!=null) {//递归右子树
findPath(root.right,sum);
}
path.remove(path.size()-1);// 当访问到叶子节点,且此时的sum不为0,需要删除路径中最后一个节点,回退至父节点
return pathList;
}
public static void main(String[] args) {
TreeNode root=new TreeNode(10);
root.left=new TreeNode(5);
root.right=new TreeNode(12);
root.left.left=new TreeNode(4);
root.left.right=new TreeNode(7);
Test test=new Test();
ArrayList> list=test.findPath(root,22);
System.out.println(list);
}
}
输出:[[10, 5, 7], [10, 12]]
25、复杂链表的复制
对一个复杂链表进行复制,一般有三个思路(最好的是第三个)。
思路一:
把复制过程分成两步:第一步复制原始链表上的每一个结点,并用next链接起来;第二步设置每个结点的random 指针。这样一来,对于一个含有n个结点的链表,由于定位每一个结点的random都需要从链表的头结点开始经过O(n)步才能找到,故总时间复杂度是O(n2)。
思路二:
思路一的时间花费主要在定位结点的random上,故我们可以对此优化:用空间换时间。还是分为两步:第一步复制原始链表上的每一个结点N创建N’,然后把这些创建出来的结点用next链接起来。同时把的配对信息放到一个哈希表中。第二步设置每个结点的random 指针。如果原始链表中结点N的random指针指向S,在复制链表中,对应的N’指向S’,可以利用哈希表在O(1)的时间根据S找到S’。我们用O(n)的空间消耗把时间复杂度由O(n2)降到了O(n)。
import java.util.HashMap;
class ComplexListNode{
int val;
ComplexListNode next;
ComplexListNode sibling;
public ComplexListNode(int val) {
this.val=val;
}
}
class Test7 {
public ComplexListNode clone(ComplexListNode pHead){
if(pHead == null){
return null;
}
HashMap map = new HashMap();
ComplexListNode pClonedHead = new ComplexListNode(pHead.val); //复制链表的头结点
ComplexListNode pNode = pHead, pClonedNode = pClonedHead;
map.put(pNode, pClonedNode);
//第一步,hashMap保存,原链表节点映射复制链表节点
while(pNode.next != null){
pClonedNode.next = new ComplexListNode(pNode.next.val);
pNode = pNode.next;
pClonedNode = pClonedNode.next;
map.put(pNode, pClonedNode);
}
//第二步:找到对应的sibling
pNode = pHead;
pClonedNode = pClonedHead;
while(pClonedNode!=null){
pClonedNode.sibling = map.get(pNode.sibling);
pNode = pNode.next;
pClonedNode = pClonedNode.next;
}
return pClonedHead;
}
public static void main(String[] args) {
ComplexListNode head=new ComplexListNode(1);
ComplexListNode b=new ComplexListNode(2);
ComplexListNode c=new ComplexListNode(3);
ComplexListNode d=new ComplexListNode(4);
ComplexListNode e=new ComplexListNode(5);
head.next=b;
head.sibling=c;
b.next=c;
b.sibling=e;
c.next=d;
c.sibling=null;
d.next=e;
d.sibling=b;
e.next=null;
e.sibling=null;
ComplexListNode newlist=new Test7().clone(head);
while(newlist!=null){
System.out.print(newlist.val+" ");
if(newlist.sibling!=null){
System.out.print(newlist.sibling.val);
}
System.out.println();
newlist=newlist.next;
}
}
}
输出:
1 3
2 5
3
4 2
5
思路三: 不用O(n)的空间复杂度来实现O(n)的时间效率。
第一步:让仍然是根据原始链表的每个结点N创建对应的N’。不过我们把N’链接在N的后面。
第二步:设置复制出来的结点的sibling。原始链表上的A的sibling指向结点C,那么其对应复制出来的A’是A的next指向的结点,同样C’也是C的next指向的结点。即A’ = A.next,A’.sibling= A.sibling.next;故像这样就可以把每个结点的m_pSibling设置完毕。
第三步:将这个长链表拆分成两个链表:把奇数位置的结点用next链接起来就是原始链表,把偶数位置的结点用next链接起来就是复制出来的链表。
class ComplexListNode{
int val;
ComplexListNode next;
ComplexListNode sibling;
public ComplexListNode() {
}
public ComplexListNode(int val) {
super();
this.val=val;
}
}
class Test7 {
public ComplexListNode clone(ComplexListNode pHead)
{
if(pHead==null) return null;
//复制原始链表并创建新节点N',把N'连接到N的后面
ComplexListNode pNode=pHead;
while(pNode!=null){
ComplexListNode pClone=new ComplexListNode(pNode.val);
pClone.next=pNode.next;
pNode.next=pClone;
pClone.sibling=null;
pNode=pClone.next;
}
//设置N'的random
ComplexListNode pNode2=pHead;
while(pNode2!=null){
if(pNode2.sibling!=null){
pNode2.next.sibling=pNode2.sibling.next;
}
pNode2=pNode2.next.next;
}
//把长链表拆分成两个链表,奇数位置节点是原始链表,偶数位置的结点是复制后的链表
ComplexListNode pNode3=pHead;
ComplexListNode pCloneHead=null;
ComplexListNode pCloneNode=null;
if(pNode3!=null){
pCloneHead=pCloneNode=pNode3.next;
pNode3.next=pCloneNode.next;
pNode3=pNode3.next;
}
while(pNode3!=null){
pCloneNode.next=pNode3.next;
pCloneNode=pCloneNode.next;
pNode3.next=pCloneNode.next;
pNode3=pNode3.next;
}
return pCloneHead;
}
public static void main(String[] args) {
ComplexListNode head=new ComplexListNode(1);
ComplexListNode b=new ComplexListNode(2);
ComplexListNode c=new ComplexListNode(3);
ComplexListNode d=new ComplexListNode(4);
ComplexListNode e=new ComplexListNode(5);
head.next=b;
head.sibling=c;
b.next=c;
b.sibling=e;
c.next=d;
c.sibling=null;
d.next=e;
d.sibling=b;
e.next=null;
e.sibling=null;
ComplexListNode newlist=new Test7().clone(head);
while(newlist!=null){
System.out.print(newlist.val+" ");
if(newlist.sibling!=null){
System.out.print(newlist.sibling.val);
}
System.out.println();
newlist=newlist.next;
}
}
}
输出 :
1 3
2 5
3
4 2
5
26、二叉搜索树转换为双向链表
首先定义左右两个链表节点,每次从右面插入节点,既然是一棵二叉搜索树那么最小的一定是最左面的节点,所以1、我们递归找到最左面的节点,先放一个节点。2、递归二叉树的右节点,有则插入节点。
class TreeNode{
int val;
TreeNode left;
TreeNode right;
public TreeNode(int val) {
this.val=val;
}
}
class Test7 {
//双向链表的左边头结点和右边头节点
TreeNode leftHead = null;
TreeNode rightHead = null;
public TreeNode Convert(TreeNode root) {
//递归调用叶子节点的左右节点返回null
if(root==null) return null;
//第一次运行时,它会使最左边叶子节点为链表第一个节点
Convert(root.left);
if(rightHead==null){//表示链表中还加入没有元素
leftHead= rightHead = root;
}else{
//把根节点插入到双向链表右边,rightHead向后移动
rightHead.right = root;
root.left = rightHead;
rightHead = root;
}
//把右叶子节点也插入到双向链表(rightHead已确定,直接插入)
Convert(root.right);
//返回左边头结点
return leftHead;
}
public static void main(String[] args) {
TreeNode root=new TreeNode(10);
root.left=new TreeNode(6);
root.right=new TreeNode(14);
root.left.left=new TreeNode(4);
root.left.right=new TreeNode(8);
root.right.left=new TreeNode(12);
root.right.right=new TreeNode(16);
TreeNode node=new Test7().Convert(root);
while(node!=null) {
System.out.print(node.val+" ");
node=node.right;
}
}
}
输出:4 6 8 10 12 14 16
27、打印字符串中所有字符的排列(字符串全排列)
思路:面对这样的题目,我们需要将复杂问题分解化,分解成一个一个小问题。将一个字符串分为两部分:第一部分为它的第一个字符,第二部分为后面所有的字符。
求整个字符串的全排列,可以看成两步:第一步首先求所有可能出现在第一个位置的字符,即把第一个字符和后面所有的字符交换;第二步固定第一个字符,求后面所有字符的排列。这时候仍然把后面的字符分成两部分,后面的第一个字符,和这个字符之后的所有字符,然后把后面的第一个字符和它后面的字符交换。
注:(a)把字符串分成两部分,一部分是字符串的第一个字符,另一部分是第一个字符以后的所有字符(有阴影背景的区域)。接下来我们求阴影部分的字符串的排列。(b)拿第一个字符和它后面的字符逐个交换。
import java.util.ArrayList;
import java.util.Set;
import java.util.TreeSet;
public class Test {
static ArrayList res=new ArrayList();
public static ArrayList Permutation(String s){
if(s==null||s.length()==0)
return res;
char[] a=s.toCharArray();
TreeSet set=new TreeSet();
findPermutation(a,0,set);
res.addAll(set);
return res;
}
public static void findPermutation(char[] arr,int index,TreeSet set) {
if(arr==null||arr.length==0)
return ;
if(index<0||index>=arr.length)
return ;
if(index==arr.length-1) {
set.add(String.valueOf(arr));
}else {
for(int i=index;i 输出:[abc, acb, bac, bca, cab, cba]
28、数组中出现次数超过一半的数字
解法1:用HashMap保存数组中每个元素的值和出现次数,如果加入的是已有的元素,则次数+1,如果加入的是新元素,则次数置1。出现次数>数组长度一半的元素为要找的结果。
import java.util.*;
public class Test {
public static int MoreThanHalfNum(int[] arr) {
if(arr==null||arr.length==0)
return 0;
HashMap map=new HashMap();
for(int i=0;iarr.length>>1)
return arr[i];
}
return 0;
}
public static void main(String[] args) {
int[] arr= {1,2,1,2,2,2,1,1,2};
int num=MoreThanHalfNum(arr);
System.out.println(num);
}
}
输出:2
解法2: 如果有符合条件的数字,则它出现的次数比其他所有数字出现的次数和还要多。在遍历数组时保存两个值:一是数组中一个数字,一是次数。遍历下一个数字时,若它与之前保存的数字相同,则次数加1,否则次数减1;若次数为0,则保存下一个数字,并将次数置为1。遍历结束后,所保存的数字即为所求。然后再判断它是否符合条件即可。
public class Test {
public static int MoreThanHalfNum(int[] arr) {
if(arr==null||arr.length<=0)
return 0;
int result=arr[0];//先假设数组第一个元素为出现次数最多的元素result
int count=1;
//找出数组中出现次数最多的元素result
for(int i=1;i数组长度一半
if(times>arr.length>>1) {
return result;
}else {
return 0;
}
}
public static void main(String[] args) {
int[] arr= {1,2,1,2,2,2,1,1,2};
int num=MoreThanHalfNum(arr);
System.out.println(num);
}
}
输出:2
解法3:可以现将数组进行排序(这里用快排),则在数组中出现次数超过一半的元素一定会出现在数组中位数的位置。
class Test {
public static void quickSort(int[] arr) {
int[] p=quickSort(arr,0,arr.length-1);
quickSort(arr,0,p[0]-1);
quickSort(arr,p[1]+1,arr.length-1);
}
public static int[]quickSort(int[] arr,int L,int R) {
int less=L-1;
int more=R;
int cur=L;
while(cur<=more) {
if(arr[cur]arr[R]) {
swap(arr,--more,cur);
}else {
cur++;
}
}
swap(arr,more,R);
return new int[] {less+1,more};
}
public static void swap(int[] arr,int a,int b) {
int tmp=arr[a];
arr[a]=arr[b];
arr[b]=tmp;
}
public static int MoreThanHalfNum(int[] arr) {
if(arr==null|arr.length==0)
return -1;
quickSort(arr);
return arr[arr.length/2];
}
public static void main(String[] args) {
int[] arr= {1,2,3,3,3,3,4,1,2,2,2,2,2,2,2,2,2};
System.out.println(MoreThanHalfNum(arr));
}
}
输出:2
29、找出最小的K个数
思路:O(n)的算法,只有当我们可以修改输入的数组是可用
经典常用的算法,快速排序的精髓利用快速排序划分的思想,每一次划分就会有一个数字位于以数组从小到达排列的的最终位置index;位于index左边的数字都小于index对应的值,右边都大于index指向的值;所以,当index > k-1时,表示k个最小数字一定在index的左边,此时,只需要对index的左边进行划分即可;当index < k - 1时,说明index及index左边数字还没能满足k个数字,需要继续对k右边进行划分。
import java.util.ArrayList;
public class Test {
public static ArrayList least_num(int[] arr,int k) {
ArrayList list=new ArrayList();
if(arr==null||arr.length==0||k>arr.length||k<=0) {
return list;
}
int start=0;
int end=arr.length-1;
int index=patition(arr,start,end);
while(index!=k-1) {
if(index>k-1) {
end=index-1;
index=patition(arr,start,end);
}else {
start=index+1;
index=patition(arr,start,end);
}
}
for(int i=0;i=arr[start]) {
++start;
}
swap(arr,start,end);
}
//一次快排之后处在正确位置上的元素下标
return start;
}
//交换位置
public static void swap(int[] nums,int a,int b) {
int temp=nums[a];
nums[a]=nums[b];
nums[b]=temp;
}
public static void main(String[] args) {
int[] nums= {2,5,4,3,7,8,6,1};
System.out.print(least_num(nums,4));
}
}
输出:[1, 2, 3, 4]
思路:O(nlogk)的算法,特别适合处理海量数据
我们可以创建一个容量为k的数据容器来存储最小的k个数字,接下来我们每次从输入的n个整数中读入一个数。如果容器中已有的数字少于k个,则直接把这次读入的整数放入容器之中;如果容器中已有k个数字了(即容器满了),我们就不能再插入数字了,只能去替换容器中已有的数字。替换的规则是,我们拿待插入的数字和容器中k个数字中的最大值进行比较,如果大于容器中的最大值,则抛弃这个整数,否则用这个整数去替换这个数字。
故,容器满了之后,我们需要做3件事:一是在k个整数中找到最大数;二是有可能在这个容器中删除这个最大数;三是有可能会在这个容器中插入一个新数字。用二叉树实现这个容器,我们能在O(logk)时间内实现这三步操作。因此对于n个数字而言,总的时间效率就是O(nlogk)。
容器的实现用数据结构中的最大堆,因为其根结点的值永远是最大的结点值。我们用红黑树来实现我们的最大堆容器。而TreeSet类实现了红黑树的功能,它的底层是通过TreeMap实现的,TreeSet中的数据会按照插入数据自动升序排序。我们只需要将数据放入TreeSet中,其就会为我们实现排序。
import java.util.ArrayList;
import java.util.Iterator;
import java.util.TreeSet;
public class Test {
public static ArrayList least_num(int[] arr,int k){
ArrayList list=new ArrayList();
if(arr==null||arr.length==0||k<=0||k>arr.length)
return list;
TreeSet kSet=new TreeSet();
for(int i=0;i it=kSet.iterator();
while(it.hasNext()) {
list.add(it.next());
}
return list;
}
public static void main(String[] args) {
int[] arr= {4,2,3,5,1,6,8,7};
System.out.print(least_num(arr,5));
}
}
输出:[1, 2, 3, 4, 5]
30、求连续子数组的最大和
算法一:一般做法
public class Test {
public static int getMaxSumOfSubArray(int []arr) {
if(arr==null||arr.length<=1)
return 0;
int sum=arr[0];//初始化sum为数组第一个数
int max=arr[0];//初始化max为数组第一个数
//从数组第二个数开始遍历
for(int i=1;imax)
max=sum;
}
return max;
}
public static void main(String[] args) {
int[] array= {1,-2,3,10,-4,7,2,-5};
int max=getMaxSumOfSubArray(array);
System.out.println(max);
}
}
输出:18
算法二:动态规划
public class Test {
public static int getMax(int a,int b) {
return a>b? a:b;
}
public static int getMaxSumOfSubArray(int []arr) {
if(arr==null||arr.length<=0)
return 0;
int sum=arr[0];
int max=arr[0];
for(int i=1;imax) {
max=sum;
}
}
return max;
}
public static void main(String[] args) {
int[] array= {1,-2,3,10,-4,7,2,-5};
int max=getMaxSumOfSubArray(array);
System.out.println(max);
}
}
输出:18
31、从1到整数n中1出现的次数
不好的算法:
public class Test {
public static int numberOf1(int n) {
int number=0;
while(n>=1) {
if(n%10==1) {
number++;
}
n=n/10;
}
return number;
}
public static int numberOf1Between1AndN(int n) {
int number=0;
for(int i=1;i<=n;i++) {
number+=numberOf1(i);
}
return number;
}
public static void main(String[] args) {
int n=numberOf1Between1AndN(12);
System.out.println(n);
}
}
输出:5
很好的算法(公式法):
public class Test {
/*百位>=2的5位数字,其百位为1的情况有(a/10+1)*100个数字;
* 百位为1的5位数字,共有(a/10)*100+(b+1);
* 百位数为0的5位数字,共有(a/10)*100个数字满足要求.
我们可以进一步统一以下表达方式,即当百位>=2或=0时,有[(a+8)/10]*100,
当百位=1时,有[(a+8)/10]*100+(b+1)。
用代码表示就是: [(a+8)/10]*100+(a%10==1)?(b+1):0;
为什么要加8呢?因为只有大于2的时候才会产生进位等价于(a/10+1),
当等于0和1时就等价于(a/10)。另外,等于1时要单独加上(b+1),
这里我们用a对10取余是否等于1的方式判断该百位是否为1。*/
public static int numberOf1Between1AndN(int n) {
int ones = 0;
//在这里的作用是,从个位开始考虑,再到十位,百位,千位,一直到超出这个数!
for (long m = 1; m <= n; m *= 10)
//当m=100时,n/m其实代表的是a,而n%m代表的是b,此时考虑的是百位为1的情况;
//当m=1000,自然考虑的就是千位等于1的情况了
ones += (n/m + 8) / 10 * m + (n/m % 10 == 1 ? n%m + 1 : 0);
return ones;
}
/*
public static int numberOf1Between1AndN(int n) {
int ones=0;
for(int m=1;m<=n;m*=10) {
int a=n/m;
int b=n%m;
ones+=(a+8)/10*m;
if(a%10==1) {
ones+=b+1;
}
}
return ones;
}
*/
public static void main(String[] args) {
int n=numberOf1Between1AndN(12);
System.out.println(n);
}
}
输出:5
32、把数组中的数排成一个最小的数
思路:先将整型数组转换成String数组,然后将String数组排序,最后将排好序的字符串数组拼接出来。关键就是制定排序规则。
import java.util.Arrays;
import java.util.Comparator;
public class Test {
public static String PrintMinNumber(int[]arr) {
if(arr==null||arr.length==0){
return null;
}
int len=arr.length;
String[] str=new String[len];
StringBuffer sb=new StringBuffer();
for(int i=0;i() {
//重写compare方法
public int compare(String s1,String s2) {
String c1=s1+s2;
String c2=s2+s1;
//<0则升序排列,>0则降序排列
return c1.compareTo(c2);
}
});
for(int i=0;i 输出:1237465
33、求第N个丑数
算法一:逐个判断每个整数是不是丑数,直观但是效率非常低,不推荐
public class Test7 {
public static int getUglyNumber(int index) {
if(index<=0)
return 0;
int number=0;
int uglyFound=0;
while(uglyFound输出:12
算法二:用空间换时间,效率高,推荐
public class Test {
public static int getUglyNumber(int index) {
if(index<=0)
return 0;
int[] uglyArr=new int[index];//申请一个长度为index的专门存放丑数的数组
uglyArr[0]=1;//第一个丑数默认为1
/*存在某个丑数,排在它之前的每一个丑数乘以2得到的结果M2都小于已有的最大丑数,
* 排在它之后的每一个丑数乘以2得到的结果M2又会太大。我们需要记下这个丑数的位置T2,
* 同时每次生成新的丑数的时候,去更新这个丑数。3和5同理。
*/
int multiply2=0;//T2 位置初始化
int multiply3=0;//T3 位置初始化
int multiply5=0;//T5 位置初始化
for(int i=1;i输出:859963392
34、第一个出现一次的字符
思路:利用HashMap保存字符和出现次数。
import java.util.HashMap;
public class Test {
public static int getFirstNotRepeatingNumber(String str) {
if(str==null||str.length()==0)
return -1;
char[] c=str.toCharArray();
HashMap map=new HashMap();
for(char item:c) {
if(map.containsKey(item)) {
map.put(item, map.get(item)+1);
}else {
map.put(item, 1);
}
}
for(int i=0;i 输出:
第一个只出现一次的字符是:d
该字符的下标位置是:6
35、数组中逆序对的个数
例如在数组{7,5,6,4}中,一共存在5对逆序对,分别是{7,6},{7,5},{7,4},{6,4},{5,4}。
看到这个题目,我们的第一反应就是顺序扫描整个数组。每扫描到一个数组的时候,逐个比较该数字和它后面的数字的大小。如果后面的数字比它小,则这两个数字就组成一个逆序对。假设数组中含有n个数字。由于每个数字都要和O(n)个数字做比较,因此这个算法的时间复杂度为O(n^2)。我们尝试找找更快的算法。
我们以数组{7,5,6,4}为例来分析统计逆序对的过程,每次扫描到一个数字的时候,我们不能拿它和后面的每一个数字做比较,否则时间复杂度就是O(n^2)因此我们可以考虑先比较两个相邻的数字。
如下图所示,我们先把数组分解称两个长度为2的子数组,再把这两个子数组分别拆成两个长度为1的子数组。接下来一边合并相邻的子数组,一边统计逆序对的数目。在第一对长度为1的子数组{7},{5}中7大于5,因此{7,5}组成一个逆序对。同样在第二对长度为1的子数组{6},{4}中也有逆序对{6,4}。由于我们已经统计了这两队子数组内部逆序对,因此需要把这两对子数组排序,以免在以后的统计过程中再重复统计。
接下来我们统计两个长度为2的子数组之间的逆序对。
我们先用两个指针分别指向两个子数组的末尾,并每次比较两个指针指向的数字。如果第一个子数组中的数字大于第二个子数组中的数字,则构成逆序对,并且逆序对的数目等于第二个子数组中的剩余数字的个数。如果第一个数组中的数字小于或等于第二个数组中的数字,则不构成逆序对。每一次比较的时候,我们都把较大的数字从后往前复制到一个辅助数组中去,确保辅助数组中的数字是递增排序的。在把较大的数字复制到数组之后,把对应的指针向前移动一位,接着来进行下一轮的比较。
public class Test {
public static int count=0;//计数器
public static int mergeSort(int[] arr) {
if(arr==null||arr.length==0)
return 0;
mergesort(arr,0,arr.length-1);
return count;
}
public static void mergesort(int[] arr,int start,int end) {
if(startarr[j]) {
temp[k++]=arr[j++];
count+=mid-i+1;
}else {
temp[k++]=arr[i++];
}
}
while(i<=m) {
temp[k++]=arr[i++];
}
while(j<=n) {
temp[k++]=arr[j++];
}
for(int d:temp) {
arr[start++]=d;
}
}
public static void main(String[] args) {
int[] a= {7,5,8,3,4};
System.out.println(mergeSort(a));
}
}
输出:7
高效算法:
public class Test7 {
public static int InversePairs(int [] array) {
if(array==null||array.length<=1)
{
return 0;
}
int[] temp = new int[array.length];
return InversePairsCore(array,temp,0,array.length-1);//数值过大求余
}
private static int InversePairsCore(int[] array,int[] temp,int start,int end)
{
if(start==end)
{
return 0;
}
int mid = (start+end)>>1;
int leftCount = InversePairsCore(array,temp,start,mid)%1000000007;
int rightCount = InversePairsCore(array,temp,mid+1,end)%1000000007;
int count = 0;
int i=start;
int j=mid+1;
int k = start;
while(i<=mid&&j<=end)
{
if(array[i]>array[j])
{
count += mid-i+1;
temp[k++] = array[j++];
if(count>1000000007)//数值过大求余
{
count%=1000000007;
}
}
else
{
temp[k++] = array[i++];
}
}
for(;i<=mid;i++)
{
temp[k++]=array[i];
}
for(;j<=end;j++)
{
temp[k++]=array[j];
}
for(int s=start;s<=end;s++)
{
array[s] = temp[s];
}
return (leftCount+rightCount+count)%1000000007;
}
public static void main (String[] args) throws java.lang.Exception
{
int[] array={4,3,2,1};
System.out.println(InversePairs(array));
}
}
输出:6
36、两个链表的第一个公共节点
class ListNode{
int val;
ListNode next;
public ListNode(int data) {
this.val=data;
this.next=null;
}
}
public class Test {
public static ListNode getFirstCommonNode(ListNode head1,ListNode head2) {
int nLength1=GetLength(head1);//链表1 的长度
int nLength2=GetLength(head2);//链表2的长度
int nLengthDiff=0;//链表差
ListNode headLong;//长链表头节点
ListNode headShort;//短链表头节点
if(nLength1>nLength2) {
nLengthDiff=nLength1-nLength2;//链表长度差
headLong=head1;
headShort=head2;
}else {
nLengthDiff=nLength2-nLength1;
headLong=head2;
headShort=head1;
}
//长链表先走链表差的路程
for(int i=0;i输出:6
37、数字在排序数组中出现的次数
既然输入的数组是排好序的,那么我们很自然地想到利用二分查找算法。根据例子{1,2,3,3,3,3,3,4,5,6},我们先用二分查找算法找到一个3,由于3可能出现多次,因此我们找到的3左右两边可能都有3,于是我们再在找到的3左右两边顺序扫描,分别找出第一个3和最后一个3。因为要查找的数字在长度为n的数组中可能出现O(n)次,所以顺序扫描的时间复杂度为O(n)。因此这种算法的效率和直接从头到尾扫描整个数组统计3出现的次数是一样的。
前面的算法时间主要消耗在如何确定重复出现的数字的第一个K和最后一个K的位置上,有没有可能用二分查找算法直接找到第一个K和最后一个K呢?
我们先分析如何用二分查找算法在数组中找到第一个K。二分查找算法总是先拿数组中间的数字和K作比较,如果中间的数字比K大,那么K只可能出现在数组的前半段,下一轮我们只在数组前半段查找就行了。如果中间的数字比K小,那么K只有可能出现在数组的后半段,下一轮我们只需要在数组的后半段查找就行了。如果中间的数字和K相等,我们先判断中间的数字是不是第一个K。如果位于中间的数字的前面一个数字不是K,此时中间的数字刚好就是第一个K。如果中间的数字的前面一个数字也是K,也就是说第一个K肯定在数组的前半段,下一轮我们仍需要在数组的前半段查找。
找出最后一个K,同理。
class Test {
public static int getFirstK(int[] arr,int k,int start,int end){
if(start>end)
return-1;
int mid=(start+end)>>1;
int midData=arr[mid];
if(midData==k){
if(mid==0||arr[mid-1]!=k){
return mid;
}else{
end=mid-1;
}
}else if(midData>k){
end=mid-1;
}else{
start=mid+1;
}
return getFirstK(arr,k,start,end);
}
public static int getLastK(int[] arr,int k,int start,int end){
if(start>end)
return -1;
int mid=(start+end)>>1;
int midData=arr[mid];
if(midData==k){
if(mid==arr.length-1||arr[mid+1]!=k){
return mid;
}else{
start=mid+1;
}
}else if(midData>k){
end=mid-1;
}else{
start=mid+1;
}
return getLastK(arr,k,start,end);
}
public static int GetNumberOfK(int [] arr , int k) {
int number=0;
if(arr!=null||arr.length>0){
int first=getFirstK(arr,k,0,arr.length-1);
int last=getLastK(arr,k,0,arr.length-1);
if(first>=0&&last>=0){
number=last-first+1;
}
}
return number;
}
public static void main(String[] args) {
int[] arr= {1,2,3,3,3,3,3,4,5,6};
System.out.println(GetNumberOfK(arr,3));
}
}
输出:5
38、二叉树的深度
思路:若一棵树只有一个结点,它的深度是1。如果一个根节点只有左子树没有右子树,那么树的深度应该是左子树深度加1;同样,如果根节点只有右子树没有左子树,那么树的深度应该是其右子树深度加1。如果既有左子树也有右子树,那树的深度就是其左、右子树深度的较大值加1。
class TreeNode{
int val;
TreeNode left;
TreeNode right;
public TreeNode(int val) {
this.val=val;
this.left=null;
this.right=null;
}
}
public class Test {
public static int TreeDepth(TreeNode root) {
if(root==null)
return 0;
int leftDepth=TreeDepth(root.left);
int rightDepth=TreeDepth(root.right);
return Math.max(leftDepth,rightDepth)+1;
}
public static void main(String[] args) {
TreeNode root=new TreeNode(1);
root.left=new TreeNode(2);
root.left.right=new TreeNode(3);
System.out.println(TreeDepth(root));
}
}
输出:3
扩展38.1:输入一个二叉树的根节点,判断该树是不是平衡二叉树。
方法一:递归,需要重复遍历结点多次,不推荐
class TreeNode{
int val;
TreeNode left;
TreeNode right;
public TreeNode(int val) {
this.val=val;
this.left=null;
this.right=null;
}
}
public class Test {
//判断二叉树是否为平衡二叉树
public static boolean isBalance(TreeNode root) {
if(root==null)
return true;
int leftDepth=TreeDepth(root.left);
int rightDepth=TreeDepth(root.right);
int depthDiff=leftDepth-rightDepth;
if(depthDiff<-1||depthDiff>1)
return false;
return isBalance(root.left)&&isBalance(root.right);
}
//求二叉树深度
public static int TreeDepth(TreeNode root) {
if(root==null)
return 0;
int leftDepth=TreeDepth(root.left);
int rightDepth=TreeDepth(root.right);
return Math.max(leftDepth,rightDepth)+1;
}
public static void main(String[] args) {
TreeNode root=new TreeNode(1);
root.left=new TreeNode(2);
root.left.right=new TreeNode(3);
System.out.println(TreeDepth(root));
System.out.println(isBalance(root));
}
}
输出:
3
false
方法二:后序遍历,,每个结点只计算一次。推荐
class TreeNode{
int val;
TreeNode left;
TreeNode right;
public TreeNode(int val) {
this.val=val;
this.left=null;
this.right=null;
}
}
public class Test
{
public static boolean isBalance=true;
public static boolean IsBalanced(TreeNode root) {
TreeDepth(root);
return isBalance;
//isBalance 会在 TreeDepth1(root)中赋值。
}
public static int TreeDepth(TreeNode root)
{
if(root==null)
return 0;
int left=TreeDepth(root.left);//左子树高度
int right=TreeDepth(root.right);//右子树高度
if(Math.abs(left-right)>1)
{
isBalance=false; //只要有一个子树的左右子树的高度绝对值大于 1 isBalance=false
}
return Math.max(left, right)+1;
}
public static void main(String[] args) {
TreeNode root=new TreeNode(1);
root.left=new TreeNode(2);
root.left.right=new TreeNode(3);
System.out.println(IsBalanced(root));
}
}
输出:false
39、数组中只出现一次的两个数,而其他数都出现两次。
public class Test {
static int num1=0;
static int num2=0;
public static void findNumsAppearOnce(int[] nums) {
if(nums==null||nums.length<2)
return ;
int number=nums[0];//异或结果初始化
for(int i=1;i>index)&1)==0;
if(isBit1) {
num1^=nums[i];//数组1异或的结果为第一个只出现一次的数
}else {
num2^=nums[i];//数组2异或的结果为第二个只出现一次的数
}
}
}
//找出异或结果中(从低位向高位找)第一个出现“1”的位置下标
public static int firstIndexOf1(int num) {
int index=0;
while((num&1)==0) {
num=num>>1;//右移一位
index++;
}
return index;
}
public static void main(String[] args) {
int[] arr= {2,4,3,6,3,2,5,5};
findNumsAppearOnce(arr);
System.out.println(Test.num1+" "+Test.num2);
}
}
输出:4 6
40、输入一个递增排序的数组和一个数字S,在数组中查找两个数,使得他们的和正好是S,如果有多对数字的和等于S,输出两个数的乘积最小的。
差的思路:先在数组中固定一个数字,再依次判断数组中其余的n-1个数字与它的和是不是等于sum。
好的思路:因为数组是排好序的,首先定义两个指针,第一个指针指向数组的第一个数字(最小的数字),第二个指针指向数组的最后一个数字(最大的数字)。若这两个数字的和大于sum,则把第二个指针向前移动一个数字;如果这两个数字的和小于sum,则将第一个指针向后移动一个数字。直到找到两个数字的和等于sum。时间复杂度:O(N)
public class Test {
public static void getNumberWithSum(int[] arr,int sum) {
if(arr==null||arr.length==0)
return ;
int start=0;
int end=arr.length-1;
while(start输出:4 11
扩展40.1 输出所有和为S的连续正数序列。序列内按照从小至大的顺序,序列间按照开始数字从小到大的顺序
思路:考虑用两个数small和big分别表示序列的最小值和最大值。首先把small初始化为1,big初始化为2。如果从small到big的序列和大于s,我们可以从序列中去掉最小值,也就是增大small的值。如果从small到big的序列和小于s,我们可以增大big,让这个序列包含更多的数字。因为这个序列至少要有两个数字,我们一直增加small到小于(1+s)/2为止。
public class Test {
public static void findContinuousSeq(int sum) {
if(sum<3)
return ;
int small=1;
int big=2;
int middle=(1+sum)/2;
int curSum=small+big;
while(smallsum) {
curSum-=small;
small++;
if(curSum==sum) {
printSeq(small,big);
}
}
big++;
curSum+=big;
}
}
public static void printSeq(int small,int big) {
for(int i=small;i<=big;i++) {
System.out.print(i+" ");
}
System.out.println();
}
public static void main(String[] args) {
findContinuousSeq(9);
}
}
输出:
2 3 4
4 5
41、翻转字符串
思路:
第一步:翻转句子中所有的字符,此时,不但翻转了句子中单词的顺序,连单词内的字符顺序也被翻转了
第二步:再翻转每个单词中的字符顺序,就得到我们想要的结果。
import java.util.ArrayList;
public class Test {
public String ReverseSentence(String str) {
if(str==null||str.length()==0||str.trim().equals(""))
return str;
StringBuffer sb=new StringBuffer();
String re=reverse(str);//反转后的str
String[] s=re.split(" ");
for(int i=0;i=0;i--){
sb.append(s.charAt(i));
}
return sb.toString();
}
public static void main (String[] args)
{
Test test=new Test();
System.out.println(test.ReverseSentence("I am s student."));
}
}
输出:student. a am I
扩展41.1、左旋转字符串:对于一个给定的字符序列S,请你把其循环左移K位后的序列输出
思路:先把字符串分为两个部分,分别反转这两个部分,最后再翻转整个字符串,就得到我们想要的答案。
public class Test {
public static String leftRotateString(String str,int n) {
if(str==null||str.length()==0||str.trim().length()==0)
return str;
String s1=reverse(str.substring(0, n));
String s2=reverse(str.substring(n, str.length()));
return reverse(s1+s2);
}
//反转字符串函数
public static String reverse(String str) {
StringBuilder sb=new StringBuilder();
for(int i=str.length()-1;i>=0;i--) {
sb.append(str.charAt(i));
}
return String.valueOf(sb);
}
public static void main(String[] args) {
System.out.println(leftRotateString("abcdefg",2));
}
}
输出:cdefgab
42、n个骰子的点数及出现的概率
算法一:递归,效率低
public class Test {
private static final int g_maxValue = 6;
//基于递归求骰子点数,时间效率不高
public static void PrintProbability(int number){
if(number<1) return;
int maxSum = number*g_maxValue;
//我们定义一个长度为6n-n+1的数组,和为s的点数出现的次数保存到数组第s-n个元素里。
//为什么是6n-n+1呢?因为n个骰子的和最少是n,最大是6n,介于这两者之间的每一个情况都可能会发生,总共6n-n+1种情况
int[] pProbabilities = new int[maxSum-number+1];
//初始化,开始统计之前都为0次
for(int i=0;i<=pProbabilities.length-1;i++){
pProbabilities[i] = 0;
}
double total = Math.pow(g_maxValue,number);
//probability(number,pProbabilities);这个函数计算n~6n每种情况出现的次数
probability(number,pProbabilities);
for(int i=number;i<=maxSum;i++){
double ratio = pProbabilities[i-number]/total;
System.out.println("i: "+i+" ratio: "+ratio);
}
}
public static void probability(int number,int[] pProbabilities){
for(int i=1;i<=g_maxValue;i++){//从第一个骰子开始
probability(number,number,i,pProbabilities);
}
}
//总共original个骰子,当前第 current个骰子,当前的和,贯穿始终的数组
public static void probability(int original,int current,int sum,int[] pProbabilities){
if(current==1){
pProbabilities[sum-original]++;
}else{
for(int i=1;i<=g_maxValue;i++){
probability(original,current-1,sum+i,pProbabilities);
}
}
}
public static void main(String[] args) {
PrintProbability(1);
}
}
输出:
sum: 1 ratio: 0.16666666666666666
sum: 2 ratio: 0.16666666666666666
sum: 3 ratio: 0.16666666666666666
sum: 4 ratio: 0.16666666666666666
sum: 5 ratio: 0.16666666666666666
sum: 6 ratio: 0.16666666666666666
算法二:循环,效率高
public class Test {
private static final int g_maxValue = 6;
//基于循环求骰子点数
public static void PrintProbability(int number){
if(number<1){
return;
}
int[][] pProbabilities = new int[2][g_maxValue*number +1];
for(int i=0;i输出:
sum: 1 ratio: 0.16666666666666666
sum: 2 ratio: 0.16666666666666666
sum: 3 ratio: 0.16666666666666666
sum: 4 ratio: 0.16666666666666666
sum: 5 ratio: 0.16666666666666666
sum: 6 ratio: 0.16666666666666666
43、扑克牌的顺子
思路:需要做三件事:首先把数组排序,再统计数组中0的个数,最后统计排序后的数组中相邻数字之间的空缺总数。如果空缺总数小于等于0的个数,那么这个数组就是连续的,反之不连续。
import java.util.Arrays;
public class Test {
public static boolean isContinuous(int[] nums) {
if(nums==null||nums.length==0)
return false;
int count=0;
int diff=0;
Arrays.sort(nums);//1.数组排序
for(int i=0;i=diff)
return true;
return false;
}
public static void main(String[] args) {
int[] nums= {0,1,3,4,5};
System.out.println(isContinuous(nums));
}
}
输出:true
44、圆圈中最后剩下的数字(约瑟夫环)
问题描述:例如,0、1、2、3、4这5个数字组成一个圆圈,从数字0开始每次删除第3个数字,则删除的前四个数字依次是:2、0、4、1,因此最后剩下的数字是3.
算法一:循环链表模拟圆圈
import java.util.LinkedList;
public class Test {
public static int lastRemaining(int n,int m) {
if(n<1||m<1)
return -1;
LinkedList list=new LinkedList();
int nextRemove=0;
for(int i=0;i1) {
nextRemove=(nextRemove+m-1)%list.size();
list.remove(nextRemove);
}
return list.size()==1?list.get(0):-1;
}
public static void main(String[] args) {
System.out.println(lastRemaining(5,3));
}
}
输出:3
算法二:分析每次被删除的数字的规律并直接算出圆圈中最后一个数字
经过复杂的分析,终于找到了一个递归公式。要得到n个数字的序列中最后剩下的数字,只需要得到n-1个数字的序列中最后剩下的数字,并以此类推。当n=1时,也就是序列中开始只有一个数字0,那么很显然最后剩下的数字也是0。我们把这种关系表示为:
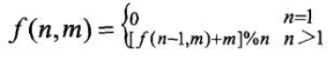
public class Test {
public static int lastRemaining(int n,int m) {
if(n<1||m<1)
return -1;
int last=0;//n=1时,第一个和最后一个数都是0
for(int i=2;i<=n;i++) {//n>=2
last=(last+m)%i;
}
return last;
}
public static void main(String[] args) {
System.out.println(lastRemaining(5,3));
}
}
输出:3
45、1+2+3+…+n的和
方法1:公式法n(n+1)/2
public class Test {
public static int getSum(int n) {
int sum=(int)(Math.pow(n, 2)+n);
return sum>>1;
}
public static void main(String[] args) {
System.out.println(getSum(100));
}
}
输出:5050
方法2:
思路:
利用递归的思路,运用短路求值原理作为递归结束的条件。
短路求值:
作为"&&“和”||"操作符的操作数表达式,这些表达式在进行求值时,只要最终的结果已经可以确定是真或假,求值过程便告终止,这称之为短路求值(short-circuit evaluation)。
如:
假如expr1和expr2都是表达式,并且expr1的值为0,在下面这个逻辑表达式的求值过程中:
expr1 && expr2
expr2将不会进行求值,因为整个逻辑表达式的值已经可以确定为0。
类似地,如果expr1的值不是0,那么在下面的这个逻辑表达式的求值过程中:
expr1 || expr2
expr2将不会进行求值,因为整个逻辑表达式的值已经确定为1。
public class Test {
public static int sum_solution(int n) {
int sum=n;
//boolean result=(n==0)||(sum+=sum_solution(n-1))>0;//这里用逻辑或也可以达到相同的判断作用
boolean result=(n>0)&&(sum+=sum_solution(n-1))>0;
return sum;
}
public static void main(String[] args) {
System.out.println(sum_solution(10));
}
}
输出:55
46、不用加减乘除做加法
public class Test {
public static int Add(int num1,int num2) {
int sum;
int carry;
while(num2!=0) {//当还有进位的时候
sum=num1^num2;// 各位相加的值(0加0、1加1的结果都是0,0加1,1加0的结果都是1,这和异或结果一样)
carry=(num1&num2)<<1;//进位值(只有1加1的时候才产生进位,此时可以想象成两个数先做位于运算,然后再左移一位)
num1=sum;
num2=carry;
}
return num1;
}
public static void main(String[] args) {
System.out.println(Add(2,3));
}
}
输出:5
47、不能被继承的类
常规解法:要想一个类不被继承,我们只要把它的构造函数定义为私有函数。那么当一个类试图从它那里继承的时候,必然会由于调用构造函数而导致编译错误。可是这个类的构造函数是私有函数,我们怎样才能得到该类型的实例呢?我们可以通过定义一个公有的静态函数来创建类的实例。
缺点:这个类不能被继承,但总觉得它和普通的类型有些不一样,使用起来有点不方便。比如我们只能得到位于堆上的实例,而得不到位于栈上的实例。
public class Test {
//定义公有的静态函数来创造类的实例
public static Test getInstance() {
return new Test();
}
//构造函数私有
private Test() {
System.out.println("当前类的构造函数");
}
public static void main(String[] args) {
Test test=new Test();
}
}
输出:当前类的构造函数
新奇的解法:利用虚拟继承(这是C++中的说法,在此不做赘述)
48、字符串转换为整数
public class Test {
public static long StrToInt(String str) {
if(str==null||str.length()<=0)
return 0;
long result=0;
boolean isValid=true;//判断合法输入的全局变量
int symbol=1;//符号标志位,默认为1,负数为-1
char[] arr=str.toCharArray();
if(arr[0]=='-') {
symbol=-1;
}
for(int i=(arr[0]=='+'||arr[0]=='-')?1:0;i='0'&&arr[i]<='9')) {//对输入内容进行校验输入值不在0-9范围,则为非法输入
isValid=false;
return 0;
}
result=result*10+arr[i]-'0';
//判断运算结果是否溢出
if((symbol==1&&result>Integer.MAX_VALUE)||(symbol==-1&&result 输出:
123
-123
123
0
49、树中两个节点的最低公共祖先
(1)树是二叉搜索树
思路:从树的根节点开始遍历,如果根节点的值大于其中一个节点,小于另外一个节点,则根节点就是最低公共祖先。否则如果根节点的值小于两个节点的值,则递归求根节点的右子树,如果大于两个节点的值则递归求根的左子树。如果根节点正好是其中的一个节点,那么说明这两个节点在一条路径上,所以最低公共祖先则是根节点的父节点,时间复杂度是O(logn),空间复杂度是O(1)。
class BinaryTreeNode{
int value;
BinaryTreeNode leftNode;;
BinaryTreeNode rightNode;
BinaryTreeNode(int val){
value=val;
leftNode=null;
rightNode=null;
}
}
public class Test {
public static BinaryTreeNode getLowestCommonAncestor(BinaryTreeNode rootParent,BinaryTreeNode root, BinaryTreeNode node1,BinaryTreeNode node2){
if(root == null || node1 == null || node2 == null){
return null;
}
//如果根节点的值大于其中一个节点,小于其中另一个节点,即差乘<0,则根节点就是我们要找的最低公共祖先
if((root.value - node1.value)*(root.value - node2.value) < 0){
return root;
}else if((root.value - node1.value)*(root.value - node2.value) > 0){
//差乘>0表示根节点的值同时大于或者同时小于两个节点的值,根据具体情况决定遍历根节点的左子树还是右子树
BinaryTreeNode newRoot = ((root.value > node1.value) && (root.value > node2.value)) ? root.leftNode : root.rightNode;
return getLowestCommonAncestor(root,newRoot, node1, node2);//递归遍历根节点的子树
}else{
//两个节点中的一个节点是另外一个节点的父节点的特殊情况
//说明这两个节点在一条路径上,所以最低公共祖先则是根节点的父节点
return rootParent;
}
}
public static void main(String[] args) {
BinaryTreeNode root=new BinaryTreeNode(6);
BinaryTreeNode rl=new BinaryTreeNode(3);
BinaryTreeNode rr=new BinaryTreeNode(8);
BinaryTreeNode rll=new BinaryTreeNode(1);
BinaryTreeNode rlr=new BinaryTreeNode(5);
root.leftNode=rl;
root.rightNode=rr;
root.leftNode.leftNode=rll;
root.leftNode.rightNode=rlr;
BinaryTreeNode node=getLowestCommonAncestor(root,root,rl,rll);
System.out.println(node.value);
}
}
输出:6
(2)若树是普通树,但有指向父节点的指针
思路:两个节点如果在两条路径上,类似于求两个链表的第一个公共节点。由于每个节点的深度最多为logn,所以时间复杂度为O(logn),空间复杂度O(1)。
class TreeNode{
int value;
TreeNode leftNode;;
TreeNode rightNode;
TreeNode parentNode;
TreeNode(int val){
value=val;
leftNode=null;
rightNode=null;
parentNode=null;
}
}
public class Test {
public static TreeNode getLowestCommonAncestor(TreeNode root,TreeNode node1,TreeNode node2) {
if(root==null||node1==null||node2==null)
return null;
int depth1=DepthOfNode(root,node1,node2);//计算节点1的深度
int depth2=DepthOfNode(root,node2,node1);//计算节点2的深度
if(depth1==-1)//若节点1是节点2的子节点,则返回节点2的父节点
return node2.parentNode;
if(depth2==-1)//若节点2是节点1的子节点,则返回节点1的父节点
return node1.parentNode;
TreeNode p=depth1-depth2>0?node1:node2;//p指向深的节点
TreeNode q=depth1-depth2>0?node2:node1;//q指向浅的节点
int depthDiff=Math.abs(depth1-depth2);//深度差
while(depthDiff>0) {
p=p.parentNode;//深度大的节点向父节点移动,缩短和深度小的节点之间的深度差
depthDiff--;
}
while(p!=q) {//两个节点之间不存在深度差的时候,即靠近链表第一个公共节点的时候
p=p.parentNode;
q=q.parentNode;
}
return p;
}
//计算节点n1的深度
public static int DepthOfNode(TreeNode root,TreeNode n1,TreeNode n2) {
int depth=0;
while(n1.parentNode!=null) {
n1=n1.parentNode;
depth++;
if(n1==n2)
return -1;
}
return depth;
}
public static void main(String[] args) {
TreeNode root=new TreeNode(6);
TreeNode rl=new TreeNode(3);
TreeNode rr=new TreeNode(8);
TreeNode rll=new TreeNode(1);
TreeNode rlr=new TreeNode(5);
root.leftNode=rl;
root.rightNode=rr;
root.leftNode.leftNode=rll;
root.leftNode.rightNode=rlr;
rll.parentNode=rl;
rlr.parentNode=rl;
rl.parentNode=root;
rr.parentNode=root;
TreeNode node=getLowestCommonAncestor(root,rll,rlr);
System.out.println(node.value);
}
}
输出:3
(3)若树是普通树,并没有指向父节点的指针
思路:用栈来实现类似于指向父节点指针的功能,获取node节点的路径时间复杂度为O(n),所以总的时间复杂度是O(n),空间复杂度是O(logn)
import java.util.Stack;
class TreeNode{
int value;
TreeNode leftNode;;
TreeNode rightNode;
TreeNode(int val){
value=val;
leftNode=null;
rightNode=null;
}
}
public class Test {
public static TreeNode getLowestCommonAncestor(TreeNode root,TreeNode node1,TreeNode node2) {
if(root==null||node1==null||node2==null)
return null;
Stack path1=new Stack();
boolean flag1=getThePathOfTheNode(root,node1,path1);
if(!flag1)//树上没有node1节点
return null;
Stack path2=new Stack();
boolean flag2=getThePathOfTheNode(root,node2,path2);
if(!flag2)//树上没有node2节点
return null;
//让两个路径等长
if(path1.size()>path2.size()) {
while(path1.size()!=path2.size()) {
path1.pop();
}
}else {
while(path1.size()!=path2.size()) {
path2.pop();
}
}
if(path1==path2) {//若两个节点在一个路径上
path1.pop();
return path1.pop();
}else {
TreeNode p=path1.pop();
TreeNode q=path2.pop();
while(p!=q) {
p=path1.pop();
q=path2.pop();
}
return p;
}
}
//获得根节点到node节点的路径path
public static boolean getThePathOfTheNode(TreeNode root,TreeNode node,Stack path) {
if(root==null||node==null)
return false;
path.push(root);
if(root==node)
return true;
boolean found=false;
if(root.leftNode!=null) {
found=getThePathOfTheNode(root.leftNode,node,path);
}
if(!found&&root.rightNode!=null) {
found=getThePathOfTheNode(root.rightNode,node,path);
}
if(!found)
path.pop();
return found;
}
public static void main(String[] args) {
TreeNode root=new TreeNode(6);
TreeNode rl=new TreeNode(3);
TreeNode rr=new TreeNode(8);
TreeNode rll=new TreeNode(1);
TreeNode rlr=new TreeNode(5);
root.leftNode=rl;
root.rightNode=rr;
root.leftNode.leftNode=rll;
root.leftNode.rightNode=rlr;
TreeNode node=getLowestCommonAncestor(root,rll,rlr);
System.out.println(node.value);
}
}
输出:3
50、找出重复的数
解题思路
1、排序
将数组排序,然后扫描排序后的数组即可。
时间复杂度:O(nlogn),空间复杂度:O(1)
2、哈希表
从头到尾扫描数组,每扫描到一个数字,判断该数字是否在哈希表中,如果该哈希表还没有这个数字,那么加入哈希表,如果已经存在,则返回该数字;
时间复杂度:O(n),空间复杂度:O(n)
3、交换
0~n-1正常的排序应该是A[i]=i;因此可以通过交换的方式,将它们都各自放回属于自己的位置;
从头到尾扫描数组A,当扫描到下标为i的数字m时,首先比较这个数字m是不是等于i,
如果是,则继续扫描下一个数字;
如果不是,则判断它和A[m]是否相等,如果是,则找到了第一个重复的数字(在下标为i和m的位置都出现了m);如果不是,则把A[i]和A[m]交换,即把m放回属于它的位置;
重复上述过程,直至找到一个重复的数字;
时间复杂度:O(n),空间复杂度:O(1)
(将每个数字放到属于自己的位置最多交换两次)
public class Test {
public static int getDuplication(int[] num) {
if(num==null||num.length<=0) {
System.out.println("输入的数组格式有误!");
return -1;
}
for(int n:num) {
if(n<0||n>num.length-1) {
System.out.println("输入的数组元素超过范围!");
return -1;
}
}
for(int i=0;i输出:
2
输入的数组元素超过范围!
-1
51、构建乘积数组
public class Test {
public static double[] multiply(double[] data) {
if(data==null||data.length<2)
return null;
double[] result=new double[data.length];
// result[0]取1
result[0]=1;
for(int i=1;i=0;i--) {
temp*=data[i+1];
result[i]*=temp;
}
return result;
}
public static void main(String[] args) {
double[] data= {1,2,3,4};
double[] result=multiply(data);
for(double d:result) {
System.out.print(d+" ");
}
}
}
输出:24.0 12.0 8.0 6.0
52、正则表达式匹配
在每轮匹配中,Patttern第二个字符是(星号)时:
第一个字符不匹配(’.‘与任意字符视作匹配),那么’星号’只能代表匹配0次,比如’ba’与’a星号ba’,字符串不变,模式向后移动两个字符,然后匹配剩余字符串和模式
第一个字符匹配,那么’星号’可能代表匹配0次,1次,多次,比如’aaa’与’a星号aaa’、‘aba’与’a星号ba’、‘aaaba’与’a星号ba’。匹配0次时,字符串不变,模式向后移动两个字符,然后匹配剩余字符串和模式;匹配1次时,字符串往后移动一个字符,模式向后移动2个字符;匹配多次时,字符串往后移动一个字符,模式不变;
而当Patttern第二个字符不是’星号’时,情况就简单多了:
如果字符串的第一个字符和模式中的第一个字符匹配,那么在字符串和模式上都向后移动一个字符,然后匹配剩余字符串和模式。
如果字符串的第一个字符和模式中的第一个字符不匹配,那么直接返回false。
public class Test7 {
public static boolean match(char[] str, char[] pattern){
if (str == null || pattern == null) {
return false;
}
return matchCore(str, 0, pattern, 0);
}
public static boolean matchCore(char[] str, int strIndex, char[] pattern, int patternIndex) {
//str到尾,pattern到尾,匹配成功
if (strIndex == str.length && patternIndex == pattern.length) {
return true;
}
//str未到尾,pattern到尾,匹配失败
if (strIndex != str.length && patternIndex == pattern.length) {
return false;
}
//str到尾,pattern未到尾(不一定匹配失败,因为a*可以匹配0个字符)
if (strIndex == str.length && patternIndex != pattern.length) {
//只有pattern剩下的部分类似a*b*c*的形式,才匹配成功
if (patternIndex + 1 < pattern.length && pattern[patternIndex + 1] == '*') {
return matchCore(str, strIndex, pattern, patternIndex + 2);
}
return false;
}
//str未到尾,pattern未到尾
if (patternIndex + 1 < pattern.length && pattern[patternIndex + 1] == '*') {
//首字母匹配
if (pattern[patternIndex] == str[strIndex] || (pattern[patternIndex] == '.' && strIndex != str.length)) {
return matchCore(str, strIndex, pattern, patternIndex + 2)//*匹配0个,跳过
|| matchCore(str, strIndex + 1, pattern, patternIndex + 2)//*匹配1个,跳过
|| matchCore(str, strIndex + 1, pattern, patternIndex);//*匹配1个,再匹配str中的下一个
} else {
//直接跳过*(*匹配到0个)
return matchCore(str, strIndex, pattern, patternIndex + 2);
}
}
if (pattern[patternIndex] == str[strIndex] || (pattern[patternIndex] == '.' && strIndex != str.length)) {
return matchCore(str, strIndex + 1, pattern, patternIndex + 1);
}
return false;
}
public static void main(String[] args) {
char[] c1= {'a','s','w'};
char[] c2= {'b','*','a','s','w'};
System.out.println(match(c1,c2));
}
}
输出:
true
53、表示数值的字符串
1、对字符串中的每个字符进行判断分析
2、e(E)后只能接数字或者+、-,并且不能出现2次,不能出现在最后一位
3、对于+、-号,只能出现在第一个字符或者是e的后一位
4、对于小数点,不能出现2次,e后面不能出现小数点
public class Test {
public static boolean isNumeric(char[] str) {
if(str==null || str.length==0)
return false;
boolean hasE = false;
boolean decimal = false;
boolean sign = false;
for(int i =0;i0 && str[i-1]!='e' && str[i-1]!='E')
return false;
sign = true;
}
else if(ch=='.'){//对于.来说,如果在它之前出现了e(E)或者.,则false
if(hasE || decimal)
return false;
decimal = true;
}
else if(ch<'0' || ch>'9')//出现了其他符号的情况,则false
return false;
}
return true;
}
public static void main(String[] args) {
char[] arr= {'-','e','-','3'};
System.out.println(isNumeric(arr));
}
}
输出:true
54、字符流中第一个不重复的字符
public class Test {
//中心思想是:源源不断的有字母放到字符串中,建立一个256个大小的int型数组来代表哈希表
static int[] chars=new int[256]; //建立哈希数组
static StringBuffer sb=new StringBuffer();
public static void insert(char ch) {
sb.append(ch);
chars[ch]++; //输入的字母作为数组下标,如果字母出现就将哈希表中该下标的值加一。
}
public static char firstAppearingOnce() {
char[] str=sb.toString().toCharArray();
for(char c:str) {//要找第一个只出现一次的字符,就遍历字符串,字符串中的字符作为数组下标
if(chars[c]==1) {//哈希数组值为1对应的字符就是要找的字符
return c;
}
}
return '#';
}
public static void main(String[] args) {
insert('g');
insert('o');
insert('o');
insert('g');
insert('l');
insert('e');
System.out.println(firstAppearingOnce());
}
}
输出:l
55、链表中环的入口节点
1、哈希表
遍历整个链表,并将链表结点存入哈希表中(这里我们使用容器set),如果遍历到某个链表结点已经在set中,那么该点即为环的入口结点;
2、两个指针
如果链表存在环,那么计算出环的长度n,然后准备两个指针pSlow,pFast,pFast先走n步,然后pSlow和pFase一块走,当两者相遇时,即为环的入口处;
3、改进
如果链表存在环,我们无需计算环的长度n,只需在相遇时,让一个指针在相遇点出发,另一个指针在链表首部出发,然后两个指针一次走一步,当它们相遇时,就是环的入口处。
//改进版
class ListNode{
int val;
ListNode next;
ListNode(int v){
val=v;
this.next=null;
}
}
public class Test {
public static ListNode enrtyNodeOfLoop(ListNode head) {
if(head==null||head.next==null)
return null;
ListNode fast=head;
ListNode slow=head;
//判断链表是否有环
while(fast!=null&&fast.next!=null) {
slow=slow.next;//慢指针走一步
fast=fast.next.next;//快指针走两步
if(slow==fast)
break;
}
if(fast!=null) {
slow=head;
while(slow!=fast) {
slow=slow.next;
fast=fast.next;
}
}
return fast;
}
public static void main(String[] args) {
ListNode head=new ListNode(1);
ListNode l2=new ListNode(2);
ListNode l3=new ListNode(3);
ListNode l4=new ListNode(4);
ListNode l5=new ListNode(5);
ListNode l6=new ListNode(6);
ListNode l7=new ListNode(7);
head.next=l2;
l2.next=l3;
l3.next=l4;
l4.next=l5;
l5.next=l6;
l6.next=l7;
l7.next=l4;
System.out.println(enrtyNodeOfLoop(head).val);
}
}
输出:4
56、删除链表中重复的节点
题目描述:
在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留,返回链表头指针。 例如,链表1->2->3->3->4->4->5 处理后为 1->2->5
class ListNode{
int val;
ListNode next;
ListNode(int v){
val=v;
this.next=null;
}
}
public class Test {
public static ListNode delDuplication(ListNode head) {
if(head==null)
return null;
ListNode first=new ListNode(-1);//新建一个节点,防止头结点被删除
first.next=head;
ListNode p=head;
ListNode preNode=first;// 指向前一个节点
while(p!=null&&p.next!=null) {
if(p.val==p.next.val) {
int val=p.val;//存下p.val方便后面的比较
while(p!=null&&p.val==val) {// 向后重复查找
p=p.next;
}
preNode.next=p;//上个非重复值指向下一个非重复值:即删除重复值
}else { //如果当前节点和下一个节点值不等,则向后移动一位
preNode=p;
p=p.next;
}
}
return first.next;
}
public static void main(String[] args) {
ListNode head=new ListNode(0);
ListNode l1=new ListNode(1);
ListNode l2=new ListNode(2);
ListNode l3=new ListNode(3);
ListNode l4=new ListNode(3);
ListNode l5=new ListNode(4);
ListNode l6=new ListNode(4);
ListNode l7=new ListNode(5);
head.next=l1;
l1.next=l2;
l2.next=l3;
l3.next=l4;
l4.next=l5;
l5.next=l6;
l6.next=l7;
ListNode node=delDuplication(head);
while(node.next!=null) {
node=node.next;
System.out.print(node.val+" ");
}
}
}
输出:1 2 5
57、二叉树的下一个节点
给定一个二叉树和其中的一个结点,请找出中序遍历顺序的下一个结点并且返回。注意,树中的结点不仅包含左右子结点,同时包含指向父结点的指针。
思路:若节点右孩子存在,则设置一个指针从该节点的右孩子出发,一直沿着指向左子结点的指针找到的叶子节点即为下一个节点;若节点不是根节点。如果该节点是其父节点的左孩子,则返回父节点;否则继续向上遍历其父节点的父节点,重复之前的判断,返回结果。
class TreeNode{
int val;
TreeNode parent;
TreeNode left;
TreeNode right;
TreeNode(int v){
val=v;
this.left=null;
this.right=null;
this.parent=null;
}
}
public class Test {
public static TreeNode getNext(TreeNode node) {
if(node==null)
return null;
if(node.right!=null) {//如果该节点有右孩子
node=node.right;
while(node.left!=null) {//如果该节点的右孩子有左孩子
node=node.left;//遍历左孩子直到叶子节点
}
return node;//叶子节点即为该节点中序遍历的下一个节点
}
while(node.parent!=null) {//如果该节点有父节点
if(node.parent.left==node) {//且该节点是其父节点的左孩子
return node.parent;//则返回该节点的父节点
}
node=node.parent;//如果是其他情况,则遍历该节点的父节点
}
return null;
}
public static void main(String[] args) {
TreeNode t1=new TreeNode(8);
TreeNode t2=new TreeNode(5);
TreeNode t3=new TreeNode(10);
TreeNode t4=new TreeNode(3);
TreeNode t5=new TreeNode(6);
t1.left=t2;
t1.right=t3;
t2.left=t4;
t2.right=t5;
t2.parent=t3.parent=t1;
t4.parent=t5.parent=t2;
System.out.println(getNext(t5).val);
}
}
输出:8
58、对称的二叉树
思路:利用递归进行判断,若左子树的左孩子等于右子树的右孩子且左子树的右孩子等于右子树的左孩子,并且左右子树节点的值相等,则是对称的。
class TreeNode{
int val;
TreeNode left;
TreeNode right;
TreeNode(int v){
val=v;
this.left=null;
this.right=null;
}
}
public class Test {
public static boolean isSymmetrical(TreeNode root) {
if(root==null)
return true;
return isEquals(root.left,root.right);
}
public static boolean isEquals(TreeNode leftNode,TreeNode rightNode) {
if(leftNode==null&&rightNode==null)
return true;
while(leftNode!=null&&rightNode!=null) {
return leftNode.val==rightNode.val&&isEquals(leftNode.left,rightNode.right)&&isEquals(leftNode.right,rightNode.left);
}
return false;
}
public static void main(String[] args) {
TreeNode root=new TreeNode(1);
TreeNode rl=new TreeNode(2);
TreeNode rr=new TreeNode(2);
TreeNode rll=new TreeNode(3);
TreeNode rlr=new TreeNode(5);
TreeNode rrl=new TreeNode(5);
TreeNode rrr=new TreeNode(3);
root.left=rl;
root.right=rr;
root.left.left=rll;
root.left.right=rlr;
root.right.left=rrl;
root.right.right=rrr;
System.out.println(isSymmetrical(root));
}
}
输出:true
59、按之字形顺序打印二叉树
思路:利用两个辅助栈,一个栈存储奇数层的数据,一个栈存储偶数层的数据。(利用栈先进后出的规律,刚好之字形)
import java.util.ArrayList;
import java.util.Stack;
class TreeNode{
int val;
TreeNode left;
TreeNode right;
TreeNode(int v){
val=v;
this.left=null;
this.right=null;
}
}
public class Test {
public static ArrayList> printTreeAsZ(TreeNode root) {
ArrayList> list=new ArrayList>();
if(root==null)
return list;
Stack stack=new Stack();
Stack stack2=new Stack();
stack.add(root);
int layer=1;//初始化层数为1
while(!stack.isEmpty()||!stack2.isEmpty()) {
ArrayList temp=new ArrayList();
while(!stack.isEmpty()&&(layer%2==1)) {
TreeNode node=stack.pop();
if(node!=null) {
temp.add(node.val);
stack2.push(node.left);
stack2.push(node.right);
}
}
while(!stack2.isEmpty()&&(layer%2==0)) {
TreeNode node=stack2.pop();
if(node!=null) {
temp.add(node.val);
stack.push(node.right);
stack.push(node.left);
}
}
if(temp.size()!=0) {
list.add(temp);
}
layer++;
}
return list;
}
public static void main(String[] args) {
TreeNode root=new TreeNode(1);
TreeNode rl=new TreeNode(2);
TreeNode rr=new TreeNode(3);
TreeNode rll=new TreeNode(4);
TreeNode rlr=new TreeNode(5);
TreeNode rrl=new TreeNode(6);
TreeNode rrr=new TreeNode(7);
root.left=rl;
root.right=rr;
root.left.left=rll;
root.left.right=rlr;
root.right.left=rrl;
root.right.right=rrr;
System.out.println(printTreeAsZ(root));
}
}
输出:[[1], [3, 2], [4, 5, 6, 7]]
60、把二叉树打印成多行
从上到下按层打印二叉树,同一层结点从左至右输出。每一层输出一行。
思路:利用辅助空间链表或队列来存储节点,每层输出。
import java.util.ArrayList;
import java.util.LinkedList;
class TreeNode{
int val;
TreeNode left;
TreeNode right;
TreeNode(int v){
val=v;
this.left=null;
this.right=null;
}
TreeNode(){}
}
public class Test {
/*一行输出的方法*/
public static ArrayList printTreeByLayer1(TreeNode root) {
ArrayList list=new ArrayList();
if(root==null)
return list;
LinkedList temp=new LinkedList();
temp.offer(root);
while(!temp.isEmpty()) {
TreeNode node=temp.poll();//poll()方法:得到这个序列的第一元素,并把这个元素从序列里删除
list.add(node.val);
if(node.left!=null)
temp.offer(node.left);
if(node.right!=null)
temp.offer(node.right);
}
return list;
}
/*多行输出的方法*/
public static void printTreeByLayer2(TreeNode root) {
if(root==null)
return ;
LinkedList temp=new LinkedList();
temp.offer(root);
TreeNode last=root;//初始化根节点为当前行最后一个节点
TreeNode nlast=new TreeNode();//下一行最后一个节点
while(!temp.isEmpty()) {
TreeNode curNode=temp.poll();//得到这个序列的第一元素,并把这个元素从序列里删除
System.out.print(curNode.val+" ");
if(curNode.left!=null) {
temp.offer(curNode.left);
nlast=curNode.left;
}
if(curNode.right!=null) {
temp.offer(curNode.right);
nlast=curNode.right;
}
if(curNode==last) {//当输出到本行的最后一个节点
System.out.println();//换行
last=nlast;//将下一行的最后一个节点付给当前行最后一个节点,并开始下一轮的循环
}
}
}
public static void main(String[] args) {
TreeNode root=new TreeNode(1);
TreeNode rl=new TreeNode(2);
TreeNode rr=new TreeNode(3);
TreeNode rll=new TreeNode(4);
TreeNode rlr=new TreeNode(5);
TreeNode rrl=new TreeNode(6);
TreeNode rrr=new TreeNode(7);
root.left=rl;
root.right=rr;
root.left.left=rll;
root.left.right=rlr;
root.right.left=rrl;
root.right.right=rrr;
System.out.println(printTreeByLayer1(root));
System.out.println();
printTreeByLayer2(root);
}
}
输出:
[1, 2, 3, 4, 5, 6, 7]
1
2 3
4 5 6 7
61、序列化二叉树
思路:
对于序列化:使用前序遍历,递归的将二叉树的值转化为字符,并且在每次二叉树的结点不为空时,在转化val所得的字符之后添加一个’,’作为分割; 对于空节点则以 ‘#,’ 代替。
对于反序列化:将字符串按照“,”进行分割,插入到队列中,然后依次从队列中取出字符建立节点,递归创建一个二叉树。
import java.util.LinkedList;
import java.util.Queue;
class TreeNode{
int val;
TreeNode left;
TreeNode right;
TreeNode(int v){
val=v;
this.left=null;
this.right=null;
}
TreeNode(){}
}
public class Test {
//序列化二叉树
public static String Serialize(TreeNode root) {
if(root==null)
return "#,";
StringBuffer res=new StringBuffer(root.val+",");
res.append(Serialize(root.left));
res.append(Serialize(root.right));
return res.toString();
}
//反序列化二叉树
public static TreeNode Deserialize(String str) {
String[] res=str.split(",");//将字符串按照“,”进行分割
Queue queue=new LinkedList();
for(String s:res) {
queue.offer(s);//插入到队列中
}
return pre(queue);
}
public static TreeNode pre(Queue queue) {
String val=queue.poll();//依次从队列中取出字符
if(val.equals("#"))//空节点
return null;
TreeNode node=new TreeNode(Integer.parseInt(val));//建立节点
node.left=pre(queue);//递归构造左孩子结点
node.right=pre(queue);//递归构造右孩子结点
return node;
}
//按层打印二叉树
public static void printTreeByLayer(TreeNode root) {
if(root==null)
return ;
LinkedList list=new LinkedList();
list.offer(root);
TreeNode curNode;
TreeNode last=root;
TreeNode nlast=new TreeNode();
while(!list.isEmpty()) {
curNode =list.poll();
System.out.print(curNode.val+" ");
if(curNode.left!=null) {
list.offer(curNode.left);
nlast=curNode.left;
}
if(curNode.right!=null) {
list.offer(curNode.right);
nlast=curNode.right;
}
if(curNode==last) {
System.out.println();
last=nlast;
}
}
}
public static void main(String[] args) {
TreeNode root=new TreeNode(1);
TreeNode rl=new TreeNode(2);
TreeNode rr=new TreeNode(3);
TreeNode rll=new TreeNode(4);
TreeNode rlr=new TreeNode(5);
TreeNode rrl=new TreeNode(6);
TreeNode rrr=new TreeNode(7);
root.left=rl;
root.right=rr;
root.left.left=rll;
root.left.right=rlr;
root.right.left=rrl;
root.right.right=rrr;
System.out.println("序列化二叉树:");
System.out.println(Serialize(root));
System.out.println("反序列化二叉树:");
TreeNode node=Deserialize(Serialize(root));
printTreeByLayer(node);
}
}
输出:
序列化二叉树:
1,2,4,#,#,5,#,#,3,6,#,#,7,#,#,
反序列化二叉树:
1
2 3
4 5 6 7
62、二叉搜索树的第K个节点
思路:二叉搜索树按照中序遍历的顺序打印出来正好就是排序好的顺序,第k个结点就是第K大的节点
方法一:递归
import java.util.ArrayList;
class TreeNode{
int val;
TreeNode left;
TreeNode right;
TreeNode(int v){
val=v;
this.left=null;
this.right=null;
}
TreeNode(){}
}
public class Test {
static ArrayList list=new ArrayList();
public static TreeNode KthNode(TreeNode root,int k) {
if(root==null||k==0)
return list;
inOrder(root);//中序遍历二叉树
if(k<=list.size()) {
return list.get(k-1);
}else {
return list;
}
}
//中序遍历
public static void inOrder(TreeNode root) {
if(root==null)
return;
if(root.left!=null)
inOrder(root.left);
list.add(root);
if(root.right!=null)
inOrder(root.right);
}
public static void main(String[] args) {
TreeNode root=new TreeNode(1);
TreeNode rl=new TreeNode(2);
TreeNode rr=new TreeNode(3);
TreeNode rll=new TreeNode(4);
TreeNode rlr=new TreeNode(5);
TreeNode rrl=new TreeNode(6);
TreeNode rrr=new TreeNode(7);
root.left=rl;
root.right=rr;
root.left.left=rll;
root.left.right=rlr;
root.right.left=rrl;
root.right.right=rrr;
System.out.println(KthNode(root,3).val);
}
}
输出:5
方法二:非递归借用栈的方式查找,当count=k时返回节点
import java.util.Stack;
class TreeNode{
int val;
TreeNode left;
TreeNode right;
TreeNode(int v){
val=v;
this.left=null;
this.right=null;
}
TreeNode(){}
}
public class Test {
static int count=0;
public static TreeNode KthNode(TreeNode root,int k) {
if(root==null||count>k)
return null;
Stack stack=new Stack();
TreeNode p=root;
TreeNode kthNode=null;
while(p!=null||!stack.isEmpty()) {
while(p!=null) {
stack.push(p);
p=p.left;
}
TreeNode node=stack.pop();
count++;
if(count==k) {
kthNode=node;
break;
}
p=node.right;
}
return kthNode;
}
public static void main(String[] args) {
TreeNode root=new TreeNode(1);
TreeNode rl=new TreeNode(2);
TreeNode rr=new TreeNode(3);
TreeNode rll=new TreeNode(4);
TreeNode rlr=new TreeNode(5);
TreeNode rrl=new TreeNode(6);
TreeNode rrr=new TreeNode(7);
root.left=rl;
root.right=rr;
root.left.left=rll;
root.left.right=rlr;
root.right.left=rrl;
root.right.right=rrr;
System.out.println(KthNode(root,3).val);
}
}
输出:5
63、数据流中的中位数
思路:用两个堆保存数据,保持两个堆的数据保持平衡(元素个数相差不超过1)。大顶堆存放的数据要比小顶堆的数据小。当两个堆中元素为偶数个,将新加入元素加入到大顶堆,如果要加入的数据,比小顶堆的最小元素大,先将该元素插入小顶堆,然后将小顶堆的最小元素插入到大顶堆。当两个堆中元素为奇数个,将新加入元素加入到小顶堆,如果要加入的数据,比大顶堆的最大元素小,先将该元素插入大顶堆,然后将大顶堆的最大元素插入到小顶堆。
当元素个数是奇数个时,大顶堆元素比小顶堆多一个,中位数即为大顶堆的堆顶元素。
若为偶数,则中位数是大小顶堆的堆顶元素之和除以2。
方法一:用TreeSet实现大小顶堆
import java.util.TreeSet;
public class Test {
static TreeSet min=new TreeSet();//小顶堆,用于存放后面一半的元素
static TreeSet max=new TreeSet();//大顶堆,用于存放前面一半的元素
public static void insert(int num) {
if(((max.size()+min.size())&1)==0) {//当前有偶数个元素
if(min.size()>0&&num>min.first()) {//如果插入的元素比小顶堆中最小元素还大
min.add(num);//将新元素加入小顶堆
num=min.first();//取出小顶堆中的最小元素
min.remove(num);//删除小顶堆中最小元素
}
max.add(num);//将小顶堆中最小元素加到大顶堆中
}else {//当前有奇数个元素
if(max.size()>0&&num 输出 :4.0
方法二:用优先队列实现大小顶堆
import java.util.Comparator;
import java.util.PriorityQueue;
public class Test {
static int count=0;
static PriorityQueue min=new PriorityQueue<>();//小顶堆
static PriorityQueue max=new PriorityQueue<>(new Comparator() {//大顶堆实现Comparator,重写排序
public int compare(Integer o1,Integer o2) {
return o2.compareTo(o1);
}
});
public static void insert(int num) {
count++;
if((count & 1)==1) {//奇数个
min.offer(num);
max.offer(min.poll());//将小顶堆第一个元素(最小元素)加到大顶堆中,并从小顶堆中删除
}else {//偶数个
max.offer(num);
min.offer(max.poll());//将大顶堆第一个元素(最大元素)加到小顶堆中,并从大顶堆中删除
}
}
public static double getMedium() {
if (count == 0)
return 0.0;
// 当元素个数是奇数时,中位数就是大根堆的顶点
if ((count & 1) == 1) {
return Double.valueOf(max.peek());
} else {
return Double.valueOf((min.peek() + max.peek())) / 2;
}
}
public static void main(String[] args) {
insert(3);
insert(2);
insert(7);
insert(5);
insert(6);
insert(1);
insert(4);
System.out.println(getMedium());
}
}
输出:4.0
64、滑动窗口的最大值
方法一:两个for循环,第一个for循环滑动窗口,第二个for循环滑动窗口中的值,寻找最大值。效率不高!
import java.util.ArrayList;
public class Test {
public static ArrayList maxInWindows(int[] num,int size){
ArrayList list=new ArrayList();
if(num==null||num.lengthmax) {
max=num[j];//替换最大值
}
}
list.add(max);
}
return list;
}
public static void main(String[] args) {
int[] num= {3,2,1,5,6,8,7,4};
ArrayList list=maxInWindows(num,3);
for(int i:list) {
System.out.print(i+" ");
}
}
}
输出:3 5 6 8 8 8
方法二:
借助一个辅助队列,从头遍历数组,根据如下规则进行入队列或出队列操作:
- 如果队列为空,则当前数字入队列
- 如果当前数字大于队列尾,则删除队列尾,直到当前数字小于等于队列尾,或者队列空,然后当前数字入队列
- 如果当前数字小于队列尾,则当前数字入队列
- 如果队列头超出滑动窗口范围,则删除队列头
这样能始终保证队列头为当前的最大值
import java.util.ArrayList;
import java.util.LinkedList;
public class Test {
public static ArrayList maxInWindows(int[] num,int size){
ArrayList res=new ArrayList();
if(num==null||num.length==0||size==0||size>num.length)
return res;
LinkedList queue=new LinkedList<>();//队列中存储数组的下标而非数值
for(int i=0;i=queue.peek()+size) {//如果队列头元素不在滑动窗口中了,就删除头元素
queue.pop();
}
while(!queue.isEmpty()&&(num[i]>=num[queue.getLast()])) {//如果当前数字大于队列尾,则删除队列尾,直到当前数字小于等于队列尾,或者队列空
queue.removeLast();
}
}
queue.offer(i);// 入队列
if(i+1>=size) { //滑动窗口经过size个元素,获取当前的最大值,也就是队列的头元素
res.add(num[queue.peek()]);
}
}
return res;
}
public static void main(String[] args) {
int[] num= {3,2,1,5,6,8,7,4};
ArrayList list=maxInWindows(num,3);
for(int i:list) {
System.out.print(i+" ");
}
}
}
输出:3 5 6 8 8 8
65、矩阵中的路径
说明:设计一个函数,用来判断在一个矩阵中是否存在一条包含某字符串所有字符的路径。路径可以从矩阵中的任意一个格子开始,每一步可以在矩阵中向左,向右,向上,向下移动一个格子。如果一条路径经过了矩阵中的某一个格子,则该路径不能再进入该格子。
首先对所整个矩阵遍历,找到第一个字符,然后向上下左右查找下一个字符,由于每个字符都是相同的判断方法(先判断当前字符是否相等,再向四周查找),因此采用递归函数。由于字符查找过后不能重复进入,所以还要定义一个与字符矩阵大小相同的布尔值矩阵,进入过的格子标记为true。如果不满足的情况下,需要进行回溯,此时,要将当前位置的布尔值标记回false。(所谓的回溯无非就是对使用过的字符进行标记和处理后的去标记)
public class Test {
public static boolean hasPath(char[] num,int rows,int cols,char[] str) {
boolean[] isVisited=new boolean[num.length];//定义一个数组大小的标记数组,用于标记哪些位置已经被走过
//首先对所整个矩阵遍历,直到找到第一个(和字符串首元素相等的)字符
for(int i=0;i=rows||j<0||j>=cols||num[index]!=str[pathLen]||isVisited[index]==true) {
return false;
}
if(pathLen==str.length-1) {//如果遍历到字符串最后一个字符且二者值相等,则有路径
return true;
}
isVisited[index]=true;//找到矩阵中第一个字符
//然后向上下左右查找下一个字符,由于每个字符都是相同的判断方法(先判断当前字符是否相等,再向四周查找),因此采用递归函数
if(search(num,rows,cols,i,j-1,str,pathLen+1,isVisited)
||search(num,rows,cols,i,j+1,str,pathLen+1,isVisited)
||search(num,rows,cols,i-1,j,str,pathLen+1,isVisited)
||search(num,rows,cols,i+1,j,str,pathLen+1,isVisited)) {
return true;
}
isVisited[index]=false;//若当前元素不满足要求,则回溯,令标记为false
return false;
}
public static void main(String[] args) {
char[] num="ABCDEFGHIJKLMNOP".toCharArray();
int rows=4;
int cols=4;
char[] str="FGKOP".toCharArray();
if(hasPath(num,rows,cols,str)) {
System.out.println("有路径!");
}else {
System.out.println("没有路径!");
}
}
}
输出:有路径!
66、机器人的运动范围
题目:地上有一个m行和n列的方格。一个机器人从坐标0,0的格子开始移动,每一次只能向左,右,上,下四个方向移动一格,但是不能进入行坐标和列坐标的数位之和大于k的格子。 例如,当k为18时,机器人能够进入方格(35,37),因为3+5+3+7 = 18。但是,它不能进入方格(35,38),因为3+5+3+8 = 19。请问该机器人能够达到多少个格子?
思路:本题使用的方法同样还是回溯法,另外还需要会计算给定整数上的各个位上数之和。
使用一个访问数组记录是否已经经过该格子。
机器人从(0,0)开始移动,当它准备进入(i,j)的格子时,通过检查坐标的数位来判断机器人是否能够进入。
如果机器人能进入(i,j)的格子,接着在判断它是否能进入四个相邻的格子(i,j-1),(i,j+1),(i-1,j),(i+1,j)。
因此,可以用回溯法来解决这一问题。
public class Test {
public static int walkSteps(int threshold,int rows,int cols) {
if(rows<=0||cols<=0||threshold<0) return 0;
boolean[] isVisited=new boolean[rows*cols];//标记是否为走过格子的矩阵
for (int i = 0; i < isVisited.length; i++) {
isVisited[i] = false;//变量初始化
}
return search(0,0,threshold,rows,cols,isVisited);
}
public static int search(int i,int j,int threshold,int rows,int cols,boolean[] isVisited) {
//如果访问的位置越界,或者方访问位置的各数位和大于门限值,或者访问的位置已经被访问过了
if (i<0||i>=rows||j<0||j>=cols||numSum(i)+numSum(j)>threshold||isVisited[i*cols+j] == true)//无法进入
return 0;
isVisited[i*cols+j]=true;//如果当前访问的位置有效(能进入),则标记为true
return 1+search(i-1,j,rows,cols,threshold,isVisited)//当前位置向上遍历
+search(i+1,j,rows,cols,threshold,isVisited)//当前位置向下遍历
+search(i,j-1,rows,cols,threshold,isVisited)//当前位置向左遍历
+search(i,j+1,rows,cols,threshold,isVisited);//当前位置向右遍历
}
public static int numSum(int number) {
int sum=0;
while(number>0) {
sum+=number%10;//从低位开始逐个与10做模运算,目的是为了按位取数再作和
number/=10;
}
return sum;//各数位的和
}
public static void main(String[] args) {
System.out.println(walkSteps(3,5,5));
}
}
输出:12
67、二叉搜索树的后序遍历序列
题目:
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果。如果是则返回true。否则返回false。假设输入的数组的任意两个数字都互不相同。
思路:
例如输入数组{5, 7, 6, 9, 11, 10, 8},则返回true,因为这个整数序列是上图二叉搜索树的后序遍历结果。如果输入的数组是{7, 4, 6, 5},由于没有哪颗二叉搜索树的后序遍历的结果是这个序列,因此返回false。
在后序遍历得到的序列中,最后一个数字是树的根结点的值。数组中前面的数字可以分为两部分:第一部分是左子树结点的值,它们都比根结点的值小;第二部分是右子树结点的值,它们都比根结点的值大。
以数组{5, 7, 6, 9, 11, 10, 8}为例,后序遍历的结果中最后一个值8就是根结点,在这个数组中前3个数字5,7, 6都比8小是根结点8的左子树结点;后3个数字9, 11, 10都比8大,是根结点8的右子树结点。
接下来用同样的方法确定与数组每一部分对应的子树的结构。这其实就是一个递归的过程。对于序列5, 7, 6的子树而言,6是根结点,5是根结点6的左子结点,7是根结点6的右子结点;同样对于序列9, 11, 10的子树而言,10是根结点,9是根结点10的左子结点,11是根结点10的右子结点。
以数组{7, 4, 6, 5}为例,后序遍历的结果中最后一个值5就是根结点。数组的第一个数字7大于5,故此二叉搜索树没有左子树, 7, 4, 6都是右子树结点的值。我们发现4比5小,违背了二叉搜索树的规定。故此数组不是二叉搜索树的后序遍历。
class TreeNode{
int val;
TreeNode left;
TreeNode right;
TreeNode(int val){
this.val=val;
}
TreeNode(){}
}
public class Test {
public static boolean verifySeqOfBST(int[] sequence) {
if(sequence==null||sequence.length<=0)
return false;
return verifyCore(sequence,0,sequence.length-1);
}
public static boolean verifyCore(int[] sequence,int start,int end) {
if(start>=end)
return true;
int root=sequence[end];
int i=0;
for(;iroot) {
break;
}
}
int j=i;
for(;jstart) {
left=verifyCore(sequence,start,i-1);
}
boolean right=true;
if(i 输出:true